I am trying to use streams on cuda 10.1 to parallelize blocks of 16x16 threads in a grid of 4x1
I call createStream on the elements of an array of cudaStream_t and get a separate value for each.
The code runs slow but the NSight Systems 2019.5.1 is a bit vauge.
For some reason there are 2 contexts and it looks like the single variable streams exist and the ones in the array are all given the same number. I will try and type the text, there is no cut-n-paste…the v and > are the tree arrows
> CPU(56)
v processes(2)
v [21076]mtcnn_p2.exe
> threads (144)
v CUDA (GeForce RTX 2080 Ti, 0000:02:00:0)
v 1.4% Context 1
v 82.0% Stream 10
v 100% Memory
100.0% HtoD memcpy //32 bytes - 2us. Should be before each kernel call on each stream but all show stream 10
v 7.4% Stream 14
100.0% Kernels BGRAsurfaceWriteKernel 36us
v 7.4% Default stream (7)
> 82.0% Kernels
> 17.9% Memory
11.2% HtoD
88.8% DtoD
v 3.2% Stream 151
v 100% memory
100.0% DtoA memcpy
v 98.6% Context 2 with tooltip "Combined view with less than 1% impact"
100.0% other kernels
This second context is the work that needs to be parallelized accros streams
Each kernel launch of <<< [4,1],[16,16],0, stream>>> has a unique id on the call.
But in this view they all show the same stream ID???
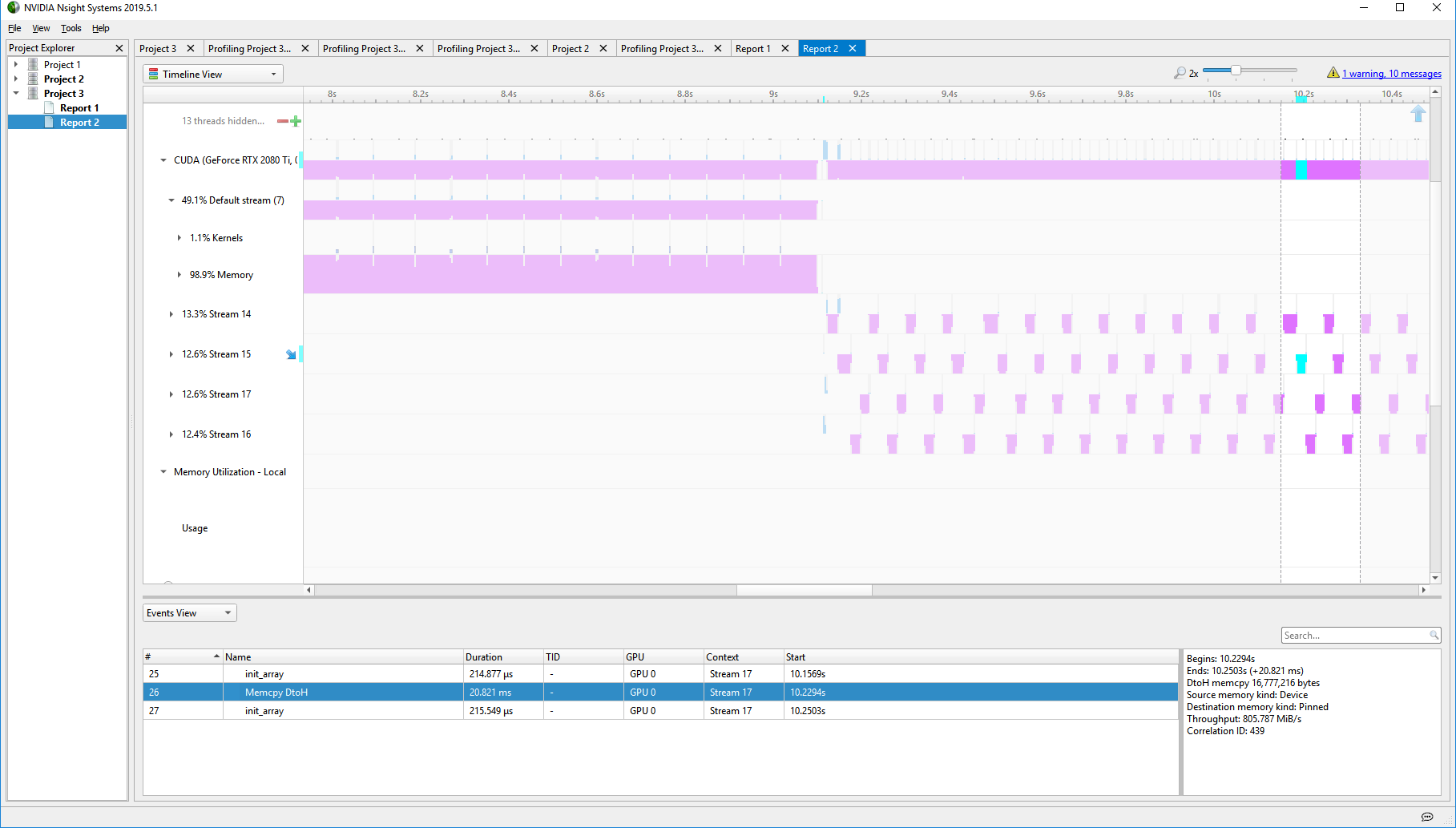
In the events view there is a column called Context with “Stream 2147483647” on every kernel and they are shown run completely one after the other stretching the work out.
Now obviously 2147483647 is -1 on signed MAXINT :-(
I have spent many, many hours and tried the defines and flags for different stream default thread stuff and none seems to work.
If it wasn’t running so damn slow, I might think the tool is just collapsing the stream view and hiding all the stream id’s into a -1.
Also the stream is a memcpy and a launch and instead of 1 of each on each stream, I see all the memcpy colected into stream 10 and all the GetBlockImagePatchesFromTextureKernel on the -1 stream in “Context 2”
Any insight.(no pun) would be greatly appreciated!
//load balance blocks across device streams to memic the automagic grid style of programming.
void InferSubContext::DeBlockImage(unsigned horizblocks, unsigned vertblocks)
{
for (auto i = 0; i < DEVICE_STREAMS; ++i)
checkCudaErrors(cudaStreamCreate(&m_streamPool[i]));
m_deblocking = true;
//cudaStream_t deblockingstream;
//checkCudaErrors(cudaStreamCreate(&deblockingstream));
checkCudaErrors(cudaPeekAtLastError());
for ( auto blockNdx = 0; blockNdx < m_blocksToAnalyze; blockNdx += MINI_GRID_SIZE)
{
auto streamID = blockNdx % DEVICE_STREAMS;
checkCudaErrors(cudaPeekAtLastError());
std::shared_ptr<Block> gridBlocks[MINI_GRID_SIZE];
//cudaStream_t stream = GetNextStream();
checkCudaErrors(cudaPeekAtLastError());
for (auto b = 0; b < MINI_GRID_SIZE; ++b)
{
auto vb = (blockNdx + b) / horizblocks;
auto hb = (blockNdx + b) % horizblocks;
checkCudaErrors(cudaPeekAtLastError());
gridBlocks[b] = m_parent.m_blockPool.Aquire(hb, vb, m_scale, m_streamPool[streamID]);
checkCudaErrors(cudaPeekAtLastError());
m_bptr[b] = (float*)gridBlocks[b]->m_buffers.input;
}
checkCudaErrors(cudaPeekAtLastError());
//copy array of device pointers to device array of device pointers so kernel can access them.
checkCudaErrors(cudaMemcpyAsync(m_d_bptr, m_bptr, MINI_GRID_SIZE * sizeof(float*), cudaMemcpyHostToDevice, m_streamPool[streamID]));
GetBlockImagePatchesFromTexture(m_parent.m_tex, m_resolution.width, m_resolution.height, m_scale,
dim3(MINI_GRID_SIZE,1,1), dim3(BLOCK_DIM_X, BLOCK_DIM_Y,1), PNET_STRIDE_X, PNET_PATCH_SIZE,
m_d_bptr, m_streamPool[streamID]);
checkCudaErrors(cudaPeekAtLastError());
for (auto b = 0; b < MINI_GRID_SIZE; ++b)
{
checkCudaErrors(cudaPeekAtLastError());
//printf("Queuing block[%d,%d] from scale %f \n", gridBlocks[b]->m_key.hBlockNdx, gridBlocks[b]->m_key.vBlockNdx, gridBlocks[b]->m_scale);
m_blockQueue.Push(gridBlocks[b],true); //silent push does not signal consumer, Batch optimization.
checkCudaErrors(cudaPeekAtLastError());
}
m_blockQueue.Signal(); //batch is ready, signal it
}
for (auto i = 0; i < DEVICE_STREAMS; ++i)
checkCudaErrors(cudaStreamDestroy(m_streamPool[i]));
m_deblocking = false;
}
Becasue of the large amount of time it takes to create a stream, I tried to have a container, vector or array of the opaque handles cudaStream_t in the class and a GetNextStream() to load balance the launches across streams, but while I could have a cudaStream_t variable every time I tried to do anything other than simple member variable in class or array in local scope, the launch fails with invalid resource(400) is there something special about streams or is this a deviceptr vs hostpointer issue and the array declared locally is somehow a devicearray and as a member of the class not?
I think I need to add that I am using nvcc integrated into Visual Studio. I am on Windows.
windows 10
visual studio 2017 and 2019 using vc140
Nsight Systems 2019.5.1
cuda 10.1
I think this is what I am seeing and while I am now down to .4% default stream it is from the nvdec example code I am using to decode the frame before running my block of streams.
I have gotten rid of all default stream and created all streams locally with flags non-blocking.
Still there are 2 contexts, and all the pinned-and-async memcpys (supposed to be before each launch on same stream are in one context and all the kernels in another. very little parallelism of the launches.
Out of the box test of the simpleStreams example shows there may be an issue on windows 10. Is there a regression test suite on a server somewhere I can check results against?
[ simpleStreams ]
Device synchronization method set to = 0 (Automatic Blocking)
Setting reps to 100 to demonstrate steady state
> GPU Device 0: "GeForce RTX 2080 Ti" with compute capability 7.5
Device: <GeForce RTX 2080 Ti> canMapHostMemory: Yes
> CUDA Capable: SM 7.5 hardware
> 68 Multiprocessor(s) x 64 (Cores/Multiprocessor) = 4352 (Cores)
> scale_factor = 1.0000
> array_size = 16777216
> Using CPU/GPU Device Synchronization method (cudaDeviceScheduleAuto)
> VirtualAlloc() allocating 64.00 Mbytes of (generic page-aligned system memory)
> cudaHostRegister() registering 64.00 Mbytes of generic allocated system memory
Starting Test
memcopy: 92.16
kernel: 0.86
non-streamed: 83.13
4 streams: 83.58
-------------------------------
The difference here is the stream Ids are correct and it shows the stair-step like pattern.
The left of the screen is the default stream and the right side is the streamed version.
The reason this is not an improvement is that it is copy(30ms) dominate, the kernels run too fast(215us) on this hardware for the overlap to outweigh the launch overhead?
Example not appropriate for this Hardware but it shows me that it is possible on windows and if I compare the projects, maybe I will find the thorn.
So not much help there either.
When I zoom in there is a kernel run then a long delay waiting for the single DMA engine to become avail then a very quick warmed up kernel, then wait there is very little overlap becasue of the ratio of blocked waits to kernel time. I increased the number of streams in the example but it gets worse. I think the work goes up, same copy size so increasing streams does not chew thru the data faster, it just increases the amount of data. (Misleading test)
runs nreps worth of kernels, seems to reduce data on number of streams but runs nreps* number of streams worth of work. ROTFL unless I am reading it wrong. I need lunch.
OMG why is the NSight Systems UI so bad on windows, does anyone check this stuff on windows?
Absolutly no spaces allowed in path even the one it puts in there in quotes when sleected.
Note about working path not same as executable caused by this
Typing in the input field is seconds per keystroke, looks like it is saving config every keystroke
All samples installed on windows have spaces in paths.
Right. kinda an anti-sample in that is showing that streams do not help at all if the kernel is fast and you are a significantly memcpy bound process. Since you cannot overlap the memcpy’s
Witnessing kernel concurrency (which I guess is what you are after) is hard. It requires simultaneously that the kernel has a long execution time but that it is also “low” in the consumption of CUDA execution resources (so that other kernels can reasonably coexist with it.)
Kernel concurrency is not a panacea, and IMO is a less favorable design choice or strategy for CUDA efficiency, if there is any alternate way to structure the work so that enough work can be issued to the GPU to saturate the GPU, per kernel call. This latter approach is generally much more efficient, in my experience. Using kernel concurrency to saturate the GPU should be a last-ditch option. Just expressing my opinions here, as is true of everything I say on the forums.
And I’m not sure how kernel concurrency would help with a “memcpy bound process”. Overlap of copy and compute is only an interesting optimization when the compute duration is in the same ballpark as the copy duration. If the copy operations in your code are 90% of the timeline, and the compute operations are 10% of the timeline, little is to be gained by overlapping them. Best improvement can be witnessed when they are approximately equal, and then it is at most 2X (or 3X if we consider a balanced case of all 3 operations: H->D, kernel, D->H).
My process is not memory bound, (yet) I am trying to even see parallelism. Unlike the last 2 posts showing the profile of the sample, my code is NOT showing streams at all. All my kernels are being thrown into a context2 and executed one after another.
I am trying to keep GPU data on the GPU and avoid excessive allocation.
So here is the goal/problem/flow
extract h264 encoded 1920x1080 frame from bitstream
=====================PCI Bus========================
NvDec decodes to NV12
Convert to RGB and load to surface-cudaArray-texture
This texture persists and is used until the next frame arrives in 33-66ms
The goal is to send 12x12x3 image patches on a stride of 2 to a neuralnet
You see how parallel this can be 1920x1080 at a stride of 2 is 960x540 12x12x3 image patches
518,400 calls to the first stage of the neural net (and 895MB of GPU memory)
Instead the plan is to use a pool of “blocks” that hold pointers to the 16x16 threads worth of buffers.
The pool size will be related to the number of SM’s to keep the pipeline saturated.
This is simultanously done for 6-8 scaled versions of the original image by subsampling the texture with interpolation.
The HtoD writes during this time period are the array of device pointers to buffers for each block pulled from the queue.
The patches are sent to cudnn in a batch of 4 blocks*256 threads
Since the blocks persist the array of pointers(only 36bytes) to image patches and are reused as the pipeline reloads, it avoids a bursty allocation and will allow it to work on the jetson and the rtx 2080
The 1920x1080 is the worst case quantity, but I want to do many of them.
=====================PCI Bus========================
Copy back across the bus the very tiny arrays of bounding box coordinates.
In reviewing the common pitfalls, I think I see some areas of concern to address.
For anyone that ends up here, the issue with no stream parallelism was caused by the 2nd context visible in the nsight screenshot. That -1 stream ID and 2nd context are the clues.
I used the NvDecoder deviceAPI example to decode a frame for analysis and when it passes the frame to the code that does the runtime api kernel launch the runtime api lazily creates the Primary ctx. This resets and wipes out some important things but then I have 2 contexts.
with the memcpy and kernel launch in the same stream, All the memcpy’s run in the device context and all the kernel with a stream id as -1 are clumped together in the 2nd Primary Context.
It is a combination of the hiding of the context and the lazy creation in the runtime api together with the new NSIGHT tool redesigned interface that got me.
THE SOLUTION:
Put a cudaSetDevice(0) in the class using the runtime api to have them use the same context.
When you only have one device and are working of the samples it is a surprise to have this kind of fail by default.
Is there anyway to get the NSight System tool to put the items in a stream in order instead of separating into memory and kernel? and/or turn off the multiple summaries? the line which creates a redundent copy is also separated. (my display is 16:9 not 9:160)