I have completed a lot of searching here and not found straight-forward instructions yet (it might exist, of course, and I have not found it yet).
We use many Jetson Nanos and dGPUs and now even WSL running the Jetson-Inference containers. So we began training a huge dataset by searching the NVIDIA tutorials and trained our set with TAO Toolkit in a cloud environment. We now have a nice model with the file extension “.etlt”.
We began researching how to use that with Jetson-Inference and first…did not even know where to put nor reference the file. We think we figured that out by reviewing the c code and finding the various implementations of the Detect function where we can use the full path to the model (at least that is what we will try).
During our search we then found that Jetson-Inference does not (yet) use the TAO models. We found this out a little late. There seems to be convertors between formats to ONNX (which of course as newbies do not know anything about).
So I suppose we take our “.etlt” file, convert it to ONNX (or something) and then copy it to be used by the Jetson-Inference Docker container/image and call it from our Python app using Detect() with the full path to the model. Does this sound correct?
Is there more easy to follow instructions or examples out there already for those not familiar with external training like this? If not, has someone done this before or maybe has a good idea of how to accomplish?
Can you help explain your “Jetson-Inference” in details?
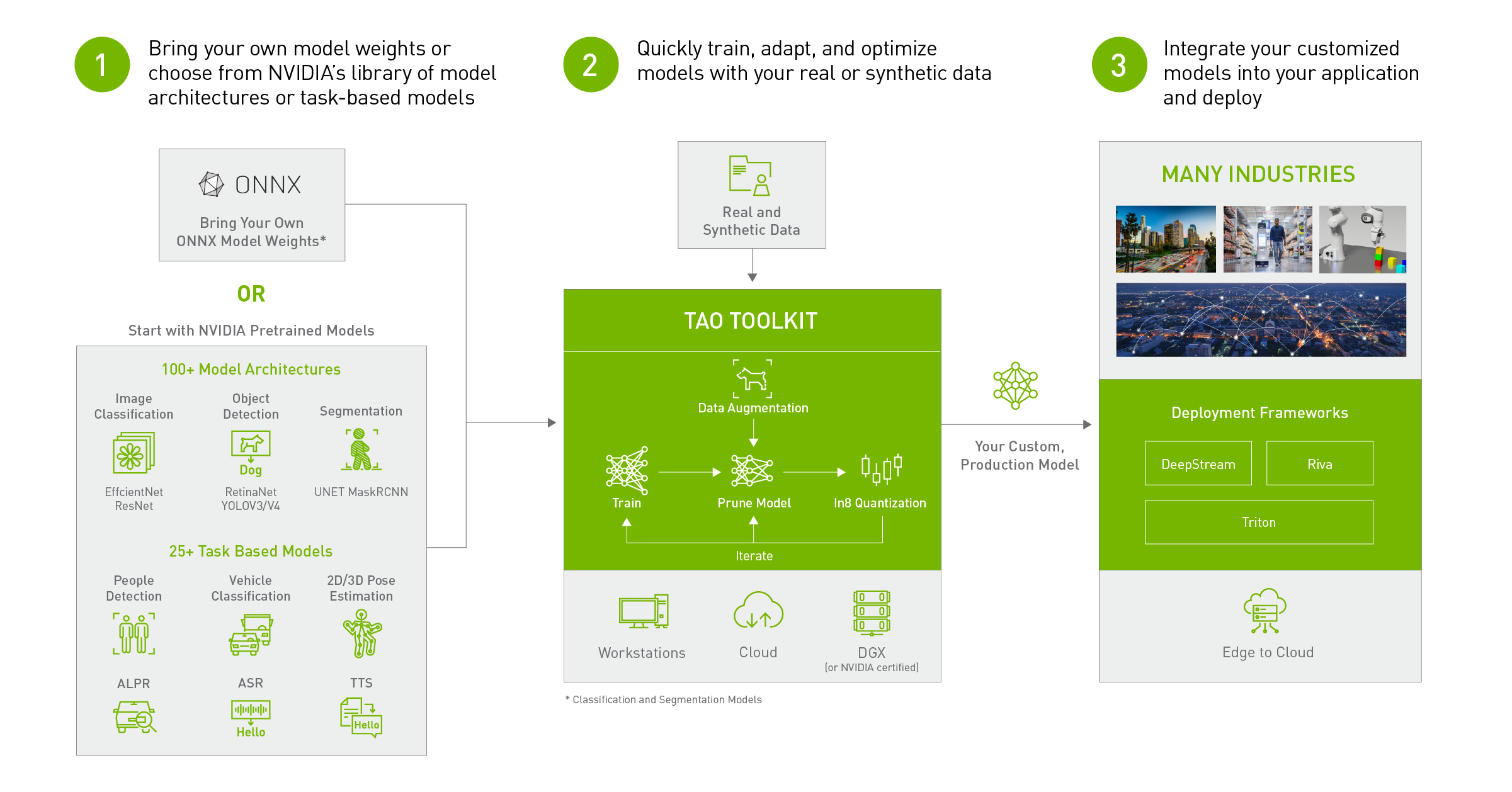
You can refer to the working flow here, the customized model from TAO can be deployed in DeepStream/Riva/Triton directly.
This will generate a TensorRT engine from your .etlt, and then you can load/run that engine with jetson-inference. Here’s an example script that I use to run the TAO Converter on PeopleNet:
This is a preliminary feature so it isn’t super thoroughly tested, so if you encounter any issues let me know. If you are using other models, you would need add support for them in the pre/post-processing of detectNet.cpp
Wonderful Dusty! We will test today I hope and will give feedback. I am optimistic! I am from Tennessee and you deserve a bottle of Jack. ;) Thank you!
Update! We got our model converted using your script…worked flawlessly!
Then we ran your Jetson_inference Docker Image on our systems (Jetson Nano, Ubuntu 20.04 Desktop, and my laptop with WSL) and all worked. Only thing we had to change in our code was the DetectNet line in Python:
FROM:
net = jetson_inference.detectNet(“ssd-mobilenet-v2”, threshold=0.4)
TO:
net = jetson_inference.detectNet(argv=[‘–model=our_model.etlt.engine’,
‘–labels=labels.txt’,
‘–input-blob=input_1’,
‘–output-cvg=output_cov/Sigmoid’,
‘–output-bbox=output_bbox/BiasAdd’,
‘–threshold=0.4’,
‘–headless’])
Awesome and thank you so much for sharing your libraries and more important your knowledge!
OK great, glad you got it working @gadworx! Thanks for testing that out and reporting back.
BTW, if you are using a recent build of jetson-inference, there is a parameterized detectNet constructor in Python for loading custom models (so you don’t have to manually make it into command-line arguments):
Thanks for the extra info! We really like your library and have enjoyed testing the new features with it.
On that note, I will share this…in your Jetson_Inference Container Image, it has the prerequites for the TAO converter in it, and I we used it to do our conversion from .etlt to .engine.
Additionally, as I mentioned in another message, in your Jetson_Inference Image, GStreamer works and displays Windows with gWSL (under windows!). In our Python code (above), we are not displaying any images though so we are not using this feature, but it does work on our systems.
Before changing our Python code as shown above, we tested it by running “detectnet” with the arguments from the CLI. It ran great until the very end when it would fail to display a window. I did not expect a window, so maybe this is by default. From memory, the error made me think of OpenGL, but I could be remembering wrong here. If so, OpenGL i guess may not work under WSL. Again, I could be remembering incorrectly and do not have that machine nearby to test again.
We added “–headless” to our CLI and it worked without error at this point. :)
Hope the info helps if you ever get into more WSL testing.
Thanks @gadworx, that’s useful info - yes, the --headless will prevent it from trying to open a window. By default, if it can open a window, it will try to (the caveat being, these windows may turn out to be unaccelerated / X11-tunelled, and then the CUDA/OpenGL interop fails later). What I’ve also been working on is WebRTC streaming for low-latency video streaming to the browser so that an actual display isn’t even needed really. I already support RTP streaming but it is more difficult to configure/view than WebRTC is.
{kind=link}