Hello,
I am currently implementing an algorithm were I am using cuTensorNet to contract and qr decompose some tensors. I have implemented the contraction in a way, that the contraction plans, allocation and everything else is done separately beforehand and then I basically only call cutensornetContractSlices on two different tensors with two different streams. However I have noticed while profiling, that the kernels for the contraction are still called sequentially. Here is a example, this is basically the cutensornet_example just with everything twice:
/*
* Copyright (c) 2021-2023, NVIDIA CORPORATION & AFFILIATES.
*
* SPDX-License-Identifier: BSD-3-Clause
*/
// Sphinx: #1
#include <stdlib.h>
#include <stdio.h>
#include <unordered_map>
#include <vector>
#include <cassert>
#include <cuda_runtime.h>
#include <cutensornet.h>
#define HANDLE_ERROR(x) \
{ const auto err = x; \
if( err != CUTENSORNET_STATUS_SUCCESS ) \
{ printf("Error: %s in line %d\n", cutensornetGetErrorString(err), __LINE__); \
fflush(stdout); \
} \
};
#define HANDLE_CUDA_ERROR(x) \
{ const auto err = x; \
if( err != cudaSuccess ) \
{ printf("CUDA Error: %s in line %d\n", cudaGetErrorString(err), __LINE__); \
fflush(stdout); \
} \
};
struct GPUTimer
{
GPUTimer(cudaStream_t stream): stream_(stream)
{
cudaEventCreate(&start_);
cudaEventCreate(&stop_);
}
~GPUTimer()
{
cudaEventDestroy(start_);
cudaEventDestroy(stop_);
}
void start()
{
cudaEventRecord(start_, stream_);
}
float seconds()
{
cudaEventRecord(stop_, stream_);
cudaEventSynchronize(stop_);
float time;
cudaEventElapsedTime(&time, start_, stop_);
return time * 1e-3;
}
private:
cudaEvent_t start_, stop_;
cudaStream_t stream_;
};
int main()
{
static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
bool verbose = true;
// Check cuTensorNet version
const size_t cuTensornetVersion = cutensornetGetVersion();
if(verbose)
printf("cuTensorNet version: %ld\n", cuTensornetVersion);
// Set GPU device
int numDevices {0};
HANDLE_CUDA_ERROR( cudaGetDeviceCount(&numDevices) );
const int deviceId = 0;
HANDLE_CUDA_ERROR( cudaSetDevice(deviceId) );
cudaDeviceProp prop;
HANDLE_CUDA_ERROR( cudaGetDeviceProperties(&prop, deviceId) );
if(verbose) {
printf("===== device info ======\n");
printf("GPU-name:%s\n", prop.name);
printf("GPU-clock:%d\n", prop.clockRate);
printf("GPU-memoryClock:%d\n", prop.memoryClockRate);
printf("GPU-nSM:%d\n", prop.multiProcessorCount);
printf("GPU-major:%d\n", prop.major);
printf("GPU-minor:%d\n", prop.minor);
printf("t:%d\n", prop.textureAlignment);
printf("========================\n");
}
typedef float floatType;
cudaDataType_t typeData = CUDA_R_32F;
cutensornetComputeType_t typeCompute = CUTENSORNET_COMPUTE_32F;
if(verbose)
printf("Included headers and defined data types\n");
// Sphinx: #2
/**********************
* Computing: R_{k,l} = A_{a,b,c,d,e,f} B_{b,g,h,e,i,j} C_{m,a,g,f,i,k} D_{l,c,h,d,j,m}
**********************/
constexpr int32_t numInputs = 4;
// Create vectors of tensor modes
std::vector<int32_t> modesA{'a','b','c','d','e','f'};
std::vector<int32_t> modesB{'b','g','h','e','i','j'};
std::vector<int32_t> modesC{'m','a','g','f','i','k'};
std::vector<int32_t> modesD{'l','c','h','d','j','m'};
std::vector<int32_t> modesR{'k','l'};
// Set mode extents
std::unordered_map<int32_t, int64_t> extent;
extent['a'] = 16;
extent['b'] = 16;
extent['c'] = 16;
extent['d'] = 16;
extent['e'] = 16;
extent['f'] = 16;
extent['g'] = 16;
extent['h'] = 16;
extent['i'] = 16;
extent['j'] = 16;
extent['k'] = 16;
extent['l'] = 16;
extent['m'] = 16;
// Create a vector of extents for each tensor
std::vector<int64_t> extentA;
for (auto mode : modesA)
extentA.push_back(extent[mode]);
std::vector<int64_t> extentB;
for (auto mode : modesB)
extentB.push_back(extent[mode]);
std::vector<int64_t> extentC;
for (auto mode : modesC)
extentC.push_back(extent[mode]);
std::vector<int64_t> extentD;
for (auto mode : modesD)
extentD.push_back(extent[mode]);
std::vector<int64_t> extentR;
for (auto mode : modesR)
extentR.push_back(extent[mode]);
if(verbose)
printf("Defined tensor network, modes, and extents\n");
// Sphinx: #3
/**********************
* Allocating data
**********************/
size_t elementsA = 1;
for (auto mode : modesA)
elementsA *= extent[mode];
size_t elementsB = 1;
for (auto mode : modesB)
elementsB *= extent[mode];
size_t elementsC = 1;
for (auto mode : modesC)
elementsC *= extent[mode];
size_t elementsD = 1;
for (auto mode : modesD)
elementsD *= extent[mode];
size_t elementsR = 1;
for (auto mode : modesR)
elementsR *= extent[mode];
size_t sizeA = sizeof(floatType) * elementsA;
size_t sizeB = sizeof(floatType) * elementsB;
size_t sizeC = sizeof(floatType) * elementsC;
size_t sizeD = sizeof(floatType) * elementsD;
size_t sizeR = sizeof(floatType) * elementsR;
if(verbose)
printf("Total GPU memory used for tensor storage: %.2f GiB\n",
(sizeA + sizeB + sizeC + sizeD + sizeR) / 1024. /1024. / 1024);
void* rawDataIn_d[numInputs];
void* R_d;
HANDLE_CUDA_ERROR( cudaMalloc((void**) &rawDataIn_d[0], sizeA) );
HANDLE_CUDA_ERROR( cudaMalloc((void**) &rawDataIn_d[1], sizeB) );
HANDLE_CUDA_ERROR( cudaMalloc((void**) &rawDataIn_d[2], sizeC) );
HANDLE_CUDA_ERROR( cudaMalloc((void**) &rawDataIn_d[3], sizeD) );
HANDLE_CUDA_ERROR( cudaMalloc((void**) &R_d, sizeR));
void* rawDataIn_d2[numInputs];
void* R_d2;
HANDLE_CUDA_ERROR( cudaMalloc((void**) &rawDataIn_d2[0], sizeA) );
HANDLE_CUDA_ERROR( cudaMalloc((void**) &rawDataIn_d2[1], sizeB) );
HANDLE_CUDA_ERROR( cudaMalloc((void**) &rawDataIn_d2[2], sizeC) );
HANDLE_CUDA_ERROR( cudaMalloc((void**) &rawDataIn_d2[3], sizeD) );
HANDLE_CUDA_ERROR( cudaMalloc((void**) &R_d2, sizeR));
floatType *A = (floatType*) malloc(sizeof(floatType) * elementsA);
floatType *B = (floatType*) malloc(sizeof(floatType) * elementsB);
floatType *C = (floatType*) malloc(sizeof(floatType) * elementsC);
floatType *D = (floatType*) malloc(sizeof(floatType) * elementsD);
floatType *R = (floatType*) malloc(sizeof(floatType) * elementsR);
if (A == NULL || B == NULL || C == NULL || D == NULL || R == NULL)
{
printf("Error: Host memory allocation failed!\n");
return -1;
}
/*******************
* Initialize data
*******************/
memset(R, 0, sizeof(floatType) * elementsR);
for (uint64_t i = 0; i < elementsA; i++)
A[i] = ((floatType) rand()) / RAND_MAX;
for (uint64_t i = 0; i < elementsB; i++)
B[i] = ((floatType) rand()) / RAND_MAX;
for (uint64_t i = 0; i < elementsC; i++)
C[i] = ((floatType) rand()) / RAND_MAX;
for (uint64_t i = 0; i < elementsD; i++)
D[i] = ((floatType) rand()) / RAND_MAX;
HANDLE_CUDA_ERROR( cudaMemcpy(rawDataIn_d[0], A, sizeA, cudaMemcpyHostToDevice) );
HANDLE_CUDA_ERROR( cudaMemcpy(rawDataIn_d[1], B, sizeB, cudaMemcpyHostToDevice) );
HANDLE_CUDA_ERROR( cudaMemcpy(rawDataIn_d[2], C, sizeC, cudaMemcpyHostToDevice) );
HANDLE_CUDA_ERROR( cudaMemcpy(rawDataIn_d[3], D, sizeD, cudaMemcpyHostToDevice) );
HANDLE_CUDA_ERROR( cudaMemcpy(rawDataIn_d2[0], A, sizeA, cudaMemcpyHostToDevice) );
HANDLE_CUDA_ERROR( cudaMemcpy(rawDataIn_d2[1], B, sizeB, cudaMemcpyHostToDevice) );
HANDLE_CUDA_ERROR( cudaMemcpy(rawDataIn_d2[2], C, sizeC, cudaMemcpyHostToDevice) );
HANDLE_CUDA_ERROR( cudaMemcpy(rawDataIn_d2[3], D, sizeD, cudaMemcpyHostToDevice) );
if(verbose)
printf("Allocated GPU memory for data, and initialize data\n");
// Sphinx: #4
/*************************
* cuTensorNet
*************************/
cudaStream_t stream;
cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking);
cudaStream_t stream2;
cudaStreamCreateWithFlags(&stream2, cudaStreamNonBlocking);
// cudaStreamCreate(&stream2);
cutensornetHandle_t handle;
HANDLE_ERROR( cutensornetCreate(&handle) );
cutensornetHandle_t handle2;
HANDLE_ERROR( cutensornetCreate(&handle2) );
const int32_t nmodeA = modesA.size();
const int32_t nmodeB = modesB.size();
const int32_t nmodeC = modesC.size();
const int32_t nmodeD = modesD.size();
const int32_t nmodeR = modesR.size();
/*******************************
* Create Network Descriptor
*******************************/
const int32_t* modesIn[] = {modesA.data(), modesB.data(), modesC.data(), modesD.data()};
int32_t const numModesIn[] = {nmodeA, nmodeB, nmodeC, nmodeD};
const int64_t* extentsIn[] = {extentA.data(), extentB.data(), extentC.data(), extentD.data()};
const int64_t* stridesIn[] = {NULL, NULL, NULL, NULL}; // strides are optional; if no stride is provided, cuTensorNet assumes a generalized column-major data layout
// Set up tensor network
cutensornetNetworkDescriptor_t descNet;
HANDLE_ERROR( cutensornetCreateNetworkDescriptor(handle,
numInputs, numModesIn, extentsIn, stridesIn, modesIn, NULL,
nmodeR, extentR.data(), /*stridesOut = */NULL, modesR.data(),
typeData, typeCompute,
&descNet) );
cutensornetNetworkDescriptor_t descNet2;
HANDLE_ERROR( cutensornetCreateNetworkDescriptor(handle2,
numInputs, numModesIn, extentsIn, stridesIn, modesIn, NULL,
nmodeR, extentR.data(), /*stridesOut = */NULL, modesR.data(),
typeData, typeCompute,
&descNet2) );
if(verbose)
printf("Initialized the cuTensorNet library and created a tensor network descriptor\n");
// Sphinx: #5
/*******************************
* Choose workspace limit based on available resources.
*******************************/
size_t freeMem, totalMem;
HANDLE_CUDA_ERROR( cudaMemGetInfo(&freeMem, &totalMem) );
uint64_t workspaceLimit = (uint64_t)((double)freeMem * 0.9);
if(verbose)
printf("Workspace limit = %lu\n", workspaceLimit);
/*******************************
* Find "optimal" contraction order and slicing
*******************************/
cutensornetContractionOptimizerConfig_t optimizerConfig;
HANDLE_ERROR( cutensornetCreateContractionOptimizerConfig(handle, &optimizerConfig) );
// Set the desired number of hyper-samples (defaults to 0)
int32_t num_hypersamples = 8;
HANDLE_ERROR( cutensornetContractionOptimizerConfigSetAttribute(handle,
optimizerConfig,
CUTENSORNET_CONTRACTION_OPTIMIZER_CONFIG_HYPER_NUM_SAMPLES,
&num_hypersamples,
sizeof(num_hypersamples)) );
// Create contraction optimizer info and find an optimized contraction path
cutensornetContractionOptimizerInfo_t optimizerInfo;
HANDLE_ERROR( cutensornetCreateContractionOptimizerInfo(handle, descNet, &optimizerInfo) );
cutensornetContractionOptimizerInfo_t optimizerInfo2;
HANDLE_ERROR( cutensornetCreateContractionOptimizerInfo(handle2, descNet2, &optimizerInfo2) );
HANDLE_ERROR( cutensornetContractionOptimize(handle,
descNet,
optimizerConfig,
workspaceLimit,
optimizerInfo) );
HANDLE_ERROR( cutensornetContractionOptimize(handle2,
descNet2,
optimizerConfig,
workspaceLimit,
optimizerInfo2) );
if(verbose)
printf("Found an optimized contraction path using cuTensorNet optimizer\n");
// Sphinx: #6
/*******************************
* Create workspace descriptor, allocate workspace, and set it.
*******************************/
cutensornetWorkspaceDescriptor_t workDesc;
HANDLE_ERROR( cutensornetCreateWorkspaceDescriptor(handle, &workDesc) );
int64_t requiredWorkspaceSize = 0;
HANDLE_ERROR( cutensornetWorkspaceComputeContractionSizes(handle,
descNet,
optimizerInfo,
workDesc) );
HANDLE_ERROR( cutensornetWorkspaceGetMemorySize(handle,
workDesc,
CUTENSORNET_WORKSIZE_PREF_MIN,
CUTENSORNET_MEMSPACE_DEVICE,
CUTENSORNET_WORKSPACE_SCRATCH,
&requiredWorkspaceSize) );
void* work = nullptr;
HANDLE_CUDA_ERROR( cudaMalloc(&work, requiredWorkspaceSize) );
HANDLE_ERROR( cutensornetWorkspaceSetMemory(handle,
workDesc,
CUTENSORNET_MEMSPACE_DEVICE,
CUTENSORNET_WORKSPACE_SCRATCH,
work,
requiredWorkspaceSize) );
cutensornetWorkspaceDescriptor_t workDesc2;
HANDLE_ERROR( cutensornetCreateWorkspaceDescriptor(handle2, &workDesc2) );
HANDLE_ERROR( cutensornetWorkspaceComputeContractionSizes(handle2,
descNet2,
optimizerInfo2,
workDesc2) );
HANDLE_ERROR( cutensornetWorkspaceGetMemorySize(handle2,
workDesc2,
CUTENSORNET_WORKSIZE_PREF_MIN,
CUTENSORNET_MEMSPACE_DEVICE,
CUTENSORNET_WORKSPACE_SCRATCH,
&requiredWorkspaceSize) );
void* work2 = nullptr;
HANDLE_CUDA_ERROR( cudaMalloc(&work2, requiredWorkspaceSize) );
HANDLE_ERROR( cutensornetWorkspaceSetMemory(handle2,
workDesc2,
CUTENSORNET_MEMSPACE_DEVICE,
CUTENSORNET_WORKSPACE_SCRATCH,
work2,
requiredWorkspaceSize) );
if(verbose)
printf("Allocated and set up the GPU workspace\n");
// Sphinx: #7
/*******************************
* Initialize the pairwise contraction plan (for cuTENSOR).
*******************************/
cutensornetContractionPlan_t plan;
HANDLE_ERROR( cutensornetCreateContractionPlan(handle,
descNet,
optimizerInfo,
workDesc,
&plan) );
cutensornetContractionPlan_t plan2;
HANDLE_ERROR( cutensornetCreateContractionPlan(handle2,
descNet2,
optimizerInfo,
workDesc2,
&plan2) );
if(verbose)
printf("Created a contraction plan for cuTensorNet and optionally auto-tuned it\n");
// Sphinx: #8
/**********************
* Execute the tensor network contraction
**********************/
// GPUTimer timer {stream};
double minTimeCUTENSORNET = 1e100;
const int numRuns = 1; // number of repeats to get stable performance results
for (int i = 0; i < numRuns; ++i)
{
// HANDLE_CUDA_ERROR( cudaMemcpy(R_d, R, sizeR, cudaMemcpyHostToDevice) ); // restore the output tensor on GPU
// HANDLE_CUDA_ERROR( cudaMemcpy(R_d2, R, sizeR, cudaMemcpyHostToDevice) ); // restore the output tensor on GPU
// HANDLE_CUDA_ERROR( cudaDeviceSynchronize() );
/*
* Contract all slices of the tensor network
*/
// timer.start();
int32_t accumulateOutput = 0; // output tensor data will be overwritten
HANDLE_ERROR( cutensornetContractSlices(handle,
plan,
rawDataIn_d,
R_d,
accumulateOutput,
workDesc,
NULL, // alternatively, NULL can also be used to contract over all slices instead of specifying a sliceGroup object
stream) );
HANDLE_ERROR( cutensornetContractSlices(handle2,
plan2,
rawDataIn_d2,
R_d2,
accumulateOutput,
workDesc2,
NULL, // alternatively, NULL can also be used to contract over all slices instead of specifying a sliceGroup object
stream2) );
// Synchronize and measure best timing
// auto time = timer.seconds();
// minTimeCUTENSORNET = (time > minTimeCUTENSORNET) ? minTimeCUTENSORNET : time;
}
if(verbose)
printf("Contracted the tensor network, each slice used the same contraction plan\n");
// Print the 1-norm of the output tensor (verification)
HANDLE_CUDA_ERROR( cudaStreamSynchronize(stream) );
HANDLE_CUDA_ERROR( cudaStreamSynchronize(stream2) );
HANDLE_CUDA_ERROR( cudaMemcpy(R, R_d, sizeR, cudaMemcpyDeviceToHost) ); // restore the output tensor on Host
double norm1 = 0.0;
for (int64_t i = 0; i < elementsR; ++i) {
norm1 += std::abs(R[i]);
}
if(verbose)
printf("Computed the 1-norm of the output tensor: %e\n", norm1);
// printf("Tensor network contraction time (ms) = %.3f\n", minTimeCUTENSORNET * 1000.f);
/*************************/
// Query the total Flop count for the tensor network contraction
double flops {0.0};
HANDLE_ERROR( cutensornetContractionOptimizerInfoGetAttribute(
handle,
optimizerInfo,
CUTENSORNET_CONTRACTION_OPTIMIZER_INFO_FLOP_COUNT,
&flops,
sizeof(flops)) );
HANDLE_ERROR( cutensornetDestroyContractionPlan(plan) );
HANDLE_ERROR( cutensornetDestroyWorkspaceDescriptor(workDesc) );
HANDLE_ERROR( cutensornetDestroyContractionOptimizerInfo(optimizerInfo) );
HANDLE_ERROR( cutensornetDestroyContractionOptimizerConfig(optimizerConfig) );
HANDLE_ERROR( cutensornetDestroyNetworkDescriptor(descNet) );
HANDLE_ERROR( cutensornetDestroy(handle) );
// Free Host memory resources
if (R) free(R);
if (D) free(D);
if (C) free(C);
if (B) free(B);
if (A) free(A);
// Free GPU memory resources
if (work) cudaFree(work);
if (R_d) cudaFree(R_d);
if (rawDataIn_d[0]) cudaFree(rawDataIn_d[0]);
if (rawDataIn_d[1]) cudaFree(rawDataIn_d[1]);
if (rawDataIn_d[2]) cudaFree(rawDataIn_d[2]);
if (rawDataIn_d[3]) cudaFree(rawDataIn_d[3]);
if(verbose)
printf("Freed resources and exited\n");
return 0;
}
When profiling I see this:
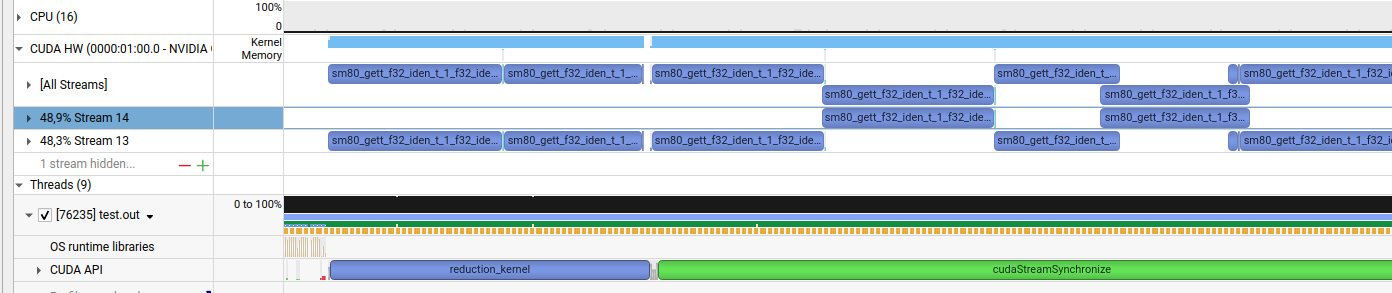
I assume the sm80_gett… Kernels are the internal Kernels used to contract the tensors.
Why are the Kernels on stream 13 and stream 14 not executed in parallel? I noticed the same thing when doing 2 qr decompositions on two different streams. Is this just the way it is in cuTensorNet or am I missing something?

