Description
I am working on deploy models on TX2
The model is ok on desktop.
On TX2, If the engine is builded without EXPLICIT_BATCH, everything is still fine. But if I build engine with EXPLICIT_BATCH, Inference is much slower than pytorch.
I have add some IPluginV2DynamicExt in my model, If I can’t use explicit batch, all these plugins have to be rewrited.
Is it possible to speed up the engine?
Environment
TensorRT Version: 6.0.1
GPU Type: Jetson TX2
Nvidia Driver Version:
CUDA Version: 10.0
CUDNN Version:
Operating System + Version: Ubuntu 18.04
Python Version (if applicable): 3.6.9
TensorFlow Version (if applicable):
PyTorch Version (if applicable): 1.1
Baremetal or Container (if container which image + tag):
Steps To Reproduce
Hi,
Explicit batch is required when you are dealing with Dynamic shapes, otherwise network will be created using implicit batch dimension.
To speed up the engine, you can specify the optimization profiles. Please refer to below link for more details:
https://github.com/NVIDIA/TensorRT/tree/master/samples/opensource/sampleDynamicReshape
Thanks
thanks for reply.
I have already add the profiles, still slow. Fix the input shape not working too.
for resnet18, pytorch 0.018ms vs trt 0.23ms
My model is an end2end faster-rcnn, The input batch size is 1, After roi pooling, there are 1000 features feed to rcnn. The batch size has changed. That’s why I use explicit batch. How can I make it work in implicit batch?
Hi,
Can you share the model file and script to reproduce the issue so that we can better help?
Meanwhile, you can use Nvidia profiler to identify/debug the issue in the code/model flow:
Thanks
Hi,
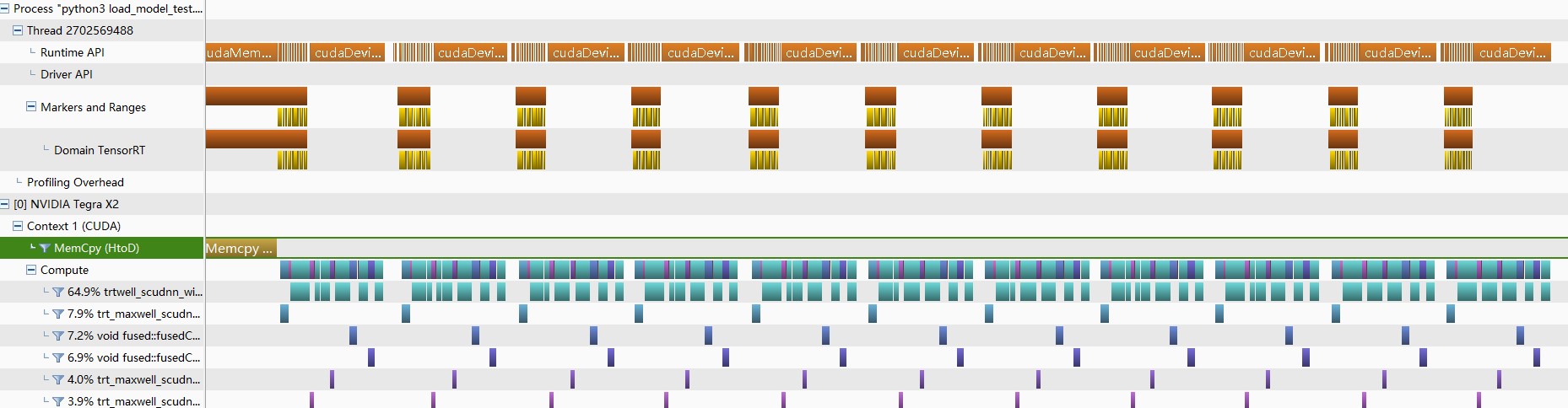
I think I found something related.
I use the nvprof follow your advice, and found some HtoD memcpy while trt inference, guess that’s sychronize the stream.
But i still have no idea why this happened.
explicit batch
implicit batch
Hi,
I try to run your code on my machine v100 system with TRT 7 and got following result:
model test
pytorch take time: 0.0034534454345703123
trt take time: 0.0007956743240356446
I even checked the code that you shared, it user torch2trt but not able to find explicit and implicit case. Could you please share the script/steps to reproduce both the cases?
Thanks