I have always had the impression that the minimum size of a block should not be less than a warp size, which is 32. but I just accidentally found that I could launch my kernel with a blocksize less than 32. For a number of block size settings, such as 2, 4 or 8, I was able to get faster speed (20% higher) compared to the case of 32 or 64 threads per block. this was found on both TitanV and TitanX (pascal) with cuda 9.
does this make sense? isn’t it true that I waste hardware resources if I launch only 4 threads per block? or, now the hardware allows for smaller block sizes?
also, I found this function “cudaOccupancyMaxPotentialBlockSize” and when I tried to call it with
mcx_core.cu(1619): error: no instance of function template "cudaOccupancyMaxPotentialBlockSize" matches the argument list
argument types are: (unsigned int *, unsigned int *, void *)
I know that you can specify a block size that is less than 32, but I expect that will make part of the warp idle, and reduce resource utilization. I was just surprised that this lead to significantly higher speed
if someone is interested in checking this out, here are the commands
git clone https://github.com/fangq/mcx.git
cd mcx/src
git checkout etherdome
make
cd ../example/skinvessel
./run_mcxyz_bench.sh # run with 64 thread per block
./run_mcxyz_bench.sh -A 0 -t 100000 -T 6 # run with 6 thread per block
the first run before the sed command uses the default 64 thread/block, and the last command uses a block size of 4 (you can change it using the -T flag). For multiple GPUs, I found the block size of 4 gives 20-30% speed up.
I did try either of the below formats, but ended up with the same error:
cudaOccupancyMaxPotentialBlockSize (&mingrid, &blocksize, mcx_main_loop);
or
cudaOccupancyMaxPotentialBlockSize (&mingrid, &blocksize, mcx_main_loop<MCX_SRC_PENCIL>);
the error is
mcx_core.cu(1617): error: no instance of function template "cudaOccupancyMaxPotentialBlockSize" matches the argument list
argument types are: (unsigned int *, unsigned int *, <unknown-type>)
this kernel is defined in the earlier section of the unit at
This is an instance where your first thought should probably be “Let me take a closer look at this with the CUDA profiler”, rather than “Let me ask forum participants.” You know your own code much better than we do.
well, my first thought was that there was a change of min-warp size in CUDA that I was not aware of, thus, I was hoping that someone could point me to the updates.
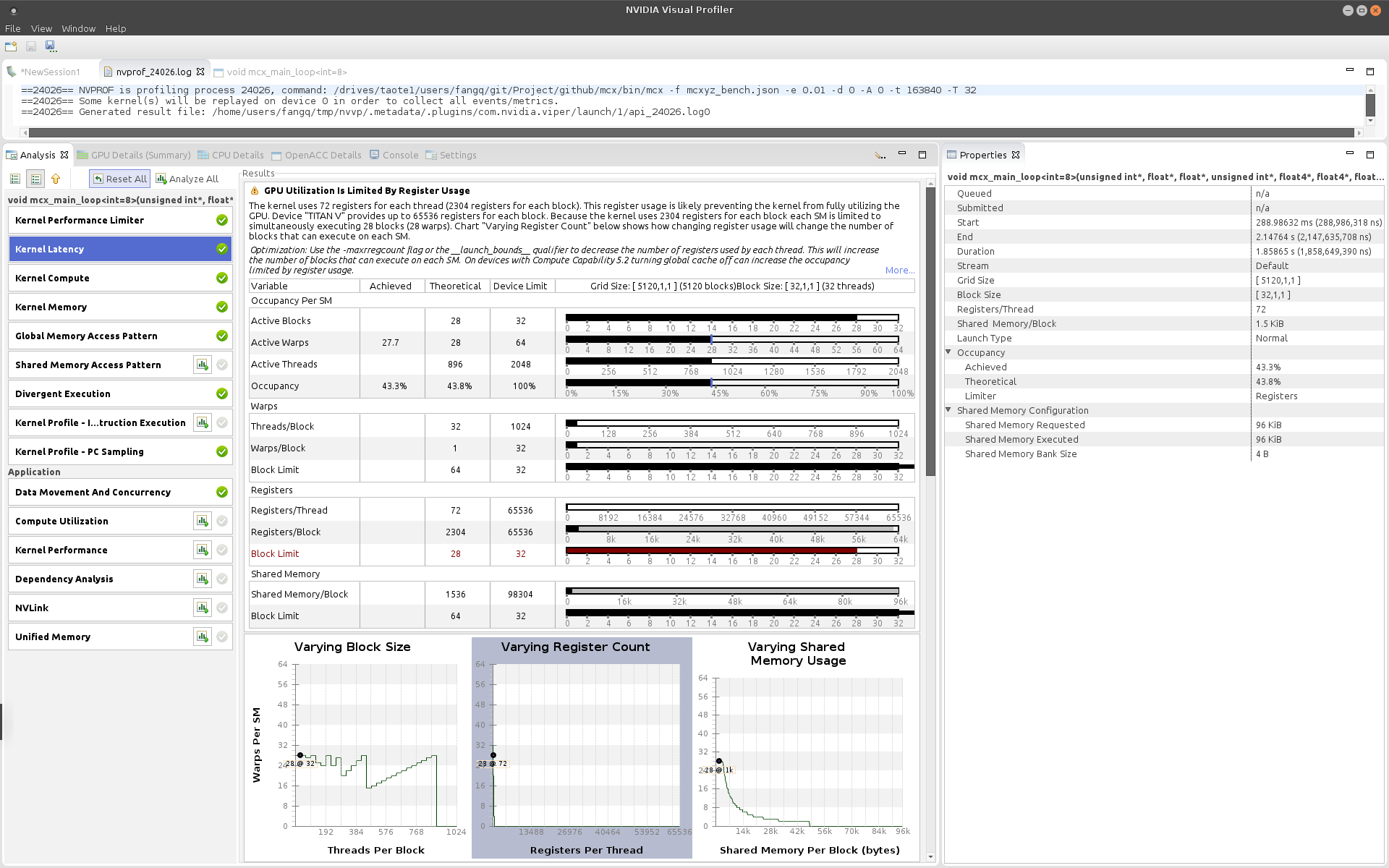
I ran the profiler, still need to digest the outputs. A block-size of 4 seems doubled the active blocks from 14 to 28, but does not seem to change “active warp” size. there is a very minor increase in occupancy. I am not sure what this really means. The Kernel latency report from the block size of 4 is shown below
and that for a blocksize of 32 [image updated on Dec. 5, 2018, previously it was for blocksize=64]:
[added on Dec. 5, 2018]
Profiling output for a blocksize of 64:
I also noticed that for the blocksize of 32<correction: should be 64 here>, the memory dependency cases more latency (87.4%) than the block size of 4 (62.7%).
thanks Robert, the unsigned int type difference was indeed the problem. after defining those to int, the above API is compiled properly. however, the output is not exactly helpful - for my kernel, it outputs an optimal blocksize of 896, which is just the opposite of my experience - I would expect the optimal blocksize is a smaller than 32 number.
I think the key is now how to digest the nvvp output posted above - why running 4 thread/block gives me better occupancy (which I really think is a misleading metric) and more active blocks?
The API call is focused on maximizing occupancy, not performance. They are often correlated, but not always. I don’t see any difference in the graph output of warps per SM vs. threadblock size, whether looking at the 4 or 32 case, so I’m not sure why you think any of this is misleading, or what you mean exactly. Again, you may be conflating occupancy with performance in your head, but the profiler does not conflate occupancy with perforance AFAICT, and the API does not say anything about performance, it relates occupancy with threadblock size, for a given kernel. (And the graph in the profiler output indicates 896 is a reasonable choice, to maximize warps per SM)
There could be at least 2 things going on to explain register differences
you are not compiling for the architecture you are running on. Then driver will JIT the PTX to whatever arch the GPU you are running on, which will change (possibly) the register usage.
register allocation granularity. The register requirement is indicated by ptxas. The actual register usage or runtime footprint may be somewhat higher because registers are usually not allocated one-by-one to threads, they often have an allocation granularity of e.g. 4 registers.
I don’t know that this would fully explain the difference from 63 to 72, but it might. More details would be needed, such as what GPU you are compiling for and what actual GPU you are running on. Even if you provided those details, I’m not sure I could explain the difference completely
I understand that maximum occupancy does not mean maximum performance, in fact, for my particular application (Monte Carlo simulation), I have noticed that occupancy poorly, or even negatively correlated with performance since the beginning of my project (8~9 yr ago). The thing is most people use these metrics for the purpose of maximizing performance - maximizing/minimizing a particular metric per se is not really that useful - but right now, without this expected correlation, it is really hard to guide the code optimization. In order words, most GPU metrics offer some level of coarse grained guidance, but hard to pinpoint specific bottlenecks.
there is one exception, the PC sampling view from nvvp turns out to be very helpful - this maps the latency to source code lines, allowing me to identify hotspots and optimize them, but it does not have the ability to tell me what is the optimal block/thread configuration.
in a recent paper [1], we studied the thread/workgroup size for the OpenCL version of this code (mcxcl), but only did it empirically because neither nvvp supports OpenCL, nor can I extrapolate my findings from the CUDA version (because nvidia opencl support is badly outdated). Eventually, the optimal block/thread size is still an unsolved problem.
both the compilation and execution were on the same computer/GPU (2x TitanV), but the compilation uses -arch=sm_30 for portability. I think the difference was likely due to what you said - that JIT allows the kernel to use more registers (and avoid spilling) when it is running on a more recent GPU.
one other question related to JIT compilation is that - can the JIT help improve predication of branches? my kernel contains many tests based on user inputs (stored in the constant memory), like this one
for OpenCL, I can use clBuildProgram options to dynamically disable/enable blocks of codes (such as using -DSAVE_DETECTORS to enabling/disabling this block) and help reduce register use. But is this possible in CUDA’s JIT?
the only thing we know is to use template to let nvcc compile multiple kernels for each execution path, but it is a bit tedious to convert all flags to template parameters.
That strikes me as a bad idea. There were significant changes going from the Kepler to the Maxwell architecture. For Pascal and Maxwell, it would probably be fine to compile with sm_50 as a baseline: the architectures and the compiler’s code generation are very similar.
I haven’t used Volta, but it seems different enough architecturally from previous architectures to warrant compilation specifically for this architecture.
If you need to support multiple architectures, fat binaries combined with some conditional compilation based on GPU architecture is probably the way to go. Also, look into auto-tuning various sizing and blocking parameters your code has. Yes, I am aware that setting up an auto-tuning framework can be a non-trivial amount of work.
Your code seems to have fairly high register pressure, you might want to look into reducing that. Whether this is possible I can’t assess since I don’t know the code. Is the code mostly computation on 64-bit data types?
Your screenshot labelled “for a blocksize of 32” actually shows the kernel latency report for a blocksize of 64. I wonder if that could explain you unexpected findings?
the decision was based on speed tests of the binaries compiled for each architecture. essentially, from fermi to pascal, there is no noticeable speed improvement. only when I set -arch to sm_70, I got about 5% speed increase on my titan v. I suppose this is application specific, I am sure other kernels may gain some performance for certain architecture.
fat-binary is not forward compatible - if I compile the binary using “-code=sm_20 -code=sm_30 -code=sm_35 -code=sm_50 -code=sm_52 -code=sm_61” and try to run it on titan v (sm_70), I will get an error “invalid device symbol”. in comparison, compiling .cu file using only a single -arch=sm_xx, where xx is the lowest CC that is supported by the compiler gives you both forward and backward compatibility (with nearly no loss in performance - for my application).
yes, that was a typo, but that did not explain the unexpected findings - which is why a block size of 4 gives me higher speed (and doubled active blocks)
The proper way to build a fat binary is to include machine code for all architectures that need to be supported plus PTX for the latest GPU architecture. The inclusion of PTX then allows the code to run on future architectures.
In the MCX repository on GitHub, which file contains the code you are examining in this forum thread?
yes, register has always been the bottleneck of this code, although, in the past, we have made several attempt to offload the registers to shared memory, but disappointingly, there was marginal, sometimes slightly negative, speed improvement. for example, these few lines offload 3 register arrays (15 floats) to shared memory
but the speed was nearly no different, so we had to revert those changes. it was quite frustrating.
sometimes if I swap a frequently used register to the shared memory, I can see slight speed decrease.
no, it is completely fp32. I only used 64bit integers for random number generator, and intentionally avoided all double math for speed and portability.
pretty much everything related to the computation is in the first 1375 lines of this unit, the only other .cu file included in this file is the additional RNG unit
also, according to nvvp, this device function was the biggest hotspot, which has been heavily optimized (including some of your feedback on this forum)
Looking at the code in mcx_core.cu I get a strange feeling of dejavu. Is it possible we have discussed this code in these forums previously?
The high register count is likely simply owed to the complexity of the code. I do not immediately see any instances of inadvertent double-precision computation, but it might make sense to disassemble the binary to confirm.
If we did indeed discuss this code before, I probably recommended some review of transcendental function usage, such as sincosf() vs sincospif(), which can help reduce register pressure (as sin, cos, sincos have a “fat” slow-path that is hardly ever used but requires additional registers; this is not needed for sinpi, cospi, sincospi). If the code is routinely compiled with -use_fast_math this shouldn’t matter, though.
Does the profiler indicate that the code is compute limited?
yes, I’ve asked many questions in the past, and got a lot of help from you folks (including a bug we found back in 2016, where we had 10x slowdown, and lately fixed by an driver update)
nvvp confirms with 0 double precision unit utilization.
mcx uses -use_fast_math by default, but I don’t think I know this difference, thanks for sharing
yes, nvvp shows that this kernel is compute bound.
memory dependency previously accounts only for 5% of the total latency, but recently doubled to 11% due to a necessary change.
the “invalid device symbol” error I mentioned earlier was from running a binary compiled with “-arch=sm_30 -code=sm_30 -code=sm_35 -code=sm_50 -code=sm_52 -code=sm_61” on sm_70.