Dear Nvidia user,
I’m trying to improve performance of the following scatter operations:
static void scatter_double( T *restrict out, const unsigned out_stride, const T *restrict in, const unsigned in_stride, const uint *restrict map,int dstride, int mf_nt, int*mapf, int vn, int m_size, int acc) { uint i,j,k,dstride_in=1,dstride_out=1; if(in_stride==1) dstride_in=dstride; if(out_stride==1) dstride_out=dstride; for(k=0;k<vn;++k) { omp target teams distribute parallel for map(tofrom:map[0:m_size],mapf[0:2*mf_nt]) if(acc) for(i=0;i<mf_nt;i++) { T t=in[in_stride*map[mapf[i*2]]+k*dstride_in]; for(j=0;j<mapf[i*2+1];j++) { out[out_stride*map[mapf[i*2]+j+1]+k*dstride_out] = t; } }}
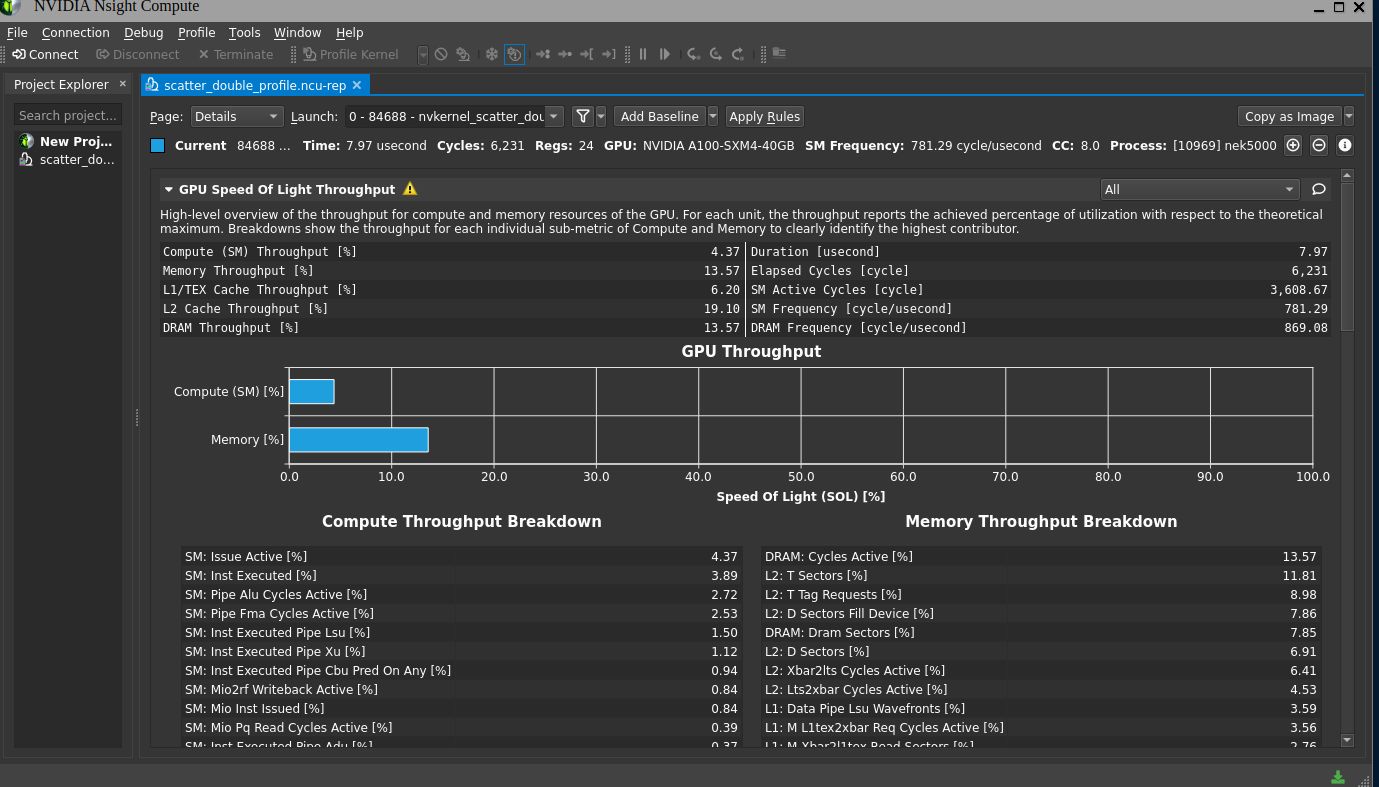
According to ncu analisys, such code uses GPU only for 4.37% of computational resources, So I think I can improve performance. ncu inform me kernel grid is too small. I tried TEAMS LOOP with no performance improvement. Any suggest? I think the major problem is the striding. Thanks.