You might have the experience you want if you work with this Project on GitHub.
It’s a multi-container Project.
I think you need to register for an Early Access Program or something to get ahold of the containers.
I think Edward posted it before.
You might have the experience you want if you work with this Project on GitHub.
It’s a multi-container Project.
I think you need to register for an Early Access Program or something to get ahold of the containers.
I think Edward posted it before.
I like the multi-container part of that. Interesting how Reddis, MilvusDB and the models all run in their own containers. Something about that project doesn’t run on my Titan RTX because it requires bfloat16 which isn’t supported on my Titan RTX card. I tried some other models that were supposed to work with float16 but the project always runs the mode with dtype=torch.bfloat16 At least i think that is the problem statement.
Looks like AI Workstation is Ampere and up when it comes to models.
Workbench doesn’t have a dependency on the GPU architecture. This kind of dependency happens at the container level, i.e. do the software libraries installed require a generation vs another.
If the code is backwards compatible and there’s a sufficient CUDA version, you should be good.
We will look to see if that particular setting for the precision can be changed to work with your GPU.
Hey, so it sounds like you are unable to run the model in the NIM container for the NIM Anywhere project.
According to the NIM docs GPU support matrix, you should be able to run a Llama3-8B Instruct NIM with a Titan RTX (compute capability 7.5, 24GB VRAM).
This looks like an issue on the NIM side where it’s not recognizing the hardware compute capability and bumping it down from bf16. We will raise the issue to the NIM team to look into the issue. Can you provide the following information on your issue so we can forward them appropriately? Thanks!
I’ll open an issue
(07/30) Added cloud support for Llama 3.1 family (8B, 70B, 405B), Mamba Codestral, and Mistral-NeMo 12B Instruct
Hi - the hybrid-rag app can only be accessed with localhost or 127.0.0.1. How can I make the app accessible via the server address eg 192.168.1.100?
Hi - You cannot do that, yet…
Not directly. Though it should be a fairly simply change in the launch script.
Here is how I did it using reverse SSH tunnel (the host is a Ubuntu server running the AI Workbench and the hybrid-chta project)
ssh -L 20000:127.0.0.1:10000 user@192.168.1.122
Explanation:
Hybrid Rag chat runs on 192.168.1.122 but only accessible using 127.0.0.1:10000/projects/hybrid-rag/applications/chat/ using remote desktop.
Execute in the commandline of my windows laptop or Mac terminal:
ssh -L 20000:127.0.0.1:10000 user@192.168.1.122
After login using your SSH credential to 192.168.1.122, you can access the rag at http://localhost:8000/projects/hybrid-rag/applications/chat/ from your laptop.
sorry. i meant there is no feature for it yet.
Workbench let you access the application on the remote already, so I’m curious as to your motivation for this approach.
Are you trying to share the application with someone else?
Yes, I am implementing every workbench example project available in github on an OVX server with 8x L40S GPU running Ubuntu as the backend.
Then I am setting up a windows laptop as demo station for each project in our AI lab to entertain visiting customers. After all, windows is what enterprises use for work.
I am also setting up all available LLM NIMs from NGC ie Llama3 and Mixtral to show case as well.
We are a NVIDIA Elite partner and this AI Workbench so far is the best effort IMHO to help us to better engage enterprise customers. Great work!
Thank you!
Might be good to schedule a demo of some advanced features that will be coming in a future release.
Hit me at aiworkbench-ea@nvidia.com and let’s get something on the calendar.
Hi! I’m on an M1 mac and the build is failing with this error:
#0 building with “desktop-linux” instance using docker driver
#1 [internal] load build definition from Containerfile
#1 transferring dockerfile: 1.85kB done
#1 DONE 0.0s
#2 [auth] huggingface/text-generation-inference:pull token for ghcr.io
#2 DONE 0.0s
[internal] load metadata for ghcr.io/huggingface/text-generation-inference:latest:
ERROR: failed to solve: ghcr.io/huggingface/text-generation-inference:latest: failed to resolve source metadata for ghcr.io/huggingface/text-generation-inference:latest: no match for platform in manifest: not found
I was able to pull the image locally using a platform flag:
docker pull --platform linux/x86_64 Package text-generation-inference · GitHub
Hi,
This project utilizes the Hugging Face TGI container as the base container for the project environment. Unfortunately, it appears that the Hugging Face team does not support a compatible container with MacOS according to the GitHub issue here.
Do you have a remote system you can connect to and run this project on as a workaround?
8/14/2024
Fixed a bug when parsing the IP/Hostname for Remote NIM.
“http://” was previously hardcoded for both IP and Hostname inputs, and https-based endpoints required manual change in the code. Now, smarter parsing has been implemented to differentiate between IPv4 and hostname inputs as well as perform some basic input validation. See the following table for usage examples.
| User Input | Parsed Endpoint |
|---|---|
| 10.123.45.678 | http://10.123.45.678:(port)/v1/ |
| http://10.123.45.678 | http://10.123.45.678:(port)/v1/ |
| http://10.123.45.678/ | http://10.123.45.678:(port)/v1/ |
| https://10.123.45.678 | https://10.123.45.678:(port)/v1/ |
| https://10.123.45.678/ | https://10.123.45.678:(port)/v1/ |
| my-nim.hostname.com | https://my-nim.hostname.com:(port)/v1/ |
| http://my-nim.hostname.com | http://my-nim.hostname.com:(port)/v1/ |
| http://my-nim.hostname.com/ | http://my-nim.hostname.com:(port)/v1/ |
| https://my-nim.hostname.com | https://my-nim.hostname.com:(port)/v1/ |
| https://my-nim.hostname.com/ | https://my-nim.hostname.com:(port)/v1/ |
8/15/24
8/22/2024
Hotfix pushed for an issue where users would not be able to properly upload their PDF documents and therefore would not have access to RAG generation. Fix is to pin the nltk package dependency in the environment to fix a bug with the unstructured package. See GitHub issue here for details.
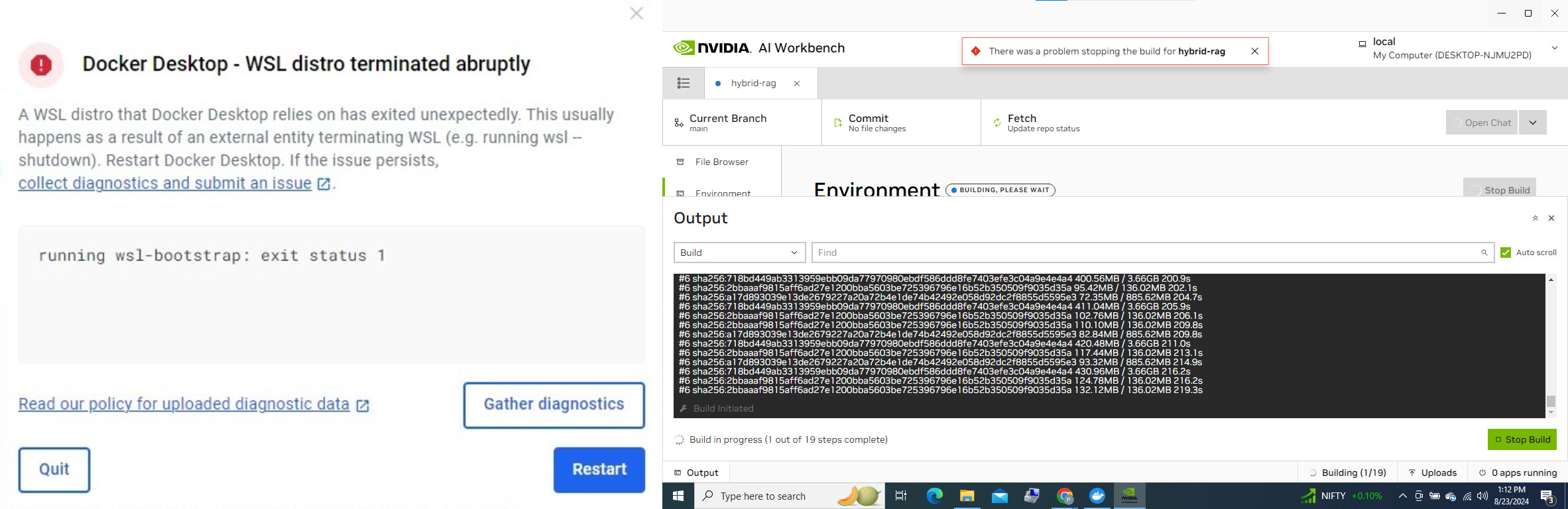
when building the project, I get the Docker Desktop - WSL distro terminated abruptly error, I even try restarting the container from Docker Desktop, but the project never proceeds ahead in building and never finishes building, workbench doesn’t even let me to stop the build as shown in the second screenshot saying There was a problem stopping the build for hybrid-rag. It doesn’t allow me to delete the project either since it’s building. Is there a way to delete the project completely in my computer locally so that I can try to build it again.
(8/26/2024) Readme updated with deeplinking
Hi, thanks for reaching out.
There is a manual option you can take to remove a project. Close out of your AI Workbench and follow these steps:
wsl > NVIDIA-Workbench > home > workbench > nvidia-workbench. This removes the contents of the project and its git repository from your machine.wsl > NVIDIA-Workbench > home > workbench > .nvwb > inventory.json. This clears out the project metadata from the AI Workbench application.// inventory.json with no projects
{
"Projects": null
}