Hi,
I call the kernel function with kernelfun<<<102400,1024>>>, it simply skiped it and does not run call the kernel function,
Then I divided my task into 1024 parts, for each parts there is only <<<100,1024>>>, then it works well.
However I uses deviceQuery to check my GPUs.
There are two GPUs in the desktop, one GTX780 and one GT610, and I uses GT610 for display.
For GTX780, the maximum grid size is <2147483647,65535,65535>.
For GT610, the maximum grid size is <65535,65535,65535>.
However it should automatically choose GT780 to run the program, so there should be no problem for runing with more than 65535 blocks.
I forget how NVIDIA decides on device ordering, but it is definitely not automatic – I believe it chooses device 0 on your machine unless you explicitely tell it to otherwise. You have a few options:
I’m working with CUDA+VS2012. How to set this option?
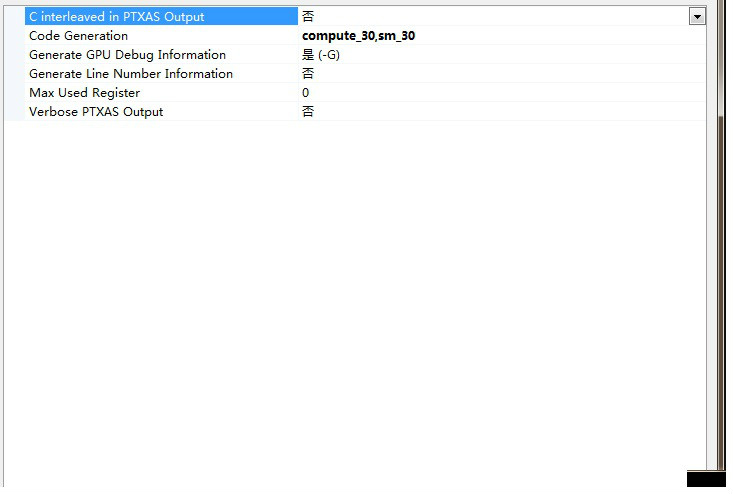
I’ve found that in poject property → CUDA C/C++ → Device → Code Generation, it is compute_10,sm_10 as default, there is no other selection. I typed compute_30,sm_35 into it. But it still does not work.
I checked from the project property → CUDA C/C++ → Command Line, and I don’t find any terms like -arch=sm_30, is there anything I should do to apply the setting sm_35?
After I apply those seetings, I can’t find anything change in CUDA C/C++ → Command Line. Does those setting work?
When I click on the triangle on the right side of the blank, there is not selections like compute_** or sm_**, I have to type it manully into the blank. Is there any problem?
When you say ‘not work’ do you mean you can’t run more than say kernelfun<<<65535,1024>>> elements? It may also be that you are exceeding some other GPU resource that is not launch bounds.
Also look in the build output after you compile to see if the -gencode=arch=compute_30,code="sm_30,compute_30" is being sent to NVCC, it will not show up in the project command line settings.