From my reading, especially of the appendices in CUDA C programming guide, and adding some assumptions that seem plausible but which I could not find verifications of, I have come to the following understanding of GPU architecture and warp scheduling.
I would really appreciate it if someone with more expertise could read this and comment on any misunderstandings they see:
============
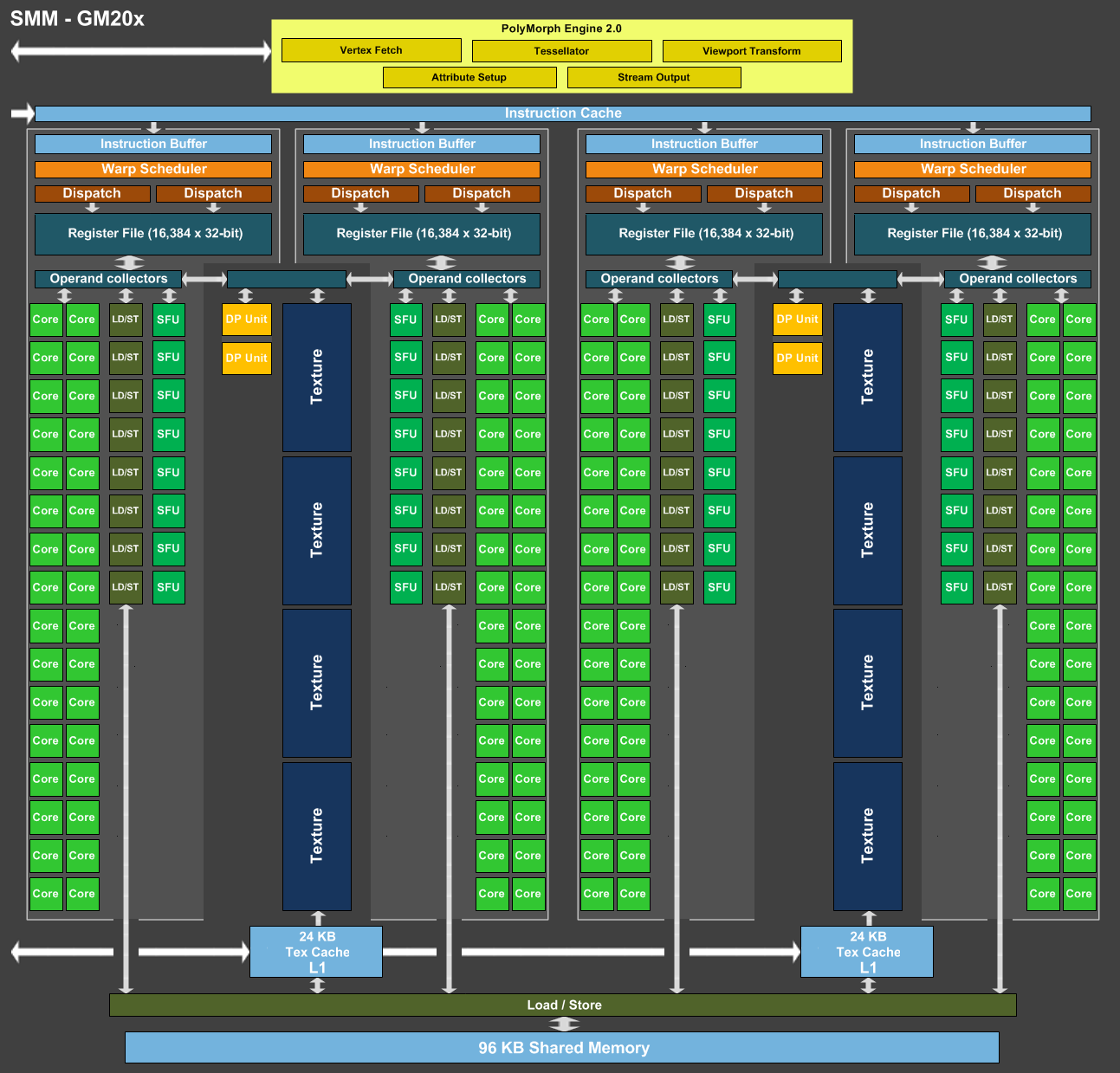
GTX 960
CUDA capability 5.2
8 multiprocessors, 128 cores/multiproc, 4 warp schedulers per multiproc
Max 2048 threads per multiproc
Max 1024 threads per block
GPU max clock rate: 1.29GHz
Blocks are assigned to a multiproc
Thus, with 1024 threads per block, 2 blocks can be live (“in flight”) on a multiproc. More if you have less threads per block.
When a block is assigned to a multiproc, the warps of the block are distributed statically among the 4 warp schedulers.
With max 2048 threads per multiproc, i.e. 64 warps, each scheduler gets at most 16 warps (possibly from different blocks).
Each scheduler issues 1 instruction from one warp per cycle, if it has a warp ready to execute. So if the current warp is not ready (e.g. waiting on a memory transaction or an FP function unit), the scheduler switches to an alternative warp assigned to this scheduler that is ready without costing any delay if such a warp exists.
The advantage of each scheduler having upto 16 warps to schedule means that you can cover quite a bit of latency while waiting for a delayed instruction to complete (mem, function unit etc.) by switching between the other 15 warps.
If a scheduler does not have warp ready to execute, it can not “steal” a ready warp from another scheduler.
Thus in the theoretical optimal case, if you have a kernel with 32*N threads in total, and the kernel is K instructions long, you could potentially execute the kernel in N * K / (8 * 4) cycles at maximum 1.29 GHz (8 multiprocessors, 4 warp schedulers)
=============
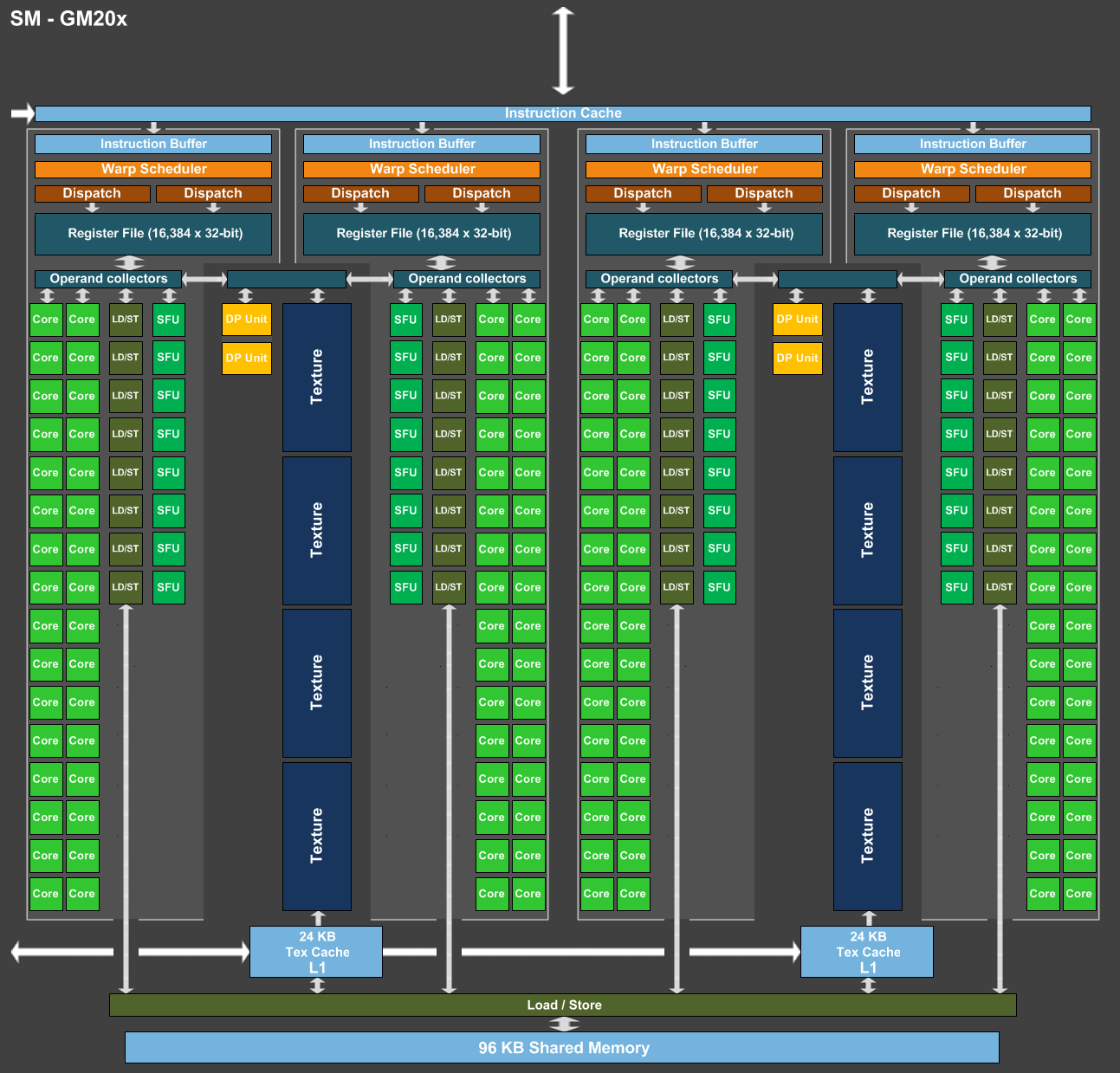
GTX 1080 Ti
CUDA capability 6.1
28 multiprocessors, 128 cores/multiproc, 4 warp schedulers per multiproc
Max 2048 threads per multiproc
Max 1024 threads per block
GPU max clock rate: 1.68GHz
Same assumptions: N * K / (28 * 4) cycles at maximum 1.68 GHz







{kind=link}