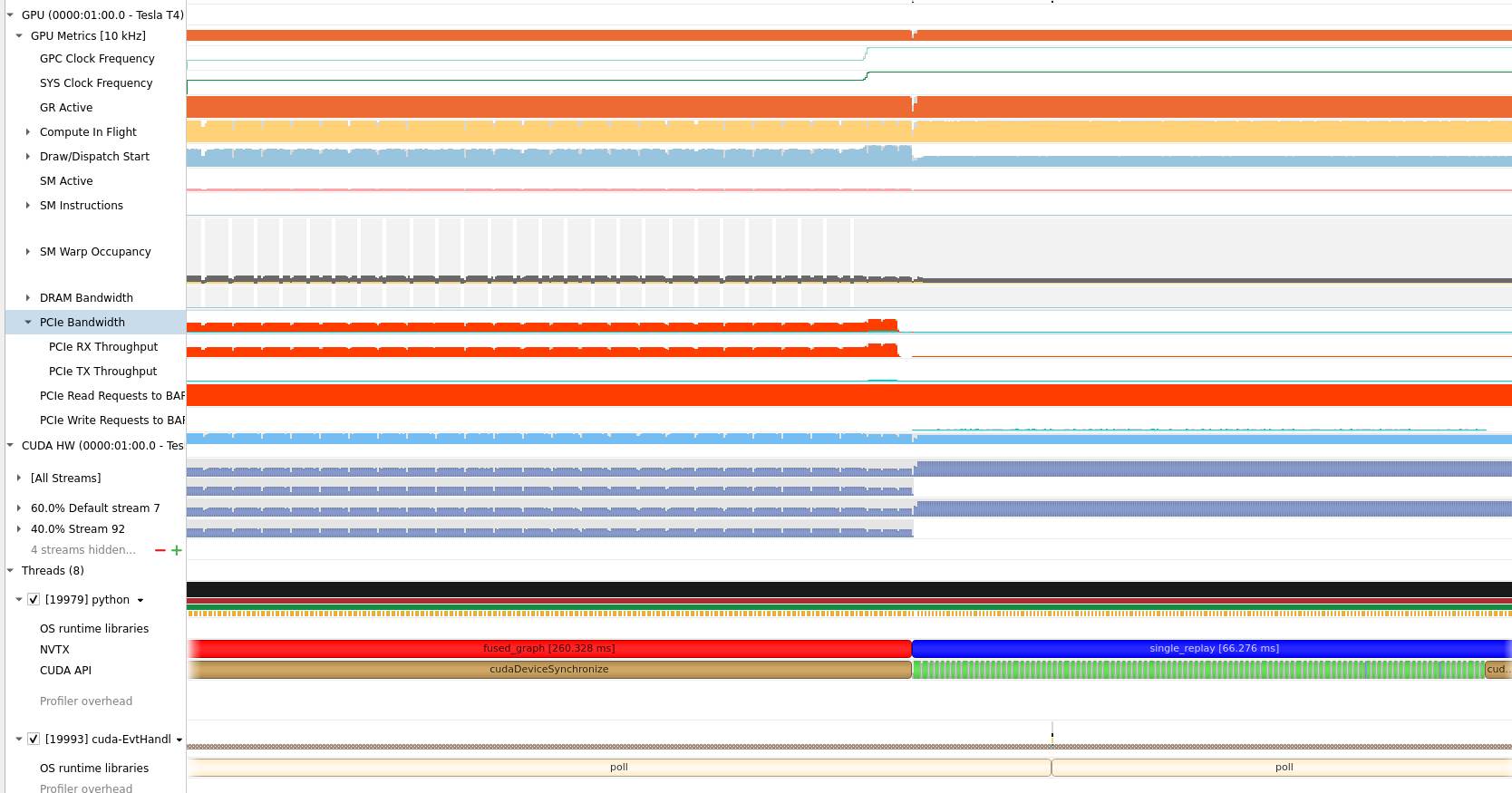
when I launched a manually designed CUDAGraph which is composed of two branches (streams), PCIe RX throughput rising so quickly compared to that only included single stream. I was confused …
By the way, what does metrics PCIe Read Requests to BAF mean and how can I verify which system factors have an effect on PCIe Bandwidth
@user122022 Could you share the report file for us to take a closer look?
Regarding to PCIe Read Request to BAF, the name is actually PCIe Read Requests to BAR1, and if you hover over the name, you can see the description CPU+Peer Reads from VRAM over PCIe