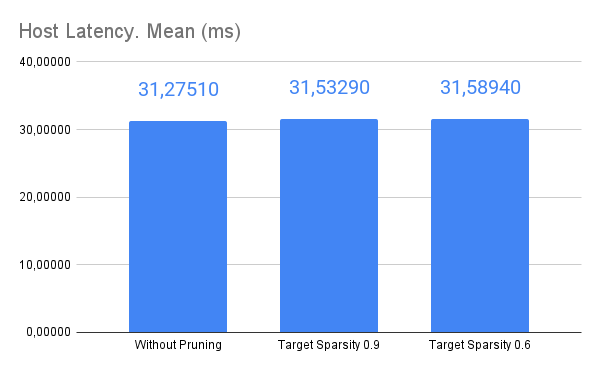
I have trained a model with and without doing pruning, with a target sparsity of 0.6 and 0.9.
After that, I have used trtexec to make the inference on Xavier with JetPack 4.5.1. Is it normal that the values of energy and time, are almost the same with and without pruning?
I include two graphs, one for time and one for energy.
For example, if you pruning a convolution kernel with half value into zero.
Since GPU is SIMD, the convolution is calculated in parallel.
It won’t be too much different if some of the value is zero.