In other words, if a cudaMemsetAsync command’s issue (the starting point of the bar) happens between two kernel execution commands’ issue, then the execution of two kernels must be serialized (no bar overlap between kernel1 and kernel2). But the execution of cudaMemsetAsync and a kernel can be parallelized.
But I am confused after profiling an inference service that assigns each request handler thread a dedicated CUDA stream. I found scenario 3 happening.
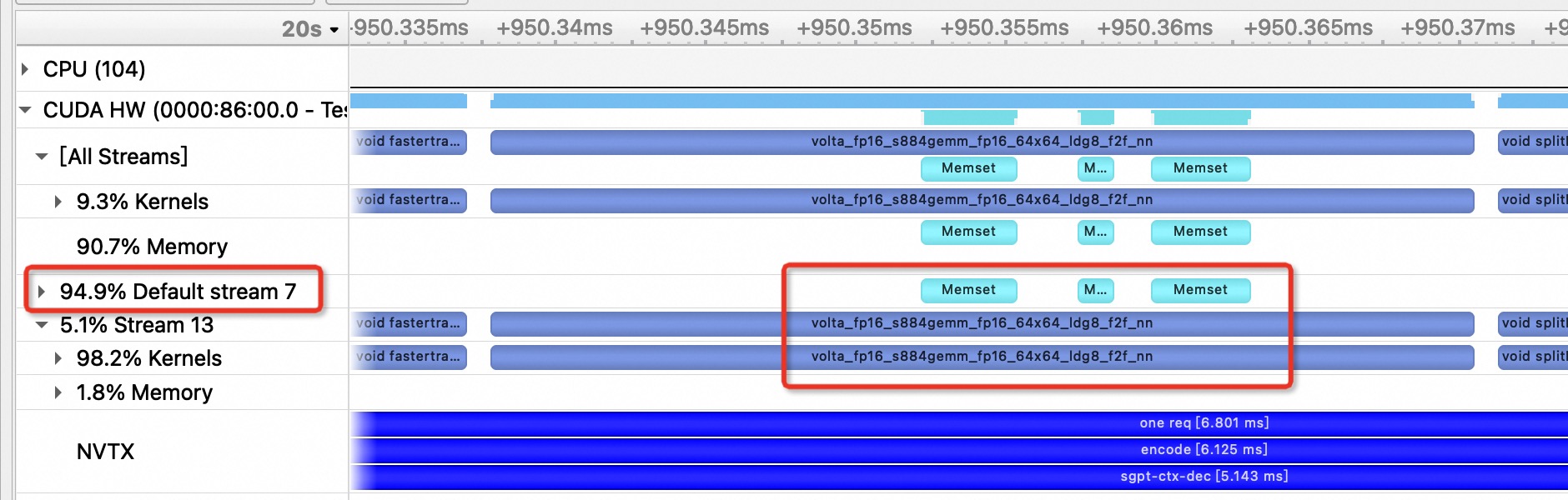
Also, I found a cudaMemsetAsync on the default stream being executed in parallel with another kernel in a different stream. This seems to conflict with this post
no operation in the default stream will begin until all previously issued operations in any stream on the device have completed, and an operation in the default stream must complete before any other operation (in any stream on the device) will begin.
Could you please explain the reason why the behaviors I posted are expected, and clarify a bit more about section 3.2.8.5.3? Any help will be appreciated.
I don’t think it does. I think it includes cudaMemset(). My expectation is that cudaMemsetAsync(), which takes a stream argument, will conform to stream semantics. The description of cudaMemsetAsync makes this very plain, in my opinion:
cudaMemsetAsync()is asynchronous with respect to the host, so the call may return before the memset is complete. The operation can optionally be associated to a stream by passing a non-zero stream argument. If stream is non-zero, the operation may overlap with operations in other streams.
That is possible if the default stream semantics have been changed. See here.
Thanks for your reply! The behavior that the default stream being parallel with other streams turned out to be that I’m using PyTorch, which sets cudaStreamNonBlocking for additional streams and does not sync with the default stream. Ref
I still have some questions though. Is it correct that:
The implicit synchronization section is only about synchronous APIs, in other words, those who don’t follow stream semantic. cudaMemset, cudaMemcpy, cudaMalloc, etc.
Whether an op can start is subject to:
The op order maintained within a stream.
The implicit and explicit synchronization across streams.
For this statement Two commands from different streams cannot run concurrently if any one of the following operations is issued in-between them by the host thread, does it mean this kind of operation can only start after all previously submitted ops ended, and all ops submitted after this kind of op can only start after this op ends? If so, this means other than per stream op order, GPU will also maintain global op submission order internally?
I would certainly expect that any CUDA API call that has the potential to take a stream argument should be able to follow stream semantics, which does not necessarily involve synchronization or blocking of any type.
If you are a beginner, my suggestion is that you don’t make use of the null stream, or any synchronizing API such as cudaMalloc, during any performance critical work-issuance area.
If we focus on stream-able operations, then whether an op can start is entirely determined by 2 rules of stream semantics:
Operations issued into the same stream will execute in issue order. Operation B, issued after operation A, will not begin until A has completed.
Operations issued into different streams have no defined order prescribed by CUDA. Without other information, it is possible that operation B, issued into stream X, may execute before, during, or after operation A, issued into stream Y.
If we layer on null-stream behavior/interaction, then the additional rule is as follows:
An operation issued into a default (ie. non-modified) null stream will not begin until all previous work issued to that device is complete. Furthermore, any operation issued after an operation issued into the null stream cannot begin until the null stream operation is complete. For a modified null stream, this additional rule does not apply. The modified null stream behaves like user-created streams.
All of the above statements have a single device in view. When multiple devices are involved, the work execution is independent, between devices. Any stream of device 0 does not in any way impact any stream on device 1. Even operations issued into the null streams of separate devices can overlap with each other.
The usage of multiple CPU threads, or not, has no bearing on the above statements. The above statements are true whether you issue work from multiple CPU threads, or not.
It means that the operation issued in between, in the delineated list, is issued as if it were a default null stream activity, following the description given above. An ordinary cudaMalloc call falls into this category, for example.
I don’t believe it is necessary to answer that question, and I don’t know what the GPU maintains internally. The rules of stream behavior are as I described, and AFAIK they are sufficient to sort out and predict behavior of the GPU, from the programmer’s perspective.