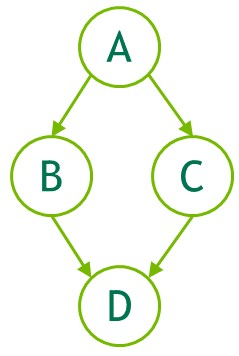
Kernel A does some work and, based on the results, I want the graph to execute Kernel B or Kernel C. In either case, there is a “finalize” kernel D.
One type of scenario - packet of data comes in (say 60MB every 200ms). My code does a dev-to-dev memcopy of the data into the graph’s shared memory. I then kick-off the graph execution.
I did think of this, but I was hoping not to have that logic within the kernels but keep it in the encapsulating graph logic or at least in some code at the end of the kernel that could tell the graph which node to run next.
It seems to me, however, that every node in the graph will be executed; if there was an additional node between B and D (say B2), then after directly exiting B (because if var is false), then B2 would be ran as well…
I would want that entire B Branch (sub-tree) to not be traversed.
{kind=link}