Please provide the following information when requesting support.
• Hardware (T4/V100/Xavier/Nano/etc) : GeForce 3090
• Network Type (Detectnet_v2/Faster_rcnn/Yolo_v4/LPRnet/Mask_rcnn/Classification/etc) : Yolo_v4
• TLT Version (Please run “tlt info --verbose” and share “docker_tag” here): TAO Toolkit 3.0
• Training spec file(If have, please share here): NA
• How to reproduce the issue ? (This is for errors. Please share the command line and the detailed log here.)
I’m trying to migrate from deepstream 5.1 to 6.1, I’m testing the installation using the master branch of the deepstream_tao_apps repo.
This is the software versions details:
Driver: 510.73.05
CUDA: 11.6.1
cuDNN: 8.4.0.27
TensorRT: 8.2.5.1
TensorRT OSS: 8.2.3
Deepstream 6.1
tao-converter: v3.22.05_trt8.2_x86 (downloaded from here)
The models is download using the provided script (download_models.sh), they don’t specify the exact Tao Version they use.
This is how I build the engine using tao-converter:
tao-converter -k nvidia_tlt \
-m 16 \
-b 8 \
-i nchw \
-d 3,544,960 \
-o BatchedNMS \
-t int8 \
-w 1073741824 \
-s false \
-p Input,1x3x544x960,8x3x544x960,16x3x544x960 \
-c /home/ds61/deepstream_tao_apps/models/yolov4/cal.bin.trt8251 \
-e /home/ds61/deepstream_tao_apps/models/yolov4/yolov4_resnet18_395.etlt_b1_gpu0_int8.engine \
/home/ds61/deepstream_tao_apps/models/yolov4/yolov4_resnet18_395.etlt
Output:
[INFO] [MemUsageChange] Init CUDA: CPU +473, GPU +0, now: CPU 484, GPU 872 (MiB)
[INFO] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 484 MiB, GPU 872 MiB
[INFO] [MemUsageSnapshot] End constructing builder kernel library: CPU 638 MiB, GPU 914 MiB
[INFO] ----------------------------------------------------------------
[INFO] Input filename: /tmp/file8DOaVH
[INFO] ONNX IR version: 0.0.7
[INFO] Opset version: 13
[INFO] Producer name:
[INFO] Producer version:
[INFO] Domain:
[INFO] Model version: 0
[INFO] Doc string:
[INFO] ----------------------------------------------------------------
[WARNING] onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[WARNING] onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
[INFO] No importer registered for op: BatchedNMSDynamic_TRT. Attempting to import as plugin.
[INFO] Searching for plugin: BatchedNMSDynamic_TRT, plugin_version: 1, plugin_namespace:
[WARNING] builtin_op_importers.cpp:4780: Attribute caffeSemantics not found in plugin node! Ensure that the plugin creator has a default value defined or the engine may fail to build.
[INFO] Successfully created plugin: BatchedNMSDynamic_TRT
[INFO] Detected input dimensions from the model: (-1, 3, 544, 960)
[INFO] Model has dynamic shape. Setting up optimization profiles.
[INFO] Using optimization profile min shape: (1, 3, 544, 960) for input: Input
[INFO] Using optimization profile opt shape: (8, 3, 544, 960) for input: Input
[INFO] Using optimization profile max shape: (16, 3, 544, 960) for input: Input
[INFO] Reading Calibration Cache for calibrator: EntropyCalibration2
[INFO] Generated calibration scales using calibration cache. Make sure that calibration cache has latest scales.
[INFO] To regenerate calibration cache, please delete the existing one. TensorRT will generate a new calibration cache.
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 193) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 197) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 203) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 302) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 306) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 311) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 399) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 402) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 406) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 639) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[WARNING] Missing scale and zero-point for tensor (Unnamed Layer* 643) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
[INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +809, GPU +350, now: CPU 1483, GPU 1264 (MiB)
[INFO] [MemUsageChange] Init cuDNN: CPU +127, GPU +58, now: CPU 1610, GPU 1322 (MiB)
[INFO] Local timing cache in use. Profiling results in this builder pass will not be stored.
[INFO] Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[INFO] Detected 1 inputs and 4 output network tensors.
[INFO] Total Host Persistent Memory: 139568
[INFO] Total Device Persistent Memory: 10023424
[INFO] Total Scratch Memory: 57782528
[INFO] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 9 MiB, GPU 1450 MiB
[INFO] [BlockAssignment] Algorithm ShiftNTopDown took 12.7983ms to assign 10 blocks to 110 nodes requiring 231810050 bytes.
[INFO] Total Activation Memory: 231810050
[INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 3115, GPU 1936 (MiB)
[INFO] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 3115, GPU 1944 (MiB)
[INFO] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +8, GPU +13, now: CPU 8, GPU 13 (MiB)
Then I run the app as follow:
./apps/tao_detection/ds-tao-detection \
-c configs/yolov4_tao/pgie_yolov4_tao_config_dgpu.txt \
-i /opt/nvidia/deepstream/deepstream-6.1/samples/streams/sample_720p.h264 \
-d
The output:
Now playing: configs/yolov4_tao/pgie_yolov4_tao_config_dgpu.txt
0:00:01.935548142 10920 0x55dde4d01780 INFO nvinfer gstnvinfer.cpp:646:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::deserializeEngineAndBackend() <nvdsinfer_context_impl.cpp:1900> [UID = 1]: deserialized trt engine from :/home/ds61/deepstream_tao_apps/models/yolov4/yolov4_resnet18_395.etlt_b1_gpu0_int8.engine
INFO: ../nvdsinfer/nvdsinfer_model_builder.cpp:610 [FullDims Engine Info]: layers num: 5
0 INPUT kFLOAT Input 3x544x960 min: 1x3x544x960 opt: 8x3x544x960 Max: 16x3x544x960
1 OUTPUT kINT32 BatchedNMS 1 min: 0 opt: 0 Max: 0
2 OUTPUT kFLOAT BatchedNMS_1 200x4 min: 0 opt: 0 Max: 0
3 OUTPUT kFLOAT BatchedNMS_2 200 min: 0 opt: 0 Max: 0
4 OUTPUT kFLOAT BatchedNMS_3 200 min: 0 opt: 0 Max: 0
0:00:01.953955834 10920 0x55dde4d01780 INFO nvinfer gstnvinfer.cpp:646:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::generateBackendContext() <nvdsinfer_context_impl.cpp:2003> [UID = 1]: Use deserialized engine model: /home/ds61/deepstream_tao_apps/models/yolov4/yolov4_resnet18_395.etlt_b1_gpu0_int8.engine
0:00:01.958405178 10920 0x55dde4d01780 INFO nvinfer gstnvinfer_impl.cpp:328:notifyLoadModelStatus:<primary-nvinference-engine> [UID 1]: Load new model:configs/yolov4_tao/pgie_yolov4_tao_config_dgpu.txt sucessfully
Running...
End of stream
Returned, stopping playback
Deleting pipeline
No error show up but there is no bbox showing:
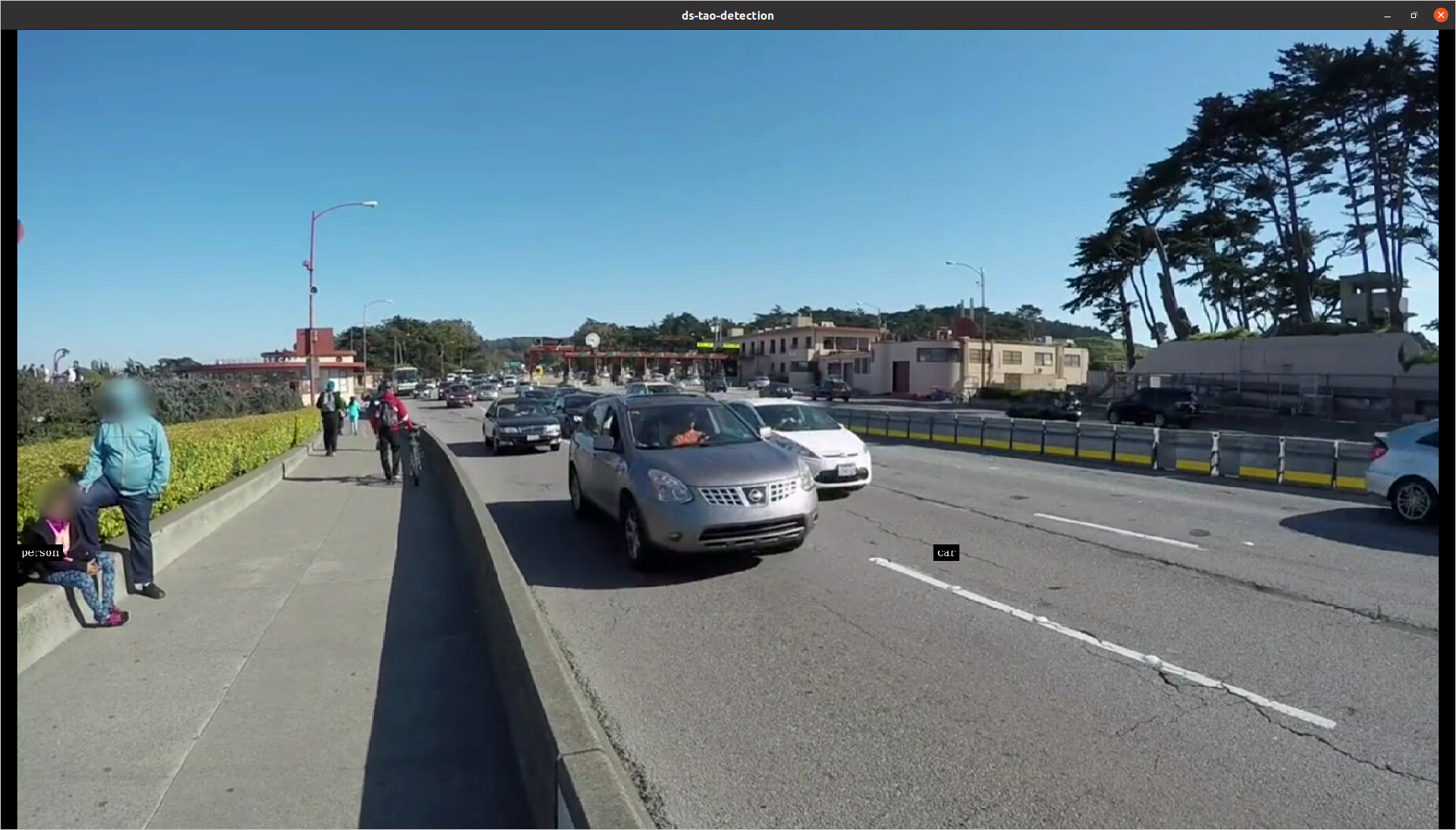
However, if I let deepstream build the engine, instead of using tao-converter, then everything works as expected:
Simply running the app directly without using tao-converter:

engine building output:
Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1914> [UID = 1]: Trying to create engine from model files
WARNING: [TRT]: onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: onnx2trt_utils.cpp:392: One or more weights outside the range of INT32 was clamped
WARNING: [TRT]: builtin_op_importers.cpp:4780: Attribute caffeSemantics not found in plugin node! Ensure that the plugin creator has a default value defined or the engine may fail to build.
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 193) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 197) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 203) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 302) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 306) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 311) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 399) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 402) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 406) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 639) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
WARNING: [TRT]: Missing scale and zero-point for tensor (Unnamed Layer* 643) [Constant]_output, expect fall back to non-int8 implementation for any layer consuming or producing given tensor
0:09:34.918970179 9272 0x55a78f92e180 INFO nvinfer gstnvinfer.cpp:646:gst_nvinfer_logger:<primary-nvinference-engine> NvDsInferContext[UID 1]: Info from NvDsInferContextImpl::buildModel() <nvdsinfer_context_impl.cpp:1946> [UID = 1]: serialize cuda engine to file: /home/ds61/deepstream_tao_apps/models/yolov4/yolov4_resnet18_395.etlt_b1_gpu0_int8.engine successfully
Why does the engine build using tao-converter not working?