Description
I am working on compiling a CenterNet model for keypoint detection from the TF OD hub to a trt engine (via onnx). I have run up against what seems to be a fundamental limitation of current TensorRT, which is that shapes of intermediate Tensors cannot be dependent on runtime data. This is an issue for me because my model is trained to detect n different classes, and the postprocessing logic is a little different depending on the class, and the way the postprocessing works now, each class is seperated out into its own tensor for postprocessing. The code below is a toy reproduction of what the problematic postprocessing code in my model started out as
Attempt 1
class WhereGather(tf.keras.Model):
def __init__(self):
super(WhereGather, self).__init__()
def call(self, inputs):
detection_ids, class_index = inputs
indices = tf.where(detection_ids == class_index)
return tf.gather(detection_ids, tf.squeeze(indices))
This results in this onnx graph:

This will not convert to TensorRT, because NonZero is currently unsupported by TensorRT, and cannot be implemented as a plugin due to the shape of its output being dependent on data passed in as explained here .
Attempt 2
I say to myself “ok no problem, I think I can rewrite the tf code to get rid of the NonZero”. I come up with something that looks like the following, which does indeed get rid of the NonZero (which can be accomplished by replacing the one argument version of tf.where with the three argument version):
class WhereGather(tf.keras.Model):
def __init__(self):
super(WhereGather, self).__init__()
def call(self, inputs):
detection_ids, class_idx = inputs
mask = detection_ids == class_idx
index_mask = tf.where(mask, tf.ones_like(detection_ids), tf.ones_like(detection_ids) * -1)
num_detections = tf.reduce_sum(tf.cast(mask, tf.int32))
(_, indices) = tf.math.top_k(index_mask, k=num_detections)
return indices
This produces the following onnx graph.

No NonZero, Yay! But my satisfaction at coming up with this clever workaround quickly evaporated when I tried to compile this model to TensorRT and got the following error:
[11/12/2021-22:50:03] [E] [TRT] parsers/onnx/ModelImporter.cpp:778: ERROR: parsers/onnx/builtin_op_importers.cpp:4527 In function importTopK:
[8] Assertion failed: (inputs.at(1).is_weights()) && "This version of TensorRT only supports input K as an initializer."
This is because current TensorRT does not support computing the k for TopK dynamically, it must be fixed at build time as explained here.
After thinking for a while, I realized that maybe onnx graph surgeon could solve this problem, so I came up with this:
class WhereGather(tf.keras.Model):
def __init__(self):
super(WhereGather, self).__init__()
def call(self, inputs):
detection_ids, class_idx = inputs
mask = detection_ids == class_idx
index_mask = tf.where(mask, tf.ones_like(detection_ids), tf.ones_like(detection_ids) * -1)
indices = tf.argsort(index_mask, direction="DESCENDING")
num_detections = tf.reduce_sum(tf.cast(mask, tf.int32))
return indices[:num_detections]
which generates this onnx graph:
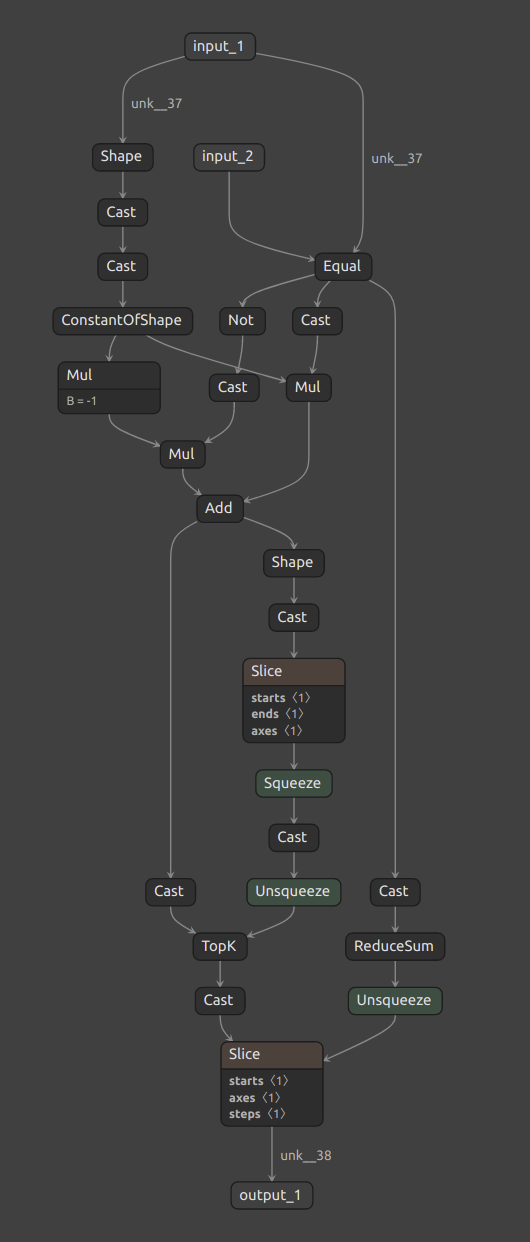
What is going on here is that the tf2onnx parser is parsing the tf.argsort to a TopK operation, with k set as the length of the input tensor, which is equivalent to a sort. This still results in a dynamic k argument, which will cause the same error as above, but in practice, this shape of this tensor will always be fixed, so I went in with onnx graph surgeon and set the K to be fixed as 100. After doing this I crossed my fingers and ran trtexec one more time, but got this error
[6] Invalid Node - PartitionedCall/where_gather/strided_slice
[shapeContext.cpp::volumeOfShapeTensor::439] Error Code 2: Internal Error (Assertion hasAllConstantValues(t.extent) && "shape tensor must have build-time extent" failed. )
This seems to be due to the fact that the slice index for indices is being computed based on data at runtime.
The three chunks of code above compute the same thing in three slightly different ways, and cause three different TensorRT errors, which all seem to be getting at this same thing, which is that you can’t have the shape of intermediate tensors being determined by runtime data.
-
Am I correct that this is the root cause of these three errors, and is this simply a fundamental limitation of TensorRT as it currently exists?
-
If so, could you provide any background information that would help me understand what feature of the design of TensorRT is responsible for this limitation?
-
Will future versions of TensorRT address this limitation?
-
What is my best bet for this use case?
Environment
TensorRT Version: 8.2
GPU Type: Quadro
Nvidia Driver Version: 495
CUDA Version: 11.5
CUDNN Version: NA
Operating System + Version: Ubuntu 18.04
Python Version (if applicable): 3.9
TensorFlow Version (if applicable): 2.6
