I try to experience with concurrent data transfer and computation on Fermi.
This is a very simple test, extracted from the NVIDIA CUDA Programming guide,
[codebox]#include <cutil_inline.h>
global void MyKernel(float* d_o,float* d_i, int size)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size)
{
d_o[idx] = d_i[idx] + 1;
}
}
int main(int argc, char** argv)
{
const int nS = 4;
cudaStream_t stream[nS];
int size = 65000 * 512;
for (int i = 0; i < nS; ++i)
cudaStreamCreate(&stream[i]);
float* hostPtr;
cudaMallocHost(&hostPtr, nS * size * sizeof(float));
float* inputDevPtr;
float* outputDevPtr;
cudaMalloc((void**)&inputDevPtr, nS * size * sizeof(float));
cudaMalloc((void**)&outputDevPtr, nS * size * sizeof(float));
for (int i = 0; i < nS; ++i)
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size * sizeof(float), cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < nS; ++i)
MyKernel<<<65000, 512, 0, stream[i]>>> (outputDevPtr + i * size, inputDevPtr + i * size, size);
for (int i = 0; i < nS; ++i)
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size * sizeof(float), cudaMemcpyDeviceToHost, stream[i]);
cudaThreadSynchronize();
cudaThreadExit();
cutilExit(argc, argv);
}
[/codebox]
I use GPU TIme width plot to display the execution of the kernel.
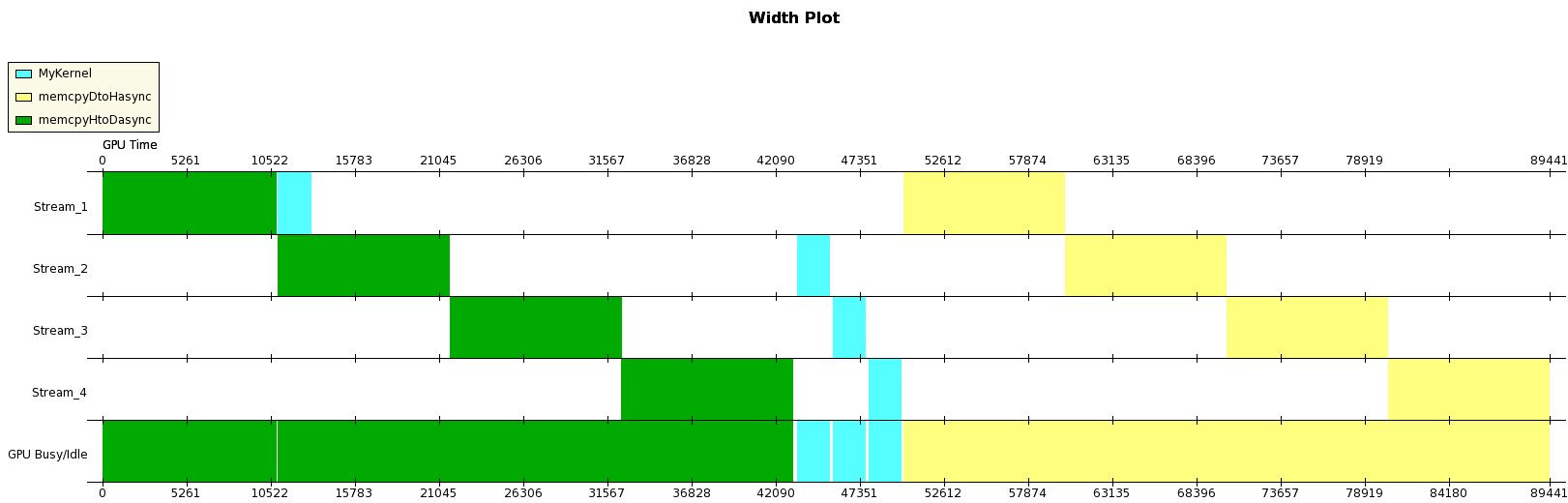
As we can see only the first stream kernel overlap with second stream data copy from Host to Device. And there are no overlap between other kernel with memory copy from Host to Device and Device To Host.
I can not understand why it happen. Could someone shed a light on the problem ?
And then my question is :
[*] How to achieve the concurrency, what is the requirement that the code should obey.
[*] How to manage CUDA scheduler, it is seems obvious to me that the kernel on the second stream could execute right a way after its input data available, while the scheduler forces its execution delay until all data available
[*] Is the GTX 480 incapable of overlapping Host to Device and Device To Host memory copy. It would be great since it almost doubles speed and increases PCIe bus usage.
Thank you for your help