i have a question, how can i use multiple GPU at same time, if answer is yes,so can anyone explain me how

GPU core architecture diagram: The core code is Creeper 200, a new interconnection method, and L1.5 Cache is introduced between SM and L2 Cache to play a buffering role. Now, ZRLink can directly access L2 Cache, and each GPM has 8 ZRLinks for high-speed interconnection with GPM. And has a redundant design, even if one ZRLink link is damaged, causing direct communication between two GPMs in a full connection, the ZRLink link can pass through other GPMs to reach the GPM that needs to be accessed.
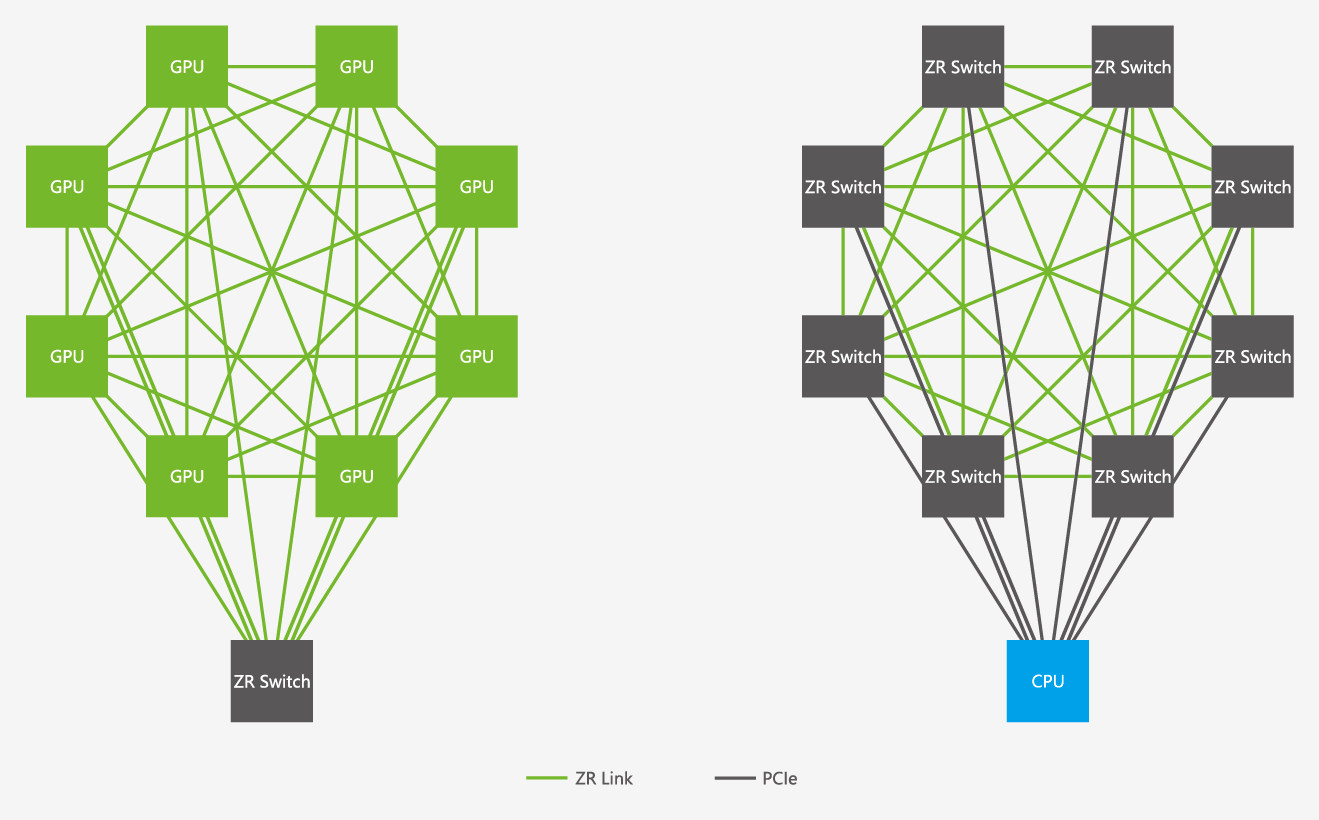
The interconnection method of 8 GPU modules: Among the 8 GPU Modules, each GPM is fully connected to each other, and each GPM will have a link connected to the Switch, forming a Fully connected + Star interconnection method. When exchanging data between two GPUs, the data exchange will be preferentially carried out through the full connection, and when accessing another GPU, they will be connected through the switch. At the same time, the interconnection topology between switches is also a Fully connected + Star interconnection method. When data exchange is performed between each switch (GPU), a fully connected link will be preferentially selected to ensure lower latency and greater bandwidth. In a system with 8 GPUs, the CPU can be directly connected to each switch to form a Star interconnection method to reduce latency without changing the existing CPU as much as possible.

This is a GPU consisting of 8 GPMs as shown in the figure. The middle DIE contains Switch and PCIe Host interfaces, which can take care of the high-speed interconnections between each GPM and other GPUs, while providing PCIe Host interfaces for each GPM to ensure it can be used in ordinary computers and improve versatility.

GPU core architecture diagram: core code Block 100, ALU cluster based on unified computing architecture, 128 FP32 units per SM unit, 8 tensor cores. There are 10 SM units in each group of GPC units, and there are two GPC units in each GPU DIE. There are 2560 FP32 CUDA COREs, which support multi-instance GPU (MIG) technology. A GPU DIE can be divided into up to 20 independent GPU instances, a GPC unit or TPC unit or SM unit can be divided into one GPU instance, so a GPU DIE can be divided into 2 or 10 or 20 GPU instances, totally three modes. GPU instances of each mode can run simultaneously, and each mode can match each other. GPU instances of different modes can run simultaneously. Each instance has its own memory, cache, and streaming multiprocessors. In multiple GPU instances, GPU cloud acceleration can be provided to a large number of clients, such as the account of each mobile phone, and different resources can be allocated according to different accounts. And some of the less configured clients can use GPU cloud acceleration to make the game less stunning, and can be applied to school servers to provide GPU computing power for each client, and more… and doubling the number of ZRLinks at the core of this GPU also means doubling the bandwidth of the connection. L1.5 Cache is also introduced between SM and L2 Cache to buffer
The four memory controllers (Memory controllers) on the GPU are applied to HBM3 high-bandwidth memory, which is close to the display memory and easy to wiring to save production costs. The memory controller on the left and right ends is applied to GDDR6X memory. For in-depth learning training, the GPU prefers HBM3 high-bandwidth memory, because generally, the data model for in-depth learning training is not very large, plus support for mixed precision (FP16+FP8), so the demand for video memory capacity is usually not very tense during training.
For AI reasoning and training some large models, the size of the display memory is particularly important, because it directly determines whether the GPU can be trained and reasoned. This requires a memory controller (GDDR6X) on both the left and right ends. With the iteration of deep learning algorithms, the GPU now requires more and more memory. For example, the recently leaked Diffusion Model-based AI painting, which relies on single-precision floating-point performance, cannot even reasonably calculate 720P image size with 24GB of memory. This has caused me to think deeply, and I think we can support HBM3 and GDDR6X memory in one core at the same time. Because GDDR6X is cheaper than HBM3 and has much higher bandwidth than CPU’s shared memory, it is a cost-effective option and we can call GDDR6X when HBM3 is not enough. They are encapsulated in the same SXM module, and the power supply in the SXM module is transferred to the motherboard to improve the calculation density.