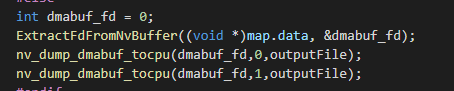
And I get get valid data after set nvvidconv’s “bl-output” to false,but it‘s framerate’ will drop down after set it.
It’s there a way to do “bl-output” for a single NVMM-buffer(NV12) which was been appsink received by appsink?
Hello DaneLL
In 4000*3000 resolution,It can get yuv file with set “bl-output” to false.But the framerate will dropout over set it(using NVMM).Setting this parameter seems to cause a CPU memory copy.
However, if I do not set the parameter “BL-output”, I cannot get the normal YUV.
Is there a way to get normal NV12 data from NVMM without droping down the frame rate.
Hi,
It looks expected. For dumping YUV data, you would need to set bl-output=0 to get data in pitch linear.
There is blocklinear to pitchlinear conversion on hardware converter. The resolution is high so please run VIC at mas clock: Nvvideoconvert issue, nvvideoconvert in DS4 is better than Ds5? - #3 by DaneLLL
And also CPU cores at max clock sine you write data to storage. If it still cannot achieve performance requirement, it is vary likely to hit performance constraint. Suggest you not to write every frame to storage. The optimal performance is to keep data in NVMM buffer from source to sink, without writing to another CPU buffer or storage.
Hi,
From your description the performance bottleneck looks to be in hardware converter. Without setting bl-output, it does not call NvBufferTransform() in nvvidconv plugin and pass the buffer to next element directly. If you see performance drop, it means the NvBufferTransform() call caps the performance. The maximum throughput is to disable DFS so that VIC engine can be always in max clock.
The nvvidconv plugin is open source from Jetpack 4.5. Although you use previous version, you may download the source code and take a look.
Hello,DaneLLL
I have a new idea.
(1).If I do not convert NVMM-Buffer to CPU-memory within appsink’s callback,Instead I convert it to a new NVMM memory.
(2).Then the NVMM-buffer will been converted to yuv in a separate pipeline which does not involve capture
Does this approach work?Is yuV conversion of copied NVMMBuffers affected by NvBufferTransform()?
Please modify NvBufferLayout_BlockLinear to NvBufferLayout_Pitch so that you don’t need to link to nvvidconv plugin for converting to pitch-linear buffer.
Hell,DaneLLL
I had solved the problem through your suggestion,but now a new problem has arisen.
The nvjpegenc was work well when nvarguscamerasrc’s layout was NvBufferLayout_BlockLinear,and it get Segment Fault after nvarguscamerasrc’s layout was change to NvBufferLayout_Pitch.
The test commands are as follows: