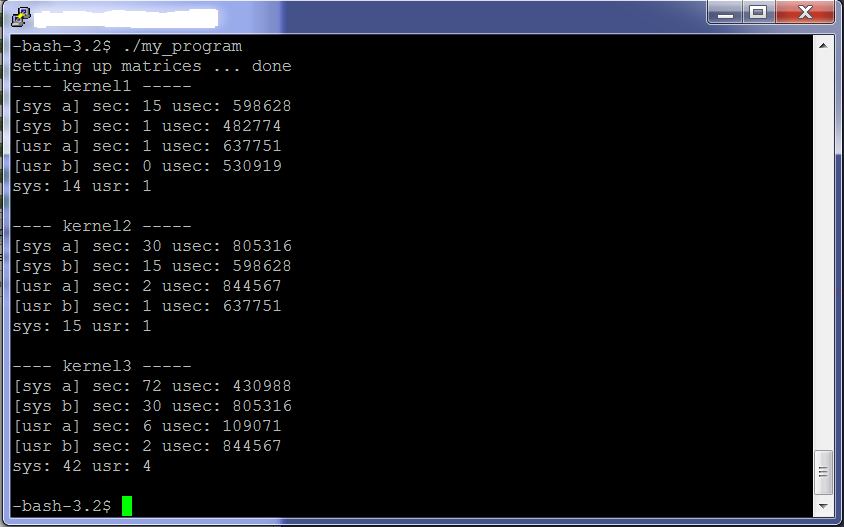
I ran the below code and get an output as the following (attached).
The main issue is that the usec values and sec values are not equivalent and they should be. I thought usec was microseconds and sec in seconds, however they do not correspond. Im trying to find out how long the kernal is employed for in each kernal invocation.
Any help would be greatly appreciated.
#include <stdio.h>
#include <sys/resource.h>
#include "common.h"
#define TILE_SIZE 16
#define SIZE (TILE_SIZE * 128)
float INIT0[] = {1.23, 23.4, 0.1, 9.12};
float INIT1[] = {213.9, 11.111, 872, -23, 16.1718};
void
cpu_mult(const float *m1, const float *m2, float *m3, unsigned int width) {
unsigned int i, j, k;
float result;
for (i = 0; i != width; ++i) {
for (j = 0; j != width; ++j) {
result = 0;
for (k = 0; k != width; ++k)
result += m1[i*width + k] * m2[k*width + j];
m3[i*width + j] = result;
}
}
}
__global__ void
kernel1(const float *m1, const float *m2, float *m3, unsigned int width) {
const unsigned int row = blockIdx.y*blockDim.y + threadIdx.y;
const unsigned int col = blockIdx.x*blockDim.x + threadIdx.x;
unsigned int i;
float result = 0;
for (i = 0; i != width; ++i)
result += m1[row*width + i] * m2[i*width + col];
m3[row*width + col] = result;
}
__global__ void
kernel2(const float *m1, const float *m2, float *m3, unsigned int width) {
const unsigned int row = blockIdx.y*blockDim.y + threadIdx.y;
const unsigned int col = blockIdx.x*blockDim.x + threadIdx.x;
unsigned int t, i;
float result = 0, a, b;
for (t = 0; t < width / TILE_SIZE; ++t) {
for (i = 0; i != TILE_SIZE; ++i) {
a = m1[row*width + t*TILE_SIZE + i];
b = m2[(t*TILE_SIZE + i)*width + col];
result += a * b;
}
__syncthreads();
}
m3[row*width + col] = result;
}
__global__ void
kernel3(const float *m1, const float *m2, float *m3, unsigned int width) {
__shared__ float sm1[TILE_SIZE][TILE_SIZE];
__shared__ float sm2[TILE_SIZE][TILE_SIZE];
const unsigned int row = blockIdx.y*blockDim.y + threadIdx.y;
const unsigned int col = blockIdx.x*blockDim.x + threadIdx.x;
unsigned int t, i;
float result = 0;
for (t = 0; t < width / TILE_SIZE; ++t) {
sm1[threadIdx.y][threadIdx.x] = m1[row*width + (t*TILE_SIZE + threadIdx.x)];
sm2[threadIdx.y][threadIdx.x] = m2[(t*TILE_SIZE + threadIdx.y)*width + col];
__syncthreads();
for (i = 0; i != TILE_SIZE; ++i)
result += sm1[threadIdx.y][i] * sm2[i][threadIdx.x];
__syncthreads();
}
m3[row*width + col] = result;
}
void
print_times(const char *kernel, struct rusage *before, struct rusage *after) {
printf("---- %s -----\n", kernel);
printf("[sys a] sec: %ld usec: %ld\n", after->ru_stime.tv_sec, after->ru_stime.tv_usec);
printf("[sys b] sec: %ld usec: %ld\n", before->ru_stime.tv_sec, before->ru_stime.tv_usec);
printf("[usr a] sec: %ld usec: %ld\n", after->ru_utime.tv_sec, after->ru_utime.tv_usec);
printf("[usr b] sec: %ld usec: %ld\n", before->ru_utime.tv_sec, before->ru_utime.tv_usec);
printf("sys: %ld usr: %ld\n", after->ru_stime.tv_sec - before->ru_stime.tv_sec, after->ru_utime.tv_sec - before->ru_utime.tv_sec);
printf("\n");
fflush(stdout);
}
int
main(void) {
float *hm[3], *dm[3];
unsigned int i;
struct rusage times[2];
dim3 bdim(TILE_SIZE, TILE_SIZE);
dim3 gdim(SIZE/TILE_SIZE, SIZE/TILE_SIZE);
fprintf(stderr, "setting up matrices ... "); fflush(stderr);
for (i = 0; i != 3; ++i) {
hm[i] = create_matrix_h(SIZE, SIZE);
dm[i] = create_matrix_d(SIZE, SIZE);
}
fill_matrix_h(hm[0], SIZE, SIZE, INIT0, sizeof(INIT0)/sizeof(float));
fill_matrix_h(hm[1], SIZE, SIZE, INIT1, sizeof(INIT1)/sizeof(float));
cudaMemcpy(dm[0], hm[0], SIZE * SIZE * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dm[1], hm[1], SIZE * SIZE * sizeof(float), cudaMemcpyHostToDevice);
fprintf(stderr, "done\n"); fflush(stderr);
/*
getrusage(RUSAGE_SELF, ×[0]);
cpu_mult(hm[0], hm[1], hm[2], SIZE);
getrusage(RUSAGE_SELF, ×[1]);
print_times("CPU", ×[0], ×[1]);
*/
getrusage(RUSAGE_SELF, ×[0]);
kernel1<<<gdim, bdim>>>(dm[0], dm[1], dm[2], SIZE);
cudaThreadSynchronize();
getrusage(RUSAGE_SELF, ×[1]);
print_times("kernel1", ×[0], ×[1]);
getrusage(RUSAGE_SELF, ×[0]);
kernel2<<<gdim, bdim>>>(dm[0], dm[1], dm[2], SIZE);
cudaThreadSynchronize();
getrusage(RUSAGE_SELF, ×[1]);
print_times("kernel2", ×[0], ×[1]);
getrusage(RUSAGE_SELF, ×[0]);
kernel3<<<gdim, bdim>>>(dm[0], dm[1], dm[2], SIZE);
cudaThreadSynchronize();
getrusage(RUSAGE_SELF, ×[1]);
print_times("kernel3", ×[0], ×[1]);
for (i = 0; i != 3; ++i) {
cudaFree(dm[i]);
free(hm[i]);
}
return 0;
}