Briefly: Why does a simple single-threaded kernel that uses 40 KB of local memory consume 450 MB of global memory during execution?
Details:
Complete CUDA code that shows the kernel and its invocation:
__global__ void fooKernel( int* dResult )
{
const int num = 10000;
int val[num];
for ( int i = 0; i < num; ++i )
val[i] = i * i;
int result = 0;
for ( int i = 0; i < num; ++i )
result += val[i];
*dResult = result;
return;
}
int main()
{
int* dResult = NULL;
cudaMalloc( &dResult, sizeof( int ) );
for ( int i = 0; i < 1000; ++i )
fooKernel<<< 1, 1 >>>( dResult );
cudaFree( dResult );
return 0;
}
Note that:
[*] The kernel is using a local array of 10K elements. Int is 4 bytes, so local memory consumption should be 40 KB.
[*] Note that only a single thread (1,1) of the kernel is invoked.
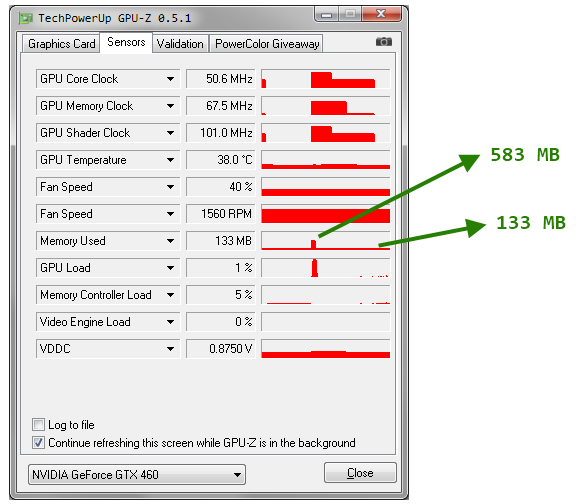
Attached to this post is a screenshot of GPU-Z tracking the GPU memory this program consumes when it is executed.
When idle, GPU memory is 133MB
During execution, GPU memory usage jumps to 533 MB
Subtracting, 533-133=450 MB.
To restate, why does a simple single-threaded kernel that uses 40 KB of local memory consume 450 MB of global memory during execution?
Because your GTX460 is a Fermi device, the runtime reserves a big chunk of heap space to support in-kernel printf, malloc and non-inline functions and recursion. On a 3Gb C2050, it isn’t all that noticeable, but on a smaller memory Fermi Geforce it might be problematic. You can use cudaThreadSetLimit to control how much space the runtime will reserve for this stuff.
Thanks for the information about cudaThreadSetLimit, I will check that.
Here is something that I think indicates that this has nothing to do with the support for printf, malloc, non-inline functions and recursion. I ran the same kernel as shown above, but with different values of num. That is, with different sizes of local memory. I found that the GPU memory consumption shown by GPU-Z also varied along with local memory!
Here are the values for local memory and GPU memory (as calculated from GPU-Z):
400 : 39MB
4K: 69MB
40K: 400MB
400K: Program crashes!
With the above observations, how can we explain the massive amount of global memory consumed for a tiny 1-thread kernel? Why is the global memory consumption varying along with local memory size? Why is the kernel crashing for 400K of local memory? (According to Appendix G of CUDA Programming Guide, the limit on local memory per thread is 512 KB for device of capability 2.0 or more. 400KB is less than 512KB).
Local memory has to be allocated by the driver, same as a global memory allocation. You don’t see it, but it happens.
Allocating memory is slow.
So, when we see that you have a kernel that is going to use 80KB of local memory per thread, we preallocate it. However, you can’t just allocate 80KB and be done with it–we don’t know how many threads you’re going to launch. So, we preallocate enough such that if you filled the GPU with that kernel, you would have enough local memory already allocated. On a GF110, for example, this could be 16 (SMs) * 1536 (threads per SM) * local memory per thread. That means that one byte per thread becomes 24KB of memory allocated, assuming you can fit that many threads per SM on the card.
(I think what I’ve described is correct, but I might be wrong in some details. I’ll double check in the next few days.)
I tried setting the minimum possible sizes of printf and heap memory using cudaThreadSetLimit. The GPU memory usage for the above program shows absolutely no change with these settings. So, the massive amounts of GPU memory being consumed are not due to this heap space.
Note: Please see tmurray’s reply below which hints at a local memory pre-allocation strategy being used by NVIDIA. Though it is not clear why NVIDIA needs to pre-allocate local memory for the maximum number of threads, it does fit the memory usage pattern I am witnessing.
Thanks for that clarification. That falls in line with my suspicions and the calculations I had been pondering over.
I find that this pre-allocation is being done at the time a kernel is invoked, and not at the time the program is executed. I verified this by inserting a getchar() before kernel invocation and by tracking the GPU memory usage using GPU-Z for the program.
Now, if the pre-allocation is being done at kernel invocation, why pre-allocate so much local memory as to saturate the GPU? The number of threads is a value that is available at kernel invocation, why not only pre-allocate that exact amount of local memory?
I’d like to see a runtime flag to specify this behavior in CUDA 3.3, through cudaSetDeviceFlags() !
I found an interesting flag that seems related, but is meant to NOT reduce local memory:
cudaDeviceLmemResizeToMax: Instruct CUDA to not reduce local memory after resizing local memory for a kernel. This can prevent thrashing by local memory allocations when launching many kernels with high local memory usage at the cost of potentially increased memory usage.
Thanks for pointing out this flag. What is needed is a flag that does the opposite of this: do not try to allocate local memory enough for the maximum number of possible threads! External Image
{kind=link}