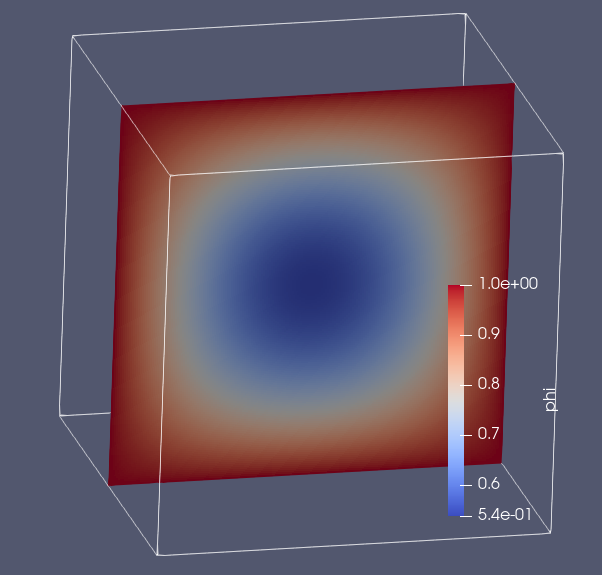
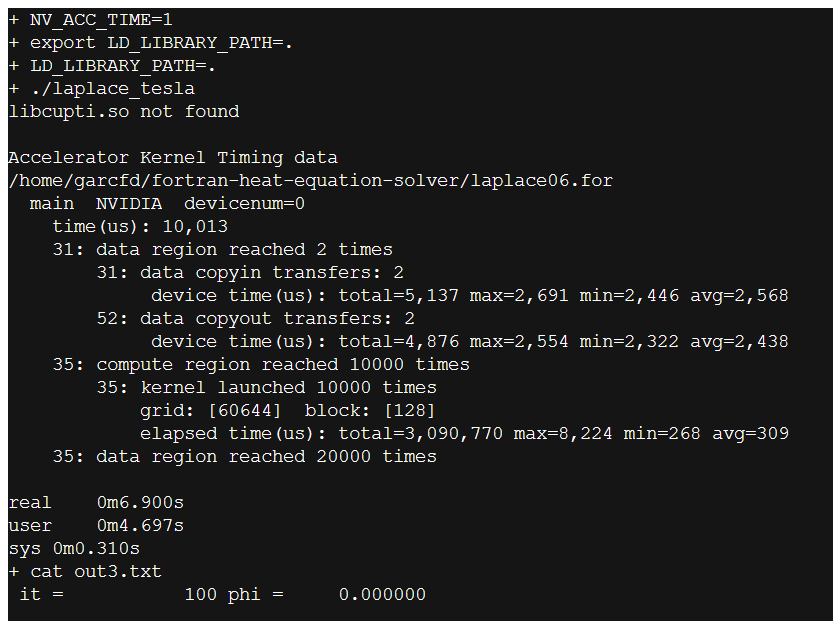
Im trying to get some speedup using a GPU by compiling my demo code (below):
pgf77 -static-nvidia -acc -gpu=cc75 -o laplace_tesla laplace05.for
…since im running it on a tesla T4.
I have tried all sorts of !$acc commands but nothing seems to give any GPU speedup. The serial demo code runs in 30sec, and in parallel (multicore mode) it shows good speedup, much the same as OpenMP, so with ACC_NUM_CORES=2 its twice as fast. But in GPU mode its taking abut 18sec, so a bit faster than serial, but slower than multicore. So can anyone suggest how to optimise the ACC commands, or do I need to learn CUDA? (also note here imm=jmm=kmm=200, so its an 8 million cell grid effectively)
onesixth = 1.0/6.0
do it = 1, nits
!$acc parallel loop collapse(3)
do k = 2, kmm
do j = 2, jmm
do i = 2, imm
phi(i,j,k) = ( phi(i-1,j,k) + phi(i+1,j,k)
& + phi(i,j-1,k) + phi(i,j+1,k)
& + phi(i,j,k-1) + phi(i,j,k+1) )*onesixth
enddo
enddo
enddo
enddo