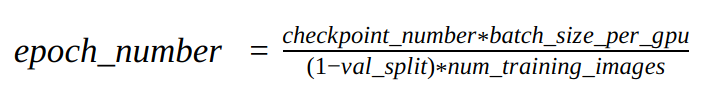However, when I check it against a Detectnet_V2 model that was just trained using TAO, the numbers don’t work out to any capacity, and I’m wondering whether that is just due to how the model was set up and trained versus what the formula expects.
For context of the model setup and the input values to the formula:
The saved checkpoint is model.step-248640 and the associated epoch is 280
The model was trained on 16 gpus and the batch size per GPU (in the training configuration file) is 16
The train kitti config and validation kitti config were both generated with “random” partition mode (so 2 folds) and a val_split value of 1, as well as a num_shards value of 8. During training, the dataloader section of the configuration file is provided with both the training and validation data sources. In total, there are 149677 images in the training folder as well as 6437 images in the validation folder.
As the val_split and the actual validation set used in the training are of different values, I’m a bit confused as to which value would be applicable if any, whether the validation split should be 1% = 0.01 or 6437/(6437+149677) = 0.0412. Regardless of which one is used the formula still doesn’t output expected values.
You can find similar info in training log.
For example,
2022-06-09 15:28:42,206 [INFO] modulus.blocks.data_loaders.multi_source_loader.data_loader: total dataset size 6434, number of sources: 1, batch size per gpu: 4, steps: 1609
Then 1609 will be the one of the checkpoint number.
I looked within my training log and I unfortunately can’t find the line you mentioned above. Instead, whenever a checkpoint is saved, I get the following:
INFO:tensorflow:Saving checkpoints for step-8880.
2022-06-03 19:40:49,274 [INFO] tensorflow: Saving checkpoints for step-8880.
Otherwise, the sample output per line is something like the following:
2022-06-03 19:40:43,871 [INFO] tensorflow: epoch = 29.966216216216218, loss = 0.0011594478, step = 8870 (6.028 sec)
INFO:tensorflow:global_step/sec: 1.65613
I unfortunately don’t know if the log when the tfrecord files were generated is available, but here are the spec files for the training set of tfrecords and the training spec. Note that I’ve replaced some of the actual paths with <placeholders_for_paths>.
From your log, there is below description for training dataset.
[1,14]:2022-06-04 18:08:42,534 [INFO] modulus.blocks.data_loaders.multi_source_loader.data_loader: total dataset size 227167, number of sources: 1, batch size per gpu: 16, steps: 888
The steps are 888. So the checkpoint number is related to it.
I guess the question still remains that I’m unclear how exactly the checkpoint number relates to the epochs. I understand that the checkpoint number and saved model name is related to the steps, but that doesn’t solve the main question which that the values I have do not work out fundamentally with the reference formula.
Thank you for the clarification, and apologies if I’m still just missing it, but I don’t quite see how this necessarily relates epochs to steps/checkpoint number, as per my original question. The reference formula in question is