I have an access pattern that load data from global to shared which is:
#pragma unroll
for (int ax0_ax1_ax2_ax3_0_fused_2 = 0; ax0_ax1_ax2_ax3_0_fused_2 < 2; ++ax0_ax1_ax2_ax3_0_fused_2) {
*(uint4*)(((half*)buf_dyn_shmem) + ((((((int)threadIdx.y) * 1024) + (((int)threadIdx.z) * 512)) + (ax0_ax1_ax2_ax3_0_fused_2 * 256)) + (((int)threadIdx.x) * 8))) = *(uint4*)(A + ((((((((int)blockIdx.y) * 2097152) + (((int)threadIdx.y) * 524288)) + (((int)threadIdx.z) * 262144)) + (ax0_ax1_ax2_ax3_0_fused_2 * 256)) + ((((int)threadIdx.x) & 15) * 16)) + ((((int)threadIdx.x) >> 4) * 8)));
}
#pragma unroll
for (int ax0_ax1_ax2_ax3_0_fused_2_1 = 0; ax0_ax1_ax2_ax3_0_fused_2_1 < 4; ++ax0_ax1_ax2_ax3_0_fused_2_1) {
*(uint4*)(((half*)buf_dyn_shmem) + (((((((int)threadIdx.y) * 2048) + (((int)threadIdx.z) * 1024)) + (ax0_ax1_ax2_ax3_0_fused_2_1 * 256)) + (((int)threadIdx.x) * 8)) + 4096)) = *(uint4*)(B + ((((((((((((int)threadIdx.y) * 256) + (((int)threadIdx.z) * 128)) + (ax0_ax1_ax2_ax3_0_fused_2_1 * 32)) + ((int)threadIdx.x)) >> 9) * 262144) + (((int)blockIdx.x) * 4096)) + (((((((int)threadIdx.y) * 8) + (((int)threadIdx.z) * 4)) + ax0_ax1_ax2_ax3_0_fused_2_1) & 15) * 256)) + ((((int)threadIdx.x) & 15) * 16)) + ((((int)threadIdx.x) >> 4) * 8)));
}
and we can see that this pattern is conflict free because we access shared memory with consective threadIdx.x * 8 (4 banks aligned), the nsight compute profiler show similar results:

However, I wanna to change the copy pattern to cp.async in my gtx 3090 because I wanna save some registers and save bandwidth to achieve a bigger tile? but the performance is not good, and I observed some bank conflict happens in this part, the code is:
extern __shared__ uchar buf_dyn_shmem[];
for (int ax0_ax1_ax2_ax3_0_fused_2 = 0; ax0_ax1_ax2_ax3_0_fused_2 < 2; ++ax0_ax1_ax2_ax3_0_fused_2) {
{
unsigned int addr;
__asm__ __volatile__(
"{ .reg .u64 addr; cvta.to.shared.u64 addr, %1; cvt.u32.u64 %0, addr; }\n"
: "=r"(addr)
: "l"((void *)(buf_dyn_shmem + (((((int)threadIdx.y) * 2048) + (ax0_ax1_ax2_ax3_0_fused_2 * 512)) + (((int)threadIdx.x) * 16))))
);
__asm__ __volatile__(
"cp.async.ca.shared.global.L2::128B [%0], [%1], %2;"
:: "r"(addr), "l"((void*)(A + ((((((((int)blockIdx.y) * 2097152) + (((int)threadIdx.y) * 524288)) + ((ax0_ax1_ax2_ax3_0_fused_2 >> 1) * 262144)) + ((ax0_ax1_ax2_ax3_0_fused_2 & 1) * 256)) + ((((int)threadIdx.x) & 15) * 16)) + ((((int)threadIdx.x) >> 4) * 8)))), "n"(16)
);
}
}
for (int ax0_ax1_ax2_ax3_0_fused_2_1 = 0; ax0_ax1_ax2_ax3_0_fused_2_1 < 8; ++ax0_ax1_ax2_ax3_0_fused_2_1) {
{
unsigned int addr;
__asm__ __volatile__(
"{ .reg .u64 addr; cvta.to.shared.u64 addr, %1; cvt.u32.u64 %0, addr; }\n"
: "=r"(addr)
: "l"((void *)(buf_dyn_shmem + ((((((int)threadIdx.y) * 4096) + (ax0_ax1_ax2_ax3_0_fused_2_1 * 512)) + (((int)threadIdx.x) * 16)) + 16384)))
);
__asm__ __volatile__(
"cp.async.ca.shared.global.L2::128B [%0], [%1], %2;"
:: "r"(addr), "l"((void*)(B + (((((((((int)threadIdx.y) >> 1) * 262144) + (((int)blockIdx.x) * 4096)) + ((((int)threadIdx.y) & 1) * 2048)) + (ax0_ax1_ax2_ax3_0_fused_2_1 * 256)) + ((((int)threadIdx.x) & 15) * 16)) + ((((int)threadIdx.x) >> 4) * 8)))), "n"(16)
);
}
}
and we see bank conflicts happens:
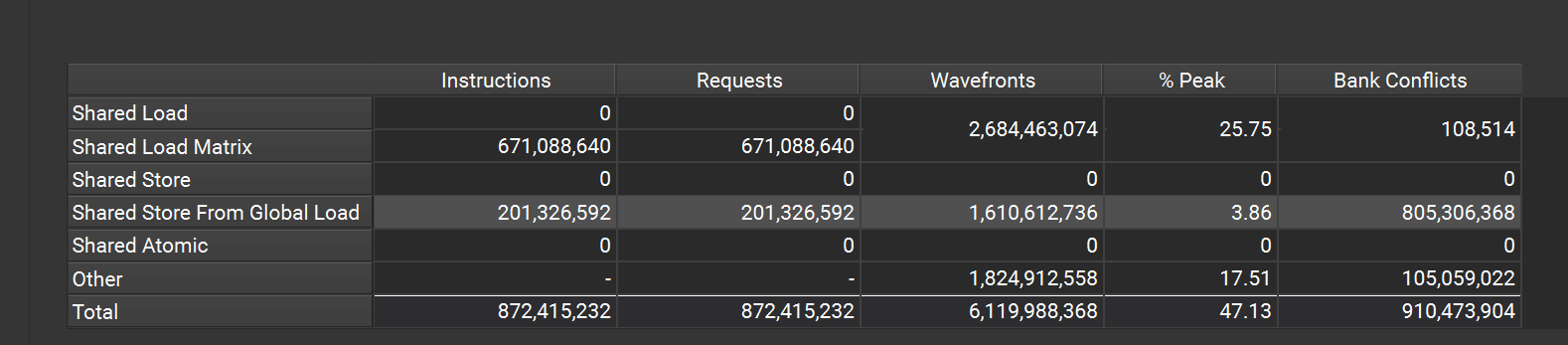
however I can observe that sota library like cutlass which also leveraged cp.async ptx but it has no bank conflict, did it make sense?