So I’m working on a live video stitching gstreamer pipeline on TX2, and having performance issue.
DISPLAY=:0 gst-launch-1.0 \
v4l2src device=/dev/video0 ! 'video/x-raw,width=1920,height=1080,format=UYVY,framerate=30/1' ! queue ! st. \
v4l2src device=/dev/video1 ! 'video/x-raw,width=1920,height=1080,format=UYVY,framerate=30/1' ! queue ! st. \
v4l2src device=/dev/video2 ! 'video/x-raw,width=1920,height=1080,format=UYVY,framerate=30/1' ! queue ! st. \
v4l2src device=/dev/video3 ! 'video/x-raw,width=1920,height=1080,format=UYVY,framerate=30/1' ! queue ! st. \
videostitcher ! \
'video/x-raw, width=(int)3840, height=(int)1920, format=(string)I420, framerate=(fraction)30/1' ! \
nvoverlaysink sync=false
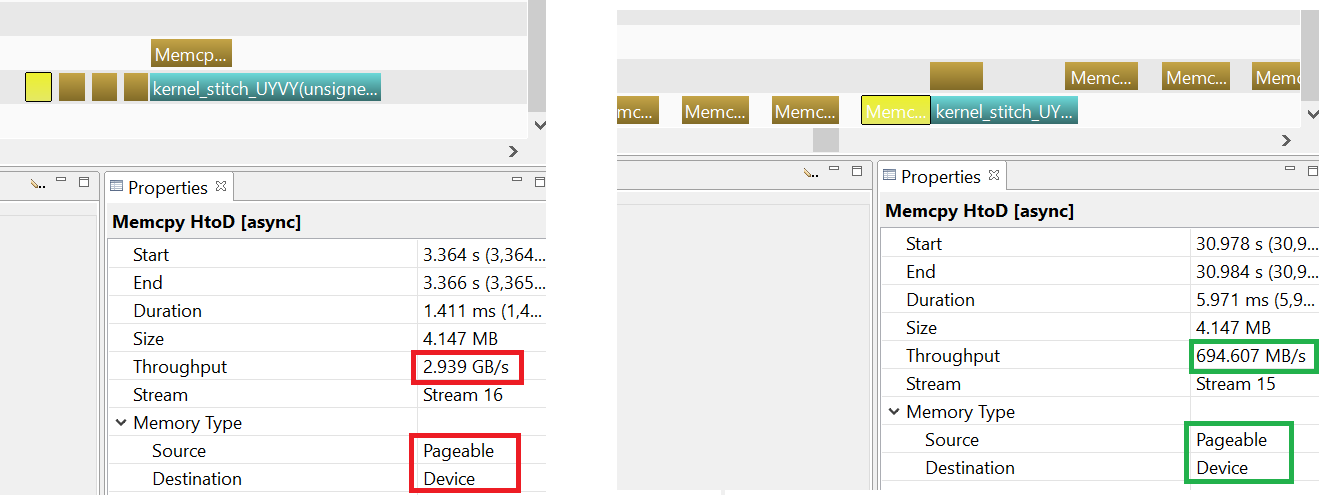
videostitcher is an element that uses cuda to stitch multiple inputs. It uses cudaMemcpyAsync and streams for concurrency. The problem here is that cudaMemcpyAsync has very low throughput, 400~700MB/s (from nvprof and nv visual profiler). Then I use oprofile to see what happend, and found that memcpy takes most of the cpu time:
CPU: ARM Cortex-A57, speed 2035.2 MHz (estimated)
Counted CPU_CYCLES events (Cycle) with a unit mask of 0x00 (No unit mask) count 100000
samples % linenr info image name symbol name
160549 67.0779 memcpy.S:50 libc-2.23.so memcpy
72433 30.2628 (no location information) no-vmlinux /no-vmlinux
2525 1.0550 (no location information) libcuda.so.1.1 /usr/lib/aarch64-linux-gnu/tegra/libcuda.so.1.1
344 0.1437 (no location information) libgobject-2.0.so.0.4800.2 /usr/lib/aarch64-linux-gnu/libgobject-2.0.so.0.4800.2
281 0.1174 (no location information) libglib-2.0.so.0.4800.2 /lib/aarch64-linux-gnu/libglib-2.0.so.0.4800.2
Then I gdb it a bit to see the callstack, and it seems all the memcpy is from inside cudaMemcpyAsync. My question is on what circumstance cudaMemcpyAsync will use memcpy so heavily? How to avoid this.
PS.
We uses Toshiba TC358743 to capture video. Seems the src element has a lot to do with this. Because if I replace all the v4l2src with videotestsrc, this heavy use of memcpy disappear (below).
DISPLAY=:0 gst-launch-1.0 \
videotestsrc pattern=2 ! 'video/x-raw, width=(int)1920, height=(int)1080, format=(string)UYVY, framerate=(fraction)30/1' ! queue ! st. \
videotestsrc pattern=2 ! 'video/x-raw, width=(int)1920, height=(int)1080, format=(string)UYVY, framerate=(fraction)30/1' ! queue ! st. \
videotestsrc pattern=2 ! 'video/x-raw, width=(int)1920, height=(int)1080, format=(string)UYVY, framerate=(fraction)30/1' ! queue ! st. \
videotestsrc pattern=2 ! 'video/x-raw, width=(int)1920, height=(int)1080, format=(string)UYVY, framerate=(fraction)30/1' ! queue ! st. \
videostitcher ! \
'video/x-raw, width=(int)3840, height=(int)1920, format=(string)I420, framerate=(fraction)30/1' ! \
nvoverlaysink sync=false
CPU: ARM Cortex-A57, speed 2035.2 MHz (estimated)
Counted CPU_CYCLES events (Cycle) with a unit mask of 0x00 (No unit mask) count 100000
samples % linenr info image name symbol name
107261 24.9035 tmp-orc.c:2194 libgstvideo-1.0.so.0.1203.0 video_orc_pack_UYVY
99342 23.0649 video-chroma.c:691 libgstvideo-1.0.so.0.1203.0 video_chroma_down_h2_cs_u8
98056 22.7663 memcpy.S:50 libc-2.23.so memcpy
63740 14.7989 (no location information) no-vmlinux /no-vmlinux
49138 11.4087 tmp-orc.c:159 libgstvideotestsrc.so video_test_src_orc_splat_u32
5098 1.1836 (no location information) libcuda.so.1.1 /usr/lib/aarch64-linux-gnu/tegra/libcuda.so.1.1