A new article was created to continue the question here.
When I run mnist.onnx in sampleOnnxMNIST tensorrt sample as a model, I get the following error.
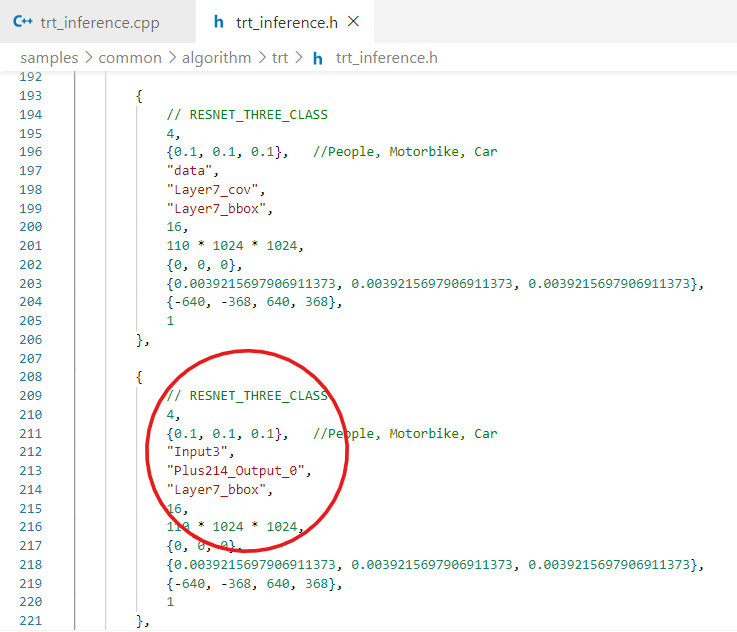
If you look at trt_inference.h
In the TRT_Context class
as a private member variable int num_bindings; Is declared.
Can you tell me what this variable means?
I don’t know what num_bindings mean here. sudo ./video_dec_trt 1 …/…/data/Video/sample_outdoor_car_1080p_10fps.h264 H264 --trt-onnxmodel …/…/data/Model/resnet10/mnist.onnx --trt-mode 0 set onnx modefile: …/…/data/Model/resnet10/mnist.onnx mode has been set to 0(using fp16) ---------------------------------------------------------------- Input filename: …/…/data/Model/resnet10/mnist.onnx ONNX IR version: 0.0.3 Opset version: 8 Producer name: CNTK Producer version: 2.5.1 Domain: ai.cntk Model version: 1
**Doc string: ** ----------------------------------------------------------------
onnx2trt_utils.cpp:220: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
Create TRT model cache
video_dec_trt: trt_inference.cpp:311: void TRT_Context::allocateMemory(bool): Assertion `cuda_engine.getNbBindings() == num_bindings’ failed.
Aborted
num_bindings indicates the number of buffers sending to the TensorRT.
Usually, it consists of multiple input layers and multiple output layers.
For example, if you have one input layer(input) and two output layers(bbox & coverage), then the num_bindings should be 3.
Guess that you only have one input layer and one output layer.
So you will need to change the parameter into 2 to align your model.
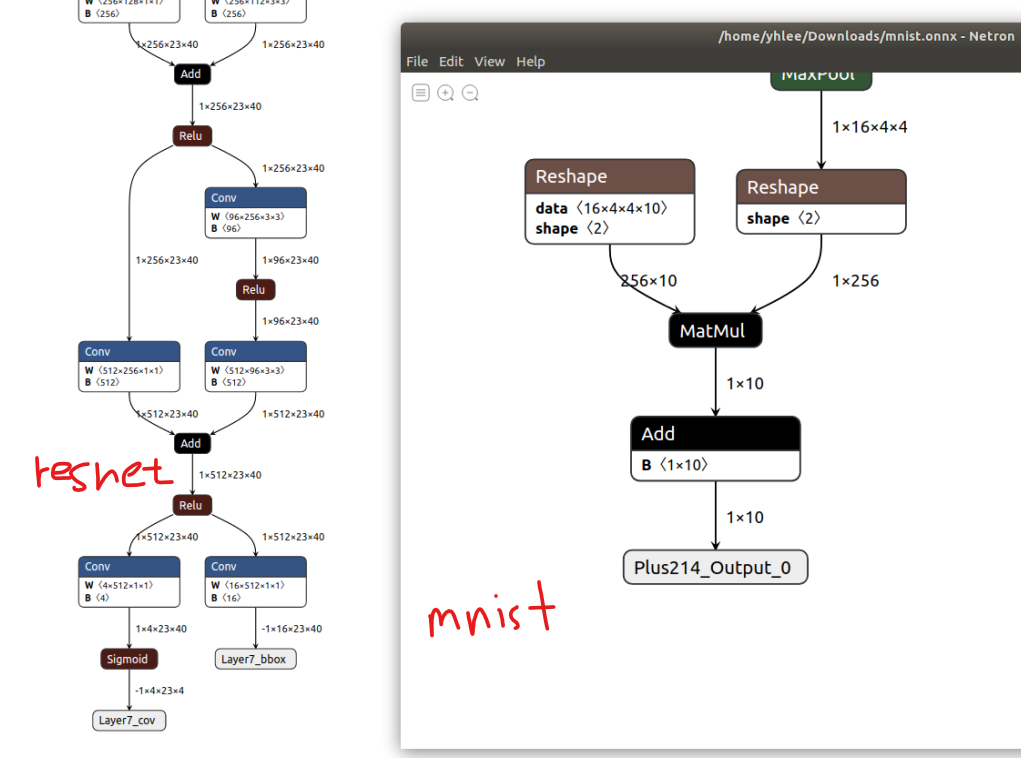
In the figure above, the left is a resnet model with conv and bbox outputs provided by 04 sample.
On the right is a mnist model with one output in the data directory of /usr/src/tensorrt.
Because there is no output
Commenting out all the parts corresponding to outputIndexBBOX in trt_inference.cpp, compiling, and running it with the mnist.onnx model as input, the following error appears.
In the figure below, the left is a resnet model with conv and bbox outputs provided by 04 sample.
On the right is a mnist model with one output in the data directory of /usr/src/tensorrt.
Because there is no output
Commenting out all the parts corresponding to outputIndexBBOX in trt_inference.cpp, compiling, and running it with the mnist.onnx model as input, the following error appears.
/samples/04_video_dec_trt$ sudo ./video_dec_trt 1 ../../data/Video/sample_outdoor_car_1080p_10fps.h264 H264 --trt-onnxmodel ../../data/Model/resnet10/mnist.onnx --trt-mode 0
[sudo] password for realwave:
set onnx modefile: ../../data/Model/resnet10/mnist.onnx
mode has been set to 0(using fp16)
----------------------------------------------------------------
Input filename: ../../data/Model/resnet10/mnist.onnx
ONNX IR version: 0.0.3
Opset version: 8
Producer name: CNTK
Producer version: 2.5.1
Domain: ai.cntk
Model version: 1
Doc string:
----------------------------------------------------------------
onnx2trt_utils.cpp:220: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
onnxToTRTModelinput 0x55a372a7b0
onnxToTRTModelbatch_size 1
**onnxToTRTModel 1 1 28 28**
onnxToTRTModel
Create TRT model cache
Opening in BLOCKING MODE
Opening in BLOCKING MODE
NvMMLiteOpen : Block : BlockType = 261
NVMEDIA: Reading vendor.tegra.display-size : status: 6
NvMMLiteBlockCreate : Block : BlockType = 261
Starting decoder capture loop thread
Video Resolution: 1920x1080
Resolution change successful
Input file read complete
**NvDdkVicConfigure Failed**
**nvbuffer_transform Failed**
Transform failed
Exiting decoder capture loop thread
Inference Performance(ms per batch):0 Wait from decode takes(ms per batch):0
NVMEDIA: NVMEDIABufferProcessing: 1099: Consume the extra signalling for EOS
[ERROR] (NvV4l2ElementPlane.cpp:178) <dec0> Output Plane:Error while DQing buffer: Broken pipe
Error DQing buffer at output plane
App run was successful
How do you approach this problem?
I changed the contents of trt_inference.h to the following.
Should we re-create the onnx model so that the bounding box-related contents are also displayed according to the example?
Or do I need to modify the code while leaving the model intact?
04 Looking at the sample help
It says that only dynamic batch(N=-1) onnx model is supported.
Then, can’t I use the model I’ve learned like the picture below?
If it is not available, what steps should be taken to use it?
Can you tell me how I entered the parameters to the torch.onnx.export function?
When I run the sample application as follows, the framework information is not known, so I ask.
set onnx modefile: ../../data/Model/resnet10/resnet10_dynamic_batch.onnx
mode has been set to 0(using fp16)
----------------------------------------------------------------
Input filename: ../../data/Model/resnet10/resnet10_dynamic_batch.onnx
ONNX IR version: 0.0.7
Opset version: 9
Producer name:
Producer version:
Domain:
Model version: 0
Doc string:
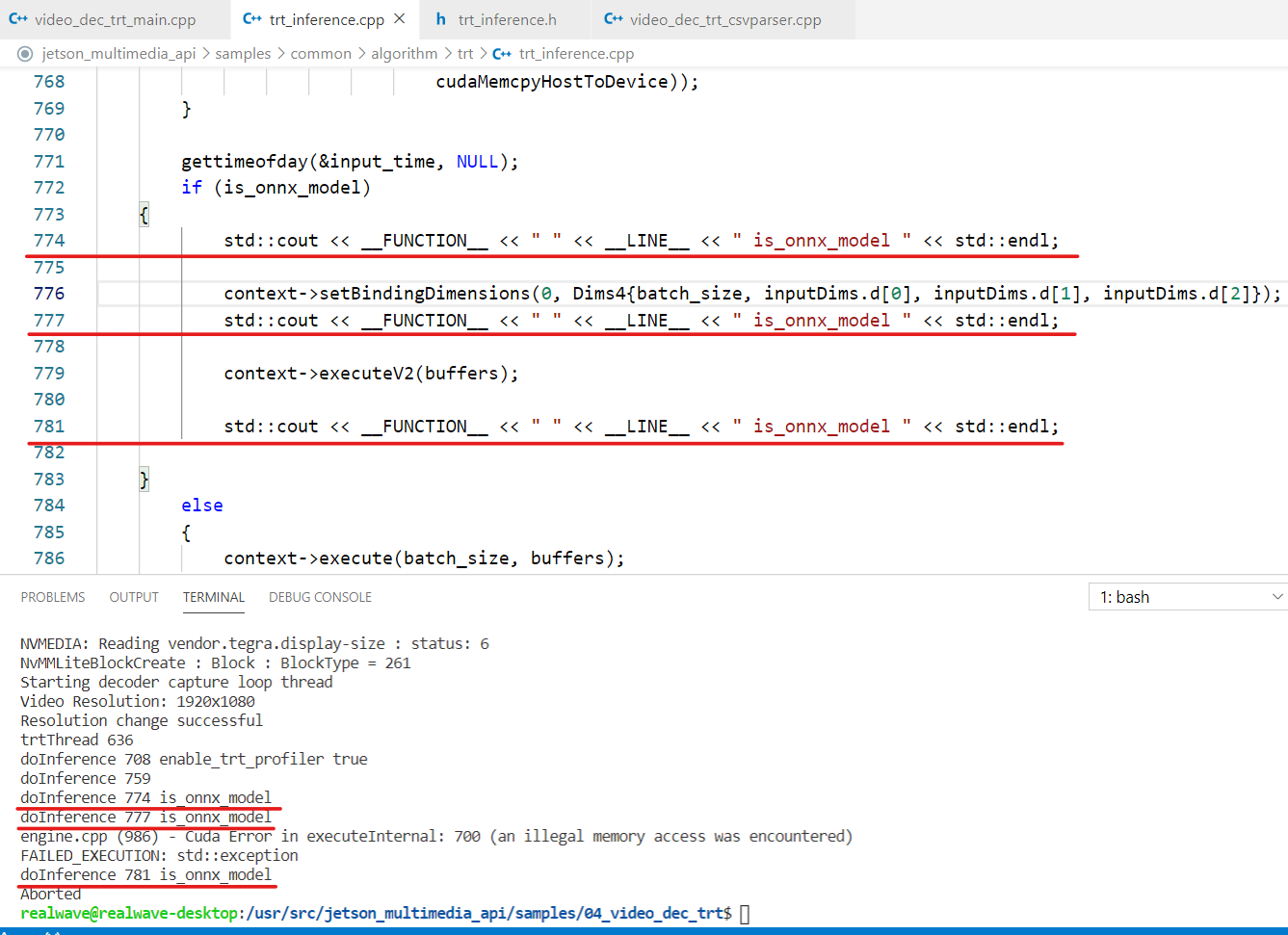
When inferring using a custom onnx model, the following error appeared.
I think there was an error after line 711
context->execute(.)
There seems to be an error when inferring from
There is a similar error in TensorRT, and will be fixed in our next major release.
To check if the same cause, could you run your model with trtexec on fp16 mode first?