• Hardware Platform (Jetson / GPU) GPU • DeepStream Version 6.0 • TensorRT Version 7.2.2 • NVIDIA GPU Driver Version (valid for GPU only) 460.84 • Issue Type( questions, new requirements, bugs) question
We are using deepstream triton docker 6.0 for the experiment.
We used deepstream_ssd_parser.py to run yolov4 in TensorRT format with Nvinfer and Nvinferserver element and measure the performance difference.
The result shows that Nvinferserver is almost 2x slower than Nvinferser. Is this result reasonable?
I’m having the same problem (to clarify I’m using remote Triton via gRPC). While nvinfer is able to achieve about 860 infer/sec, nvinferserver with the same model only gets about 120 infer/sec.
Benchmarking Triton with perf_analyzer is able to achieve 860 infer/sec as well (concurrency level 5, CUDA shared memory, gRPC) so I know that Triton is not the bottleneck.
I was expecting nvinferserver to use CUDA shared memory while using remote Triton but that does not seem to be the case as Triton is not showing any registered CUDA memory regions while my pipeline is running.
@mchi can you clarify this? Also, is it possible to make nvinferserver use shared memory?
Hi @yamiefun ,
Sorry for long delay!
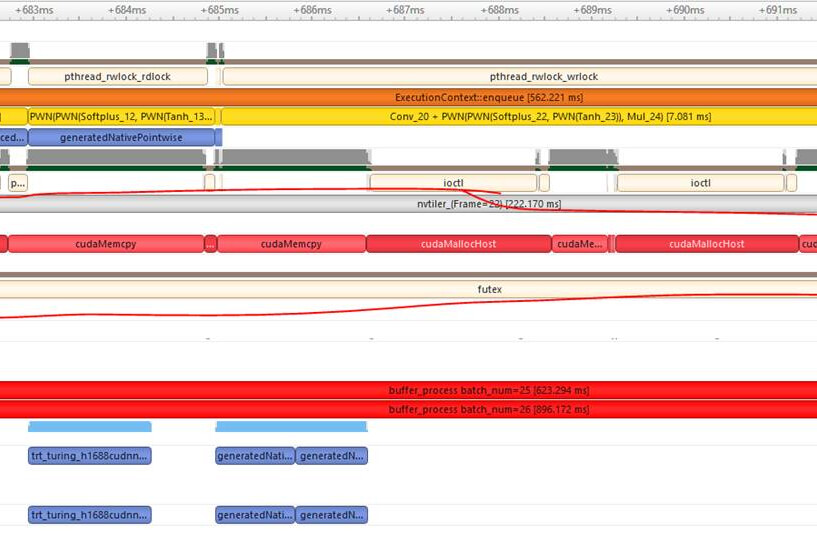
I can reproduce this issue on my side on Tesla T4. In my repo, the every TensorRT inference time on nvinferserver is much longer than that in nvinfer, and looks the longer TensorRT inference time on nvinferserver is caused by continuous cudaMallocHost(), cudaMemcpy()… on queue2:src thread as nsys log as below.
So, can you capture the nsight systems log with steps belowso that we can align our issue?
1. Download and install nsight systems from https://developer.nvidia.com/nsight-systems
2. run "nsys profile .." like below to capture the log
# nsys profile -t cuda,nvtx,osrt --show-output=true --force-overwrite=true --delay=5 --duration=90 --output=%p $APP
// change the delay and duration in "--delay=5 --duration=90"
e.g.
# nsys profile -t cuda,nvtx,osrt --show-output=true --force-overwrite=true --delay=5 --duration=90 --output=%p python3 deepstream_test_3.py file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_720p.h264