Regarding the memory transfer of cuda, the actual transfer rate between Host and Device and device to device can be measured through cuda-z.
But is there any calculation for the theoretical transfer rate of this device to device?
In addition, the theoretical rate of the traffic between global and GPU chips should be described by the memory bandwidth. The shared bandwidth inside the GPU is obviously much higher than the memory bandwidth. But is there any way to measure the actual communication rate between global and shared?
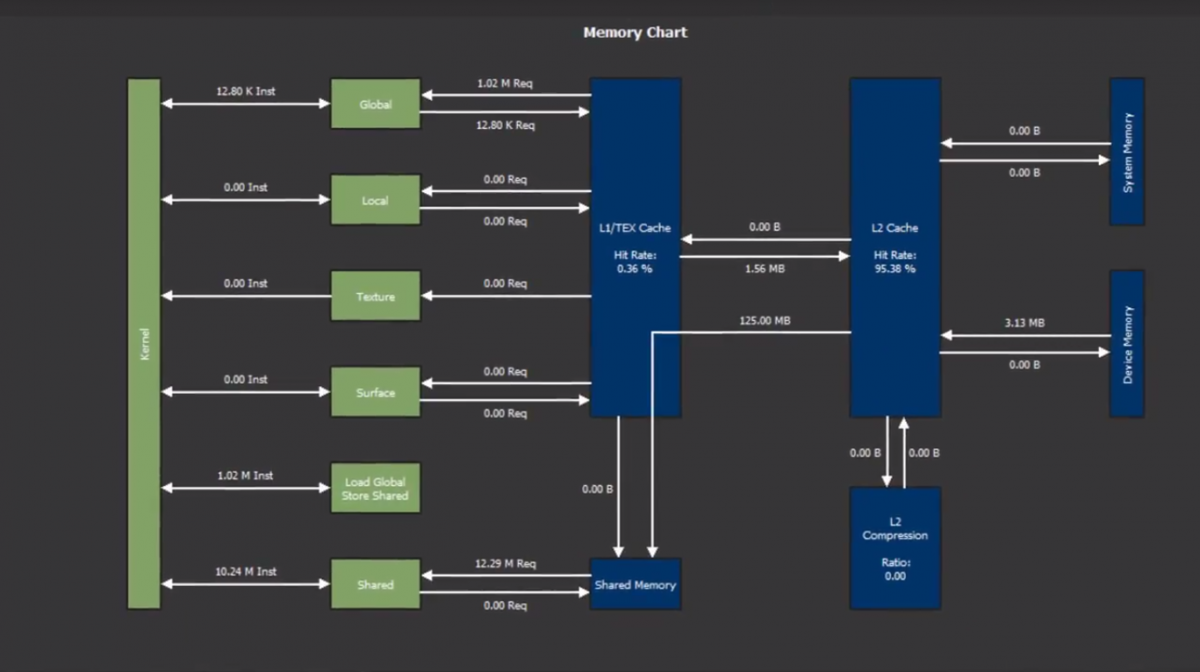
You can use the Nsight Compute (cuda profiler) to generate a report showing potential and achieved memory transfer rates (although not device to device). The reports will also provide guidance on how to achieve better memory bandwidth performance.
See the Nsight Compute overview and download the tool, especially the sections on Memory Workload Analysis and Roofline Analysis and Occupancy analysis.
Additionally, Nsight Compute’s Baseline Comparisons allows you to compare reports from different versions of your code, so you can see the affects of your tweaks.
For more detail, see Nsight Compute Documentation, Videos, and Blogs
{kind=link}