Note: I posted this in another category but I felt it may get more attention here
Specs (I have the full spec sheet we used to purchase the machine if needed):
- OS: Red Hat Enterprise Linux version 8.9 (Ootpa)
- GPU: 2x NVIDIA RTX A6000
- NVIDIA SMI info: NVIDIA-SMI 545.23.08, Driver Version: 545.23.08, CUDA Version: 12.3
Hi, we recently ordered and received a new machine that has 2 NVIDIA RTX A6000 cards which gives us 96GB of VRAM to work with. However, we noticed there is a weird issue with how the memory is being allocated onto the GPUs. I have also tried using the CUDA_VISIBLE_DEVICES environment variable. Setting it to 0 causes a segmentation fault with no further output. Setting it to 1 works but is still putting the data onto both GPUs. Setting it to anything else does not work and says that no cuda devices are available.
I was working on some experiments in PyTorch and bumped my batch size up high enough to use about 32/48GB on GPU 0. Upon doing so, I saw that for some reason, both GPUs were allocating the same amount of memory. To make sure it was not a visual glitch with the nvidia-smi command, I ran the same model at the same time but on GPU 1 and ran out of memory. I should have been able to run the model on both GPUs at the same time considering we have in total 96GB of VRAM but it looks like the data is for some reason being copied to both GPUs.
I was not sure if this was a PyTorch issue or not so I put together a small script to test:
import numpy as np
from numba import cuda
cuda.select_device(0)
data = np.ones(1000000000)
d_data = cuda.to_device(data)
while True:
a = 1
All this code does is send data to the specified GPU in the cuda.select_device() line (in our case either device 0 or 1) and hang until the user quits.
After doing so, I was able to capture screenshots of each GPUs memory allocation using nvtop:
The yellow line in each image represents the memory allocation for that GPU. The first image shows when cuda.select_device(0) was used and the second image used cuda.select_device(1). You can see that in each case, the data is being set to both GPUs even though in the code we only wanted to select one.
We have never seen anything like this before. Additionally, none of us have worked with Red Hat Linux either. We were wondering if this is an OS issue or possibly a hardware issue. In either case, this is bug is only letting us use 48/96GB of VRAM in the machine because the data is copied to both GPUs. If anyone has any insight on how to go about diagnosing and fixing this issue it would be much appreciated, thank you!
one thing to check is whether SLI is enabled. I don’t know if you are running a graphical desktop, if so you can check via nvidia-settings (i.e. the NVIDIA linux graphics control panel) here is a recent, possibly similar report, albeit on windows
Thanks for your comment.
I won’t be back in the office until Monday but we have MobaXterm which is able to show most GUIs and everything from the terminal. I’m not sure exactly if there is a graphical desktop or not so I will have to check in with that on Monday.
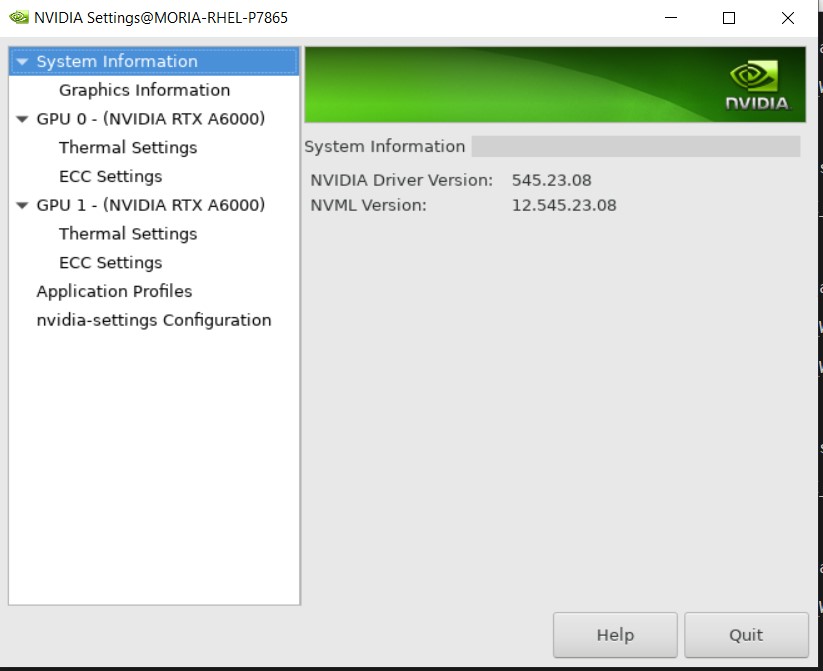
However, using MobaXterm I was able to run the nvidia-settings command from the terminal and a window popped up.
Unfortunately, after searching through it I could not find anything labeled or related to SLI.
Would you happen to know where this setting is located so I can check if this fixes things?
Edit: this is the window that pops up on my screen for reference:
I checked that page and attempted to turn sli off. There a few values it accepts so I tried 0, false, off and I get this output:
Command: nvidia-xconfig --sli=off
Using X configuration file: "/etc/X11/xorg.conf".
WARNING: Unable to parse X.Org version string.
ERROR: Unable to write to directory '/etc/X11'.
You’ll need root privilege.
Ok, thanks for the info.
We just got the machine and none of us have root privilege yet. I will see when this can be solved and check back in if that command fixes the problem
And I’m fairly certain after making a configuration change like this, you would need to restart the machine (or at least unload the GPU driver/restart X - but I would strongly encourage a machine restart instead).
We should be able to do that as well. I’m currently the only one using it so that shouldn’t be a problem, thanks for the recommendation.
Hi, so we were able to disable SLI and restart the machine:
I ran the code again and unfortunately we are still seeing the same issue of the data being put onto both GPUs.
Do you have any other solutions on how to fix this issue?
I’m not that familiar with nvtop, AFAIK its not a tool produced by NVIDIA, and I’ve pretty much never used it.
I’m also a little puzzled by the seg fault indication when you set CUDA_VISIBLE_DEVICES, and if this were my machine I’d prefer not to be doing diagnostics using numba. It just presents another translation layer, and I may not be fully aware of what the numba developers have done lately.
If this were my machine I would repeat the experiment with CUDA C++ and nvidia-smi. I don’t see anything here that necessitates use of either numba or nvtop.
Do as you wish of course. I don’t really have further speculation about what the issue may be. When you start a CUDA program, it’s normal for all “visible” GPUs to have some memory allocation done on them, even if your program is not using them. Rather than reading a graph, I’d like to see the actual output from nvidia-smi.
Thanks for the message.
I decided to use numba because I was originally using PyTorch when I found this issue. I wanted to make sure it was more of a general issue and not just something going on in PyTorch. If you know of a more general purpose way to send data to a GPU in python I can test that too.
I have the nvidia-smi results as well:
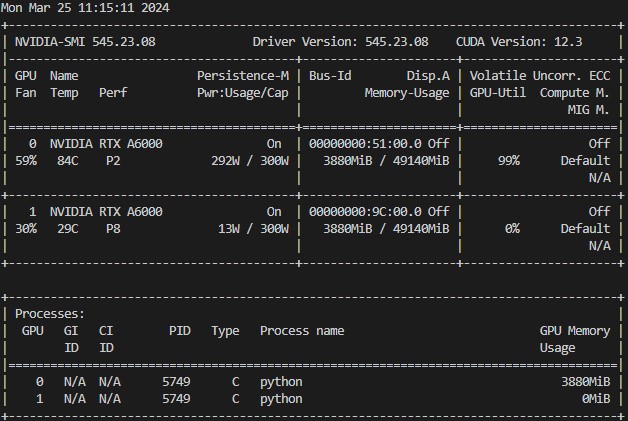
Here we can see that both GPUs are still allocating the same amount of memory, even with SLI disabled. I think I mentioned this before but we can also see that only GPU 0 is actually being used for computation as noted by its power consumption. It’s very puzzling that GPU 1 has the same amount of memory allocated while not being used for any computation
Your python code is “using” GPU 1, meaning the process has touched it.
I suggest repeating the experiment with CUDA C++, including the tests with CUDA_VISIBLE_DEVICES. If a seg fault persists, I would like to know which line of code triggered the seg fault.
I can try to look into CUDA C++, thanks for the recommendation.
My only concern is that when I run the exact code on a different machine with multiple GPUs this problem does not occur. It makes me think that it may be a Red Hat Linux issue or something because our other machine use Ubuntu.
At the moment I cannot explain it.
Something doesn’t add up.
The default datatype for np.ones is float64, i.e. 8 bytes per element. You are requesting 1 billion elements, so 8 billion bytes should be needed. A memory allocation of 3880 MiB is not consistent with that. And there is nothing in that numba code that could possibly “spread” that allocation across 2 gpus. (nor does 2 allocations of 3880MiB account for it, either).
Sorry, the screenshot I just posted was not from that code, I was running some PyTorch stuff in the background and just used that instead because the issue is still present
Here is the nvidia-smi output from the code I posted:
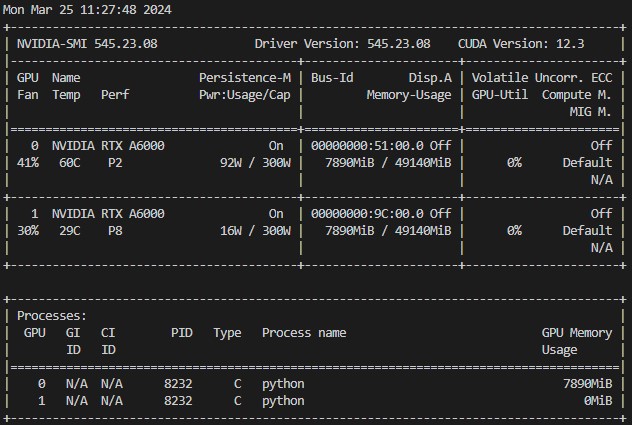
I suggest following the steps I already indicated. That’s what I would do.
- switch to CUDA C++
- repeat the tests, including with
CUDA_VISIBLE_DEVICES selecting GPU 0
- if a seg fault occurs on the CUDA C++ test, identify the line of code that triggered the seg fault
So there is a library called faulthandler in python which tries to help diagnose seg faults.
I ran it with my code and got this output:
I’m not sure if this helps but I just figured I would post it.
I am going to try and do the CUDA C++ stuff you mentioned hopefully within the next few days and I can get that output as well