I’ve recently noticed that individual data transfers are slower when running in parallel (overlapping a H2D with a D2H transfer) than when running sequentially.
This happens across a various range of GPUs from P3200 to RTX5000 or GV100, both on Windows and Linux.
I tested the simpleMultiCopy CUDA sample on my P3200 with N set to 1<<23. There too, we can see this behavior:
When running compute and data transfers sequentially: H2D takes about 0.26 ms
When compute, H2D, D2H are overlapped, H2D takes more, about 0.30 ms
Is there a reason for a data transfer to take longer when running it in parallel with another data transfer? Anyone else encountered a similar behavior?
Its certainly possible for those transfers to run slower from a GPU perspective when they are overlapped with a compute kernel. The compute kernel may be a user of device memory bandwidth, which the copy operation needs also. If the compute kernel is a significant user of device memory bandwidth, then the overlap may result in both operations being noticeably affected.
Host memory bandwidth utilization can also affect this.
In my experience this used to be a common scenario, although it has become less of a problem in recent years as CPUs are now routinely provided with more than two memory channels.
Generally speaking, one would not want to skimp on system memory bandwidth when building a GPU-accelerated HPC system. Four channels of DDR4-2666 should be considered a minimum configuration.
I’m a colleague of Ancah and I’ve repeated her test scenario on our 48 core Linux server (256 GB RAM) with an A100 40GB card inserted in a PCI-E 3.0 slot, and I’m seeing the same phenomenon there. As soon as the application moves from interleaved H2D and D2H operations to concurrent H2D and D2H operations in separate streams the bandwidth drops from 11.8 to 12.2 GB/s (depending on whether it’s a D2H or H2D copy) to 9.0 to 9.3 GB/s (depending on how much overlap the D2H and H2D operations have. The more overlap, the lower the bandwidth).
Since the server is exclusive used for our A100 work, and is running only the typical system processes (and let’s face it with 48 cores and 256 GB of RAM there is plenty of room for the OS not to interfere with the CUDA application) and the robust architecture of the A100 with regards to memory handling, there should not be an issue as described by you guys.
Am I correct to assume that this server has either multiple CPU sockets or has a single AMD CPU that uses multiple dies internally, each of which is coupled to a particular memory controller and PCIe lanes?
If so, have all tests been run with processor and memory affinity set (for example, via numactl) such that the GPU is always talking to the near processor and the near memory? If data sometimes needs to be transferred via inter-processor interconnect (to a far processor and memory) that would likely have a negative performance impact.
Please note that I can only speak in generalities. I am not sitting in front of the system and running experiments. Issues such as this are notoriously difficult to resolve via the internet due to issues with reproducability. Note that I have never had the privilege and opportunity to operate an A100. If you have evidence that things are not running as they should be, you could always consider filing a bug report with NVIDIA.
The original post mentions simpleMultiCopy. While there are caveats using NVIDIA example apps for benchmarking, there doesn’t seem to be any reason why this app shouldn’t produce a reasonable estimate. What I would quibble with is the methodology of using the average of ten runs, rather than the fastest of 10 runs, which is the correct standard IMHO, used by the well-known STREAM benchmark, for example.
What does sample output for this app look like on your system? Below is what I see on mine (Xeon W-2133, 32 GB system memory, Windows 10, WDDM driver). I haven’t spotted anything yet that looks out of place. I tried N= 1 << 23 in addition to the default of N = 1 << 22 and only see a minor difference in performance. The largest size I can run on my hardware is N = 1 << 27, which adds a little bit more perf.
The speedup from simultaneous two-way communication between host and device isn’t exactly the theoretical 2x here, but as Robert Crovella pointed out above
The compute kernel may be a user of device memory bandwidth, which the copy operation needs also. If the compute kernel is a significant user of device memory bandwidth, then the overlap may result in both operations being noticeably affected.
One might look into eliminating the kernel and just perform the copying.
[simpleMultiCopy] - Starting...
> Using CUDA device [0]: Quadro RTX 4000
[Quadro RTX 4000] has 36 MP(s) x 64 (Cores/MP) = 2304 (Cores)
> Device name: Quadro RTX 4000
> CUDA Capability 7.5 hardware with 36 multi-processors
> scale_factor = 1.00
> array_size = 4194304
Relevant properties of this CUDA device
(X) Can overlap one CPU<>GPU data transfer with GPU kernel execution (device property "deviceOverlap")
(X) Can overlap two CPU<>GPU data transfers with GPU kernel execution
(Compute Capability >= 2.0 AND (Tesla product OR Quadro 4000/5000/6000/K5000)
Measured timings (throughput):
Memcpy host to device : 1.366016 ms (12.281859 GB/s)
Memcpy device to host : 1.279712 ms (13.110150 GB/s)
Kernel : 0.172480 ms (972.704998 GB/s)
Theoretical limits for speedup gained from overlapped data transfers:
No overlap at all (transfer-kernel-transfer): 2.818208 ms
Compute can overlap with one transfer: 2.645728 ms
Compute can overlap with both data transfers: 1.366016 ms
Average measured timings over 10 repetitions:
Avg. time when execution fully serialized : 2.896896 ms
Avg. time when overlapped using 4 streams : 1.564032 ms
Avg. speedup gained (serialized - overlapped) : 1.332864 ms
Measured throughput:
Fully serialized execution : 11.582892 GB/s
Overlapped using 4 streams : 21.453802 GB/s
With N = 1 << 23:
[simpleMultiCopy] - Starting...
> Using CUDA device [0]: Quadro RTX 4000
[Quadro RTX 4000] has 36 MP(s) x 64 (Cores/MP) = 2304 (Cores)
> Device name: Quadro RTX 4000
> CUDA Capability 7.5 hardware with 36 multi-processors
> scale_factor = 1.00
> array_size = 8388608
Relevant properties of this CUDA device
(X) Can overlap one CPU<>GPU data transfer with GPU kernel execution (device property "deviceOverlap")
(X) Can overlap two CPU<>GPU data transfers with GPU kernel execution
(Compute Capability >= 2.0 AND (Tesla product OR Quadro 4000/5000/6000/K5000)
Measured timings (throughput):
Memcpy host to device : 2.729856 ms (12.291649 GB/s)
Memcpy device to host : 2.552288 ms (13.146804 GB/s)
Kernel : 0.337952 ms (992.875710 GB/s)
Theoretical limits for speedup gained from overlapped data transfers:
No overlap at all (transfer-kernel-transfer): 5.620096 ms
Compute can overlap with one transfer: 5.282144 ms
Compute can overlap with both data transfers: 2.729856 ms
Average measured timings over 10 repetitions:
Avg. time when execution fully serialized : 5.747533 ms
Avg. time when overlapped using 4 streams : 3.098416 ms
Avg. speedup gained (serialized - overlapped) : 2.649117 ms
Measured throughput:
Fully serialized execution : 11.676117 GB/s
Overlapped using 4 streams : 21.659088 GB/s
Yes, the system has a dual socket Intel setup (using two Intel(R) Xeon(R) Gold 5118 CPUs). We are talking to our NVIDIA contacts about this issue, but my colleague also wanted to use the wisdom of the NVIDIA forum members to see if anybody else had experienced and, more importantly, found a reason for why this phenomenon is happening.
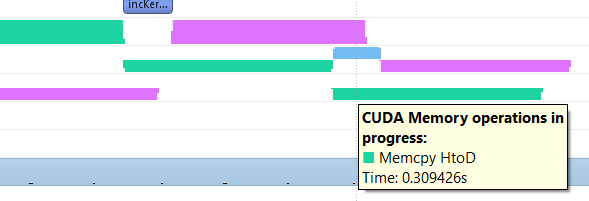
We experienced this phenomenon with our own proprietary software implementation first, but since we can’t share anything about that code with outside parties we were looking for an example where we could reproduce the same behavior so that we could share both nsys logging and the source code. That lead my colleague to simpleMultiCopy because there we could easily reproduce the D2H and H2D overlapped copy behavior. Looking at the output of the application doesn’t really tell you if the problem occurs, you really need to look at the nsys profile logs for a run to see the time spent in each H2D and D2H operation and the associated achieved bandwidth.
As I stated before, looking at the logged data for the initial, non-overlapping D2H and H2D copy operations we see that they reach between 11.8 to 12.2 GB/s on our server over the PCI-E 3.0 bus, but as soon as the application switches to concurrent D2H and H2D copy operations (each running in their own stream), we see that they drop down to the 9.0 to 9.3 GB/s range (where the number is higher is there is less overlap, as getting these copy operations to start at exactly the same time is not always achieved, there is some variation between the two streams regarding this). For my test I limited the number of streams used to two, to ensure that there are no more than one of each type of copy operation being used at the same time (to avoid loading the PCI-E bus with more than one simultaneous read and write operation).
So if you want to see if there is anything similar happening on your RTX 4000 system, you need to modify the code for two streams and log the run with Nsight Systems to see if the D2H and H2D copy operations exhibit the same reduction in bandwidth.
You may also want to make sure you are using proper process pinning/placement in this case. If the data structure that is being copied to/from is in memory that has affinity to the CPU socket that is not connected to the GPU, then the H2D and D2H traffic will flow over the QPI bus or whatever Intel is calling their inter-socket bus these days. I haven’t studied it carefully but two Gen3 streams flowing over this might present a noticeable limiter. (Depending on your server settings, you might also have some memory striping scheme that makes this unavoidable. But normally memory allocations will first make use of memory that is in affinity to the process that is requesting the allocation.)
Overall this seems an unlikely explanation to me, because I think “random” testing would show an alternation in behavior if this were actually happening.
(Later: This is a skylake processor and the intersocket bus is called UPI. It doesn’t seem like UPI bandwidth should be an issue here, but I haven’t studied it carefully, and it could possibly depend on other things going on in the system, and your actual motherboard design.)
We’ve talked to our contacts in NVIDIA and send them a test application that exhibits the issue and a NSight Systems log that shows the effect and they are looking into it. They have managed to reproduce the effect on their side, so that should make things simpler to diagnose.
We haven’t heard back a definite explanation for the root cause, they are still investigating.