Hi,
I’m working on a small tutorial with nvfortran and openmp offloading.
I’m using my laptop with a T600 nvidia GPU.
Using:
!$omp target teams distribute parallel do simd
so with default choices is obviously less efficiant than specifying
!$omp target teams distribute parallel do simd num_teams(16)
My small example shows 47s versus 37s with num_teams(16)
But I do not found how to properly select the right value for num_teams.
Any advices ?
Thanks
In general, it’s best not to set num_teams and instead let the runtime determine the schedule based on the loop trip count. The cases on when to use “num_teams” will be dependent on the algorithm and loop trip count.
Reducing the number of teams will move more work to each thread, but reduce the number of Streaming Multiprocessors (SM) used. So if there’s not much work in the loop itself or the trip count is small, it may be better to reduce the number of teams so each thread executes multiple iterations. Though for loops with more work, it may be better to use more teams to spread that work out across more SMs.
Basically, there’s not really a good method to determine what, if any, number of teams to use. It’s more of tuning issue which needs to be done via experimentation. However care must be taken as to not tune to a particular workload.
Personally I rarely set the number teams. It’s often only useful in small examples. Not that you shouldn’t introduce the concept to your students, I’d stress that it’s a tuning option that may or may not help.
Thanks Mat for these details.
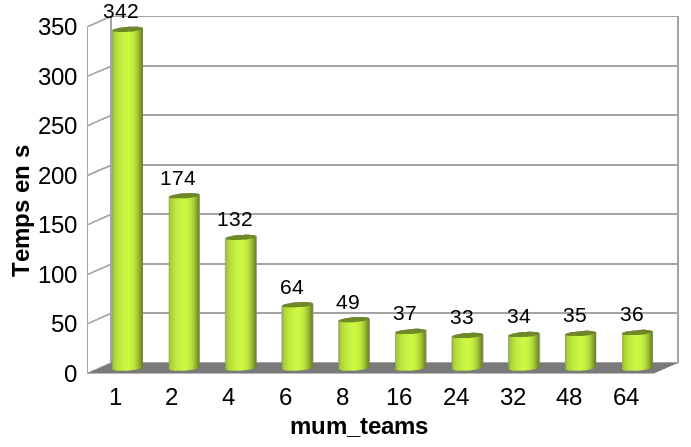
Indeed I was showing the same example with OpenACC and with OpenMP using nvhpc/22.11. A small, basic, example of Laplace solver. OpenMP version was 47s while OpenACC version was 35s (so +34% for openMP offloading). Okay, it is a small and very specific problem as you mention, but to introduce the interest of GPU offloading to beginers it was anoying. Problem size was 2000x2000 and convergence is reached after 23000 iterations.
Running the code with OMP_DISPLAY_ENV=TRUE shows:
OMP_NUM_TEAMS='0'
OMP_NUM_TEAMS_DEV_0='0'
...
OMP_NUM_TEAMS_DEV_14='0'
OMP_NUM_TEAMS_DEV_15='0'
so I tryied to set manualy OMP_NUM_TEAMS to a specific value (see the full test below). 16, at first, then 24 which seams better. It looks like the default choice was 8.
Not sure it is the best [global] approach after reading your answer! Even if with OpenACC the compiler seams to be more efficient in it’s choices than with OpenMP on this small T600 GPU.
What happens if you use “loop” instead of “distribute”? i.e
!$omp target teams loop
instead of
!$omp target teams distribute parallel do
While more restrictive, “loop” is more OpenACC like where it allows the compiler to do better scheduling. With “distribute”, the offload region is outlined with scheduling left to the runtime where it doesn’t have as much information.
Hi Mat,
using
!$omp target teams loop collapse(2)
instead of
!$omp target teams distribute parallel do simd collapse(2)
is a significantly faster (40s instead of 47) even if it remains slower than with the OpenACC approach (35s):
!$acc parallel loop collapse(2)
Patrick