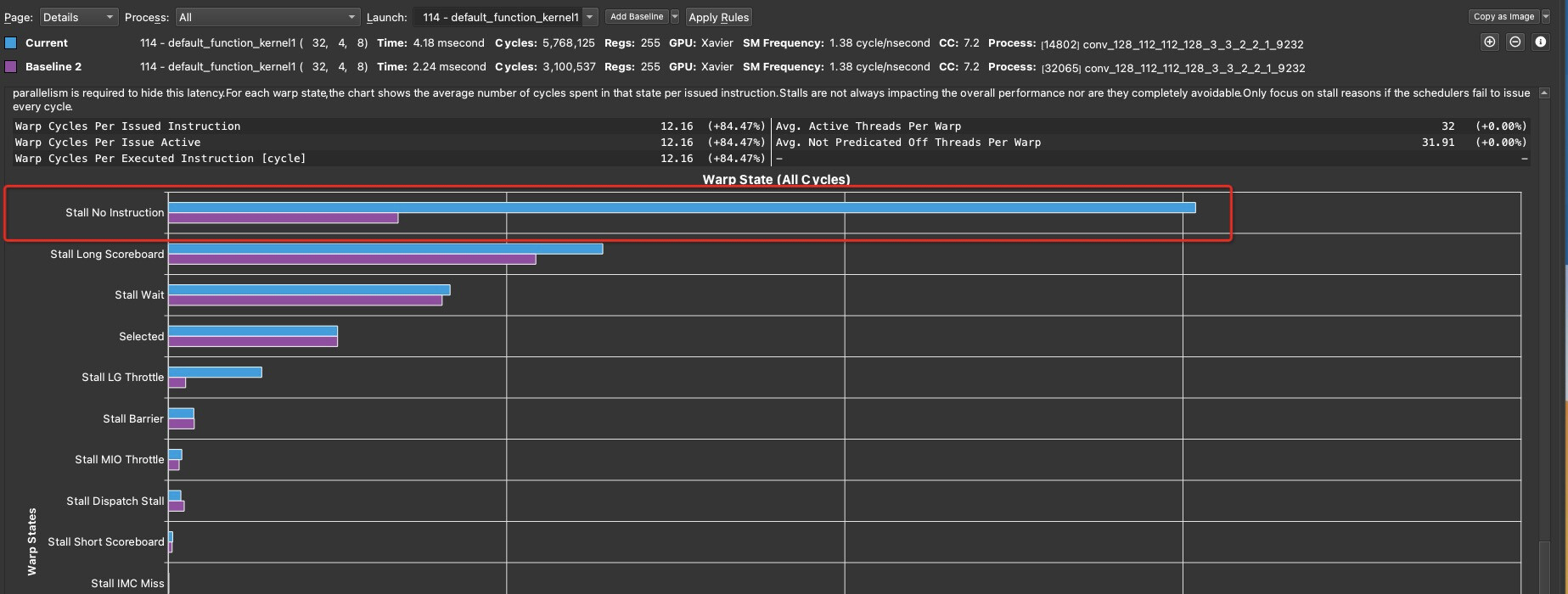
I Try to tuning a conv kernel using tensorcore in Jetson Xavier, however, I found that the kernel stall no instruction is very high when using nsight compute. And when I remove the store global operater, And I can see the stall no instruction is low.
The instruction size is 4928 line which means 77KB
The primary issue is that there is only 1 warp per SM sub-partition (SMSP). The warp scheduler has no ability to cover latency by switching warps in this configuration. The warp occupancy limit is due to the 20,480 bytes of shared memory per thread block with only 1 warp per thread block. If you could fit 2 warps per SM sub-partition the performance would likely double given the current math throughput and memory throughput.
Each kernel has >4800 instructions which far exceeds the instruction cache and second level constant cache. Since the 4 warps are in different blocks the warps are in very different locations of the shader putting a very heavy stress on the i-cache. For most kernels the target occupancy results in multiple warps accessing each instruction cache line. In the case of these kernels I suspect each cache line is only accessed 1-2x due to thrashing. I think the stalls on the STG instructions are helping gang the warps.
If I owned this my first step would be to get to 2 warps per SMSP to allow for some latency hiding and would fully use the register file.
If the kernel has an unrolled loop then I would try to reduce the number of times it is unrolled to reduce the demand on the instruction cache. Ideally you would want to reduce the icache to under 4K instructions but ideally I would shot for less than 1K instructions.