Dear sir/madam:
When I inference on a deep learning model (slowfast model), I’m facing a problem that my python program seems to take more inference time in cuda env compared to cpu. It’s not the whole model but one specific layer takes more time on cuda env than cpu. I’m so confused that hope someone can help me with it. Here is the details.
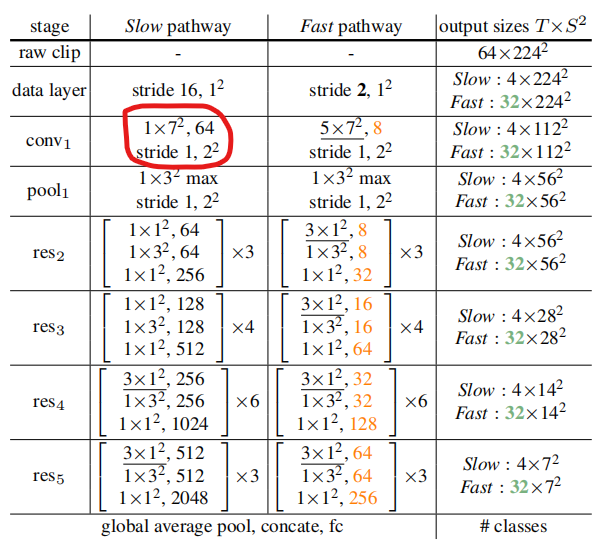
the specific layer is “slowway-conv1” layer as showned in the pic below representing the model structure of slowfast.
And my confusing result is as follows.
In cuda env, I found the processing time of “conv1” (0.97s) accounts for a great proportion of the processing time of the whole model (1.04s), while in cpu env, the processing time of “conv1” (0.07s) only accounts for a very small proportion of the processing time of the whole model (4.43s). And I reckon that the proportion in cpu env is reasonable considering the calculation budget.
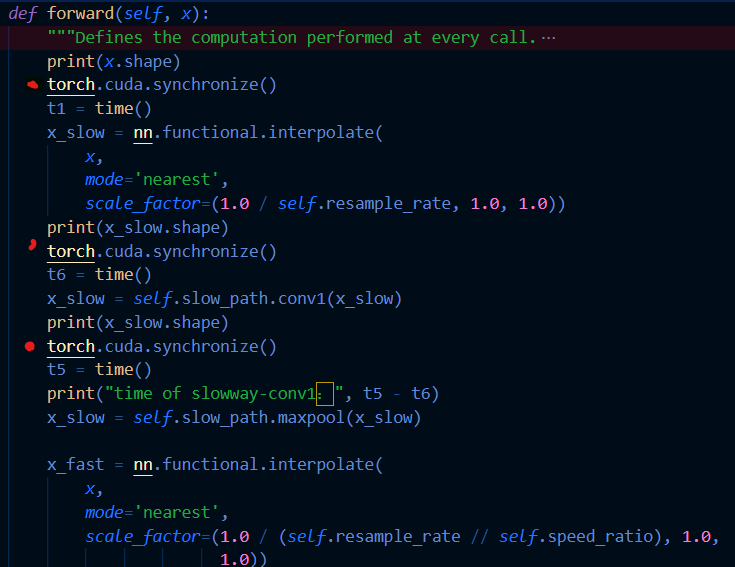
Is my method of time measurement mistaken? I used two python functions. one is time.time() and the other is torch.cuda.synchronize()(before “time.time()”)
Due to my newly coming, I can only put one pic in my topic…
If it’s my fault that causing the confusing result, please kindly point out, or please give me some ideas to help me solve this problem. Thank you very much!
Yours, Koala
Thank you for your kindly reply. I put the screen shot of the result and the code I used below, could you please check it?
It’s cuda’s result.
(As I’m a new user, I can only put one media at a time)
If there’s any problem with my method of measuring time, please kindly point out~
As you may notice, slowfast model has two pathway (slow pathway and fast pathway) which means it have two conv1 layer, two pooling layer and two res50 module, and what I’m testing is “conv1” layer for slow pathway, which may lead to its small proportion of processing time.
By visual inspection: There are print statements between times t1 and t2 and also between t5 and t6, so they are included in the timed portions of the code. It would be best to comment those out , i.e. avoid I/O.
@njuffa I’m so sorry to misunderstand you. My view that print() function only takes very little time made me ignore your suggestions.
following your advice, I’ve removed the print() function inside the timing module, and here’s the result.
cpu result
But it seems that there’s no significant difference compared to previous result. Could you give me further guidance, please. Thank you very much!!