[font=“arial, sans-serif”][font=“arial, verdana, tahoma, sans-serif”]Hi,
Hi, assume a simple matrix multiplication of square non-sparse matrices, e.g. A*B =C with n=m (n, m matrices size). [/font]
[font=“arial, verdana, tahoma, sans-serif”] [/font][font=“arial, verdana, tahoma, sans-serif”] [/font]
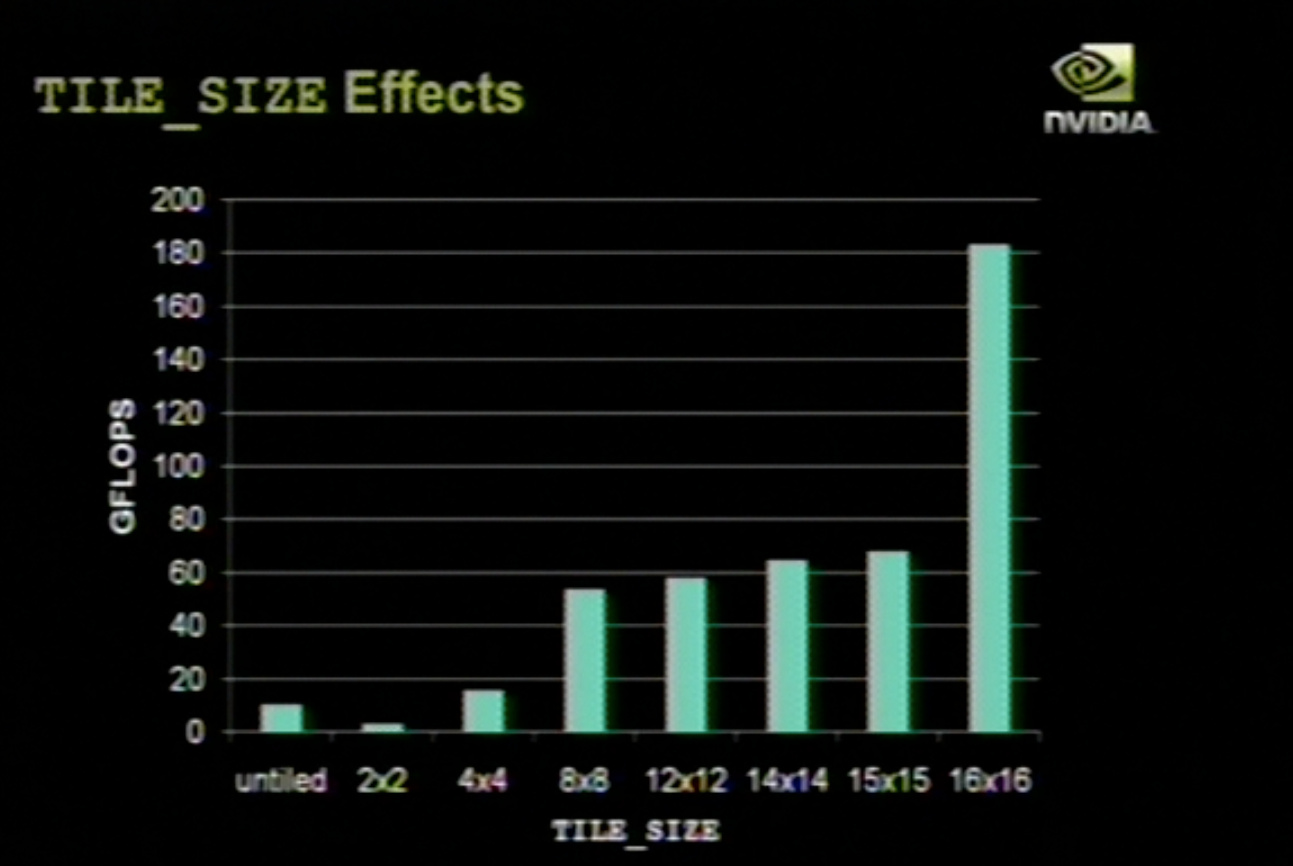
[font=“arial, verdana, tahoma, sans-serif”]The image attached s[/font][font=“arial, verdana, tahoma, sans-serif”]hows the performance gain by “chopping” the input matrices into tile blocks. I am not sure [/font][font=“arial, verdana, tahoma, sans-serif”]how to interpret this, i mean what is the underlying [/font][font=“arial, verdana, tahoma, sans-serif”]mechanism?
Why a division into a 2x2 or 4x4 tiles performs similarly to the naive [/font][font=“arial, verdana, tahoma, sans-serif”](that is, no tiles used) multiplication? Most importantly, why such a peak gained for [/font][font=“arial, verdana, tahoma, sans-serif”]the 16*16 tiling?
I understand that a 1616 needs 1616/32 = 8 warps (integer), [/font][font=“arial, verdana, tahoma, sans-serif”]but an 88 tiling also results in an integer warp, but with approximately 3 time less [/font][font=“arial, verdana, tahoma, sans-serif”]gain in GFLOP/s compared to the 1616 case.
Could this be related to the stride used, [/font][font=“arial, verdana, tahoma, sans-serif”]whenever it is an exact multiple of the warp? Any pointers to literature much appreciated[/font]
[font=“arial, verdana, tahoma, sans-serif”]
Thanks for any feedback!
[/font]
[font=“arial, verdana, tahoma, sans-serif”]N
ps. [font=“arial, verdana, tahoma, sans-serif”]" the asymptotic time complexity of all dense direct methods is O(n^3) for the (say LU) [/font][font=“arial, verdana, tahoma, sans-serif”]factorization and O(n^2) for solving the system based on the precomputed factorization"[/font][/font][/font]