Hello,
I am currently working on a project which is implementing a abstraction layer for the CUDA API.
There I am trying implement an example with it which focusses on overlapping data transfers:
[url]https://github.com/parallel-forall/code-samples/blob/master/series/cuda-cpp/overlap-data-transfers/async.cu[/url]
The implementation is working, but the problem is that the data transfers are not overlapping, as you can see in the results of the nvidia visual profiler below:
Reference (code in the link above):
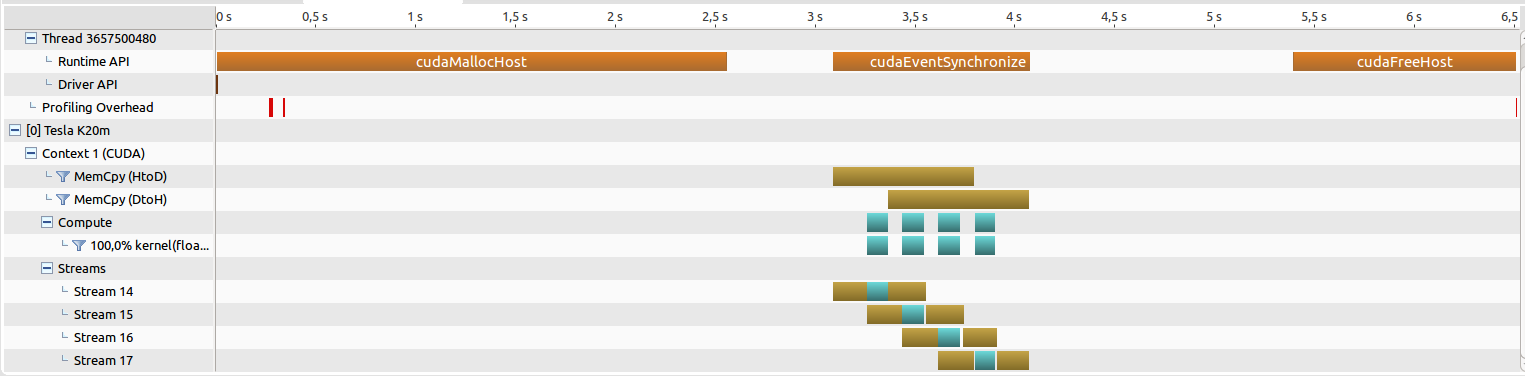
Implementation:

The implementation of the abstraction layer is not using any synchronize methods and the memCpy is asynchronous. But somehow the data transfers are not overlapping. Does someone know, without looking at the code, what may cause this problem?