Hello, I was redirected here from a post I made on the CUDA forum, where they suggested I ask this question in the Jetson forum instead:
My question is the following:
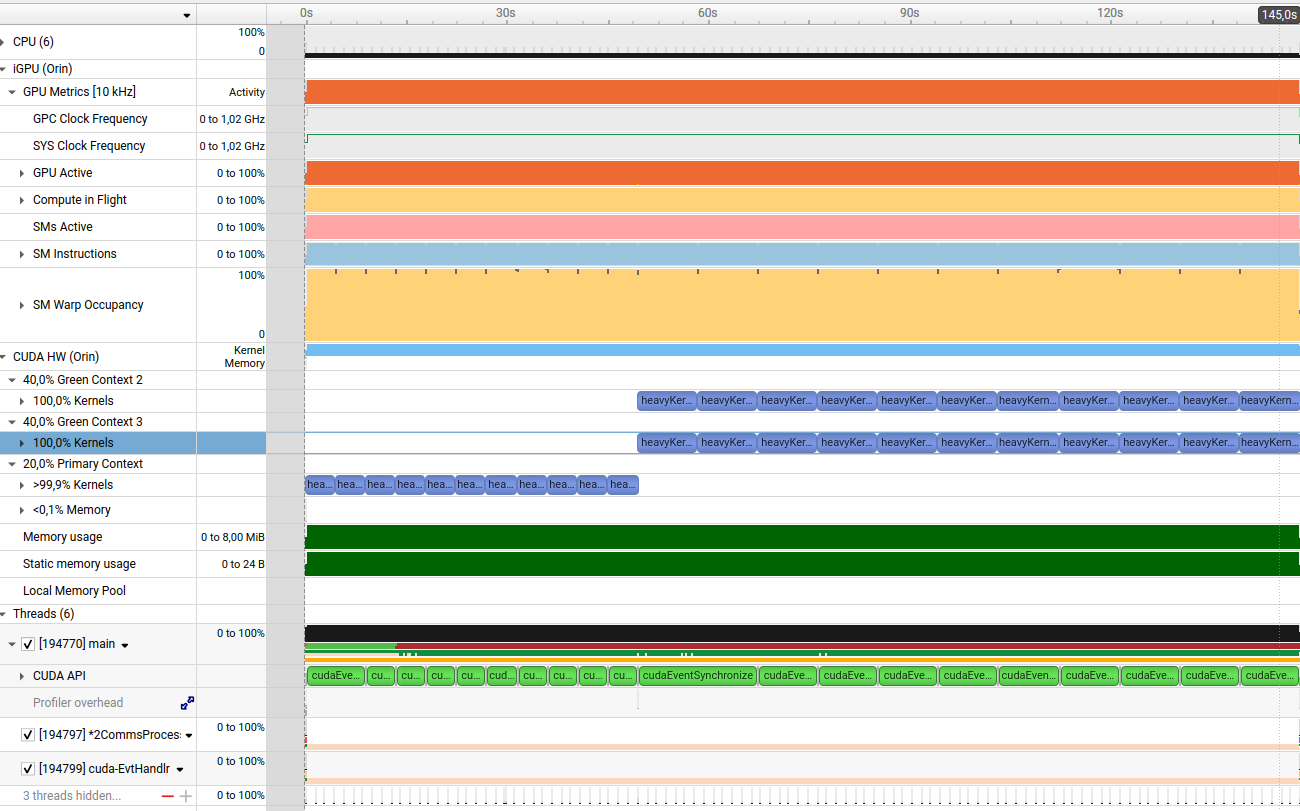
I’m experimenting with CUDA Green Contexts to assign a specific number of SMs to each context and run different kernels in parallel. However, I’m observing that regardless of how many SMs I allocate to each Green Context (via cuDevSmResourceSplitByCount), the execution time for the kernel remains essentially the same in both contexts.
Below is a simplified version of my code. I’m launching a computationally heavy kernel using two different Green Contexts, each associated with its own stream. I allocate only minCount = 1 SM to one of the contexts, while the other context gets the remaining SMs. I expected the kernel in the smaller context to take noticeably longer, but both timings are almost identical.
From what I’ve seen and based on the comments in the previous thread, it seems that the behavior I’m observing isn’t due to how Green Contexts work in general. Therefore, my follow-up question is:
Could there be any Jetson-specific considerations or constraints I should be aware of when using Green Contexts?
Or is it possible that I’ve made a mistake in my setup that I haven’t yet identified?
Any insights would be greatly appreciated!
Thanks in advance!
🖥️ System Info:
- GPU: NVIDIA Orin (nvgpu)
- CUDA Version: 12.6
- Driver Version: 540.4.0
- OS: Ubuntu 20.04
- Compiler:
nvccfrom CUDA 12.6
Executed code
#include <iostream>
#include <cuda_runtime.h>
#include <cmath>
#include <cuda.h>
#include <vector>
__global__ void heavyKernel(float *data, int n, int iterations) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= n) return;
float x = data[idx];
for (int i = 0; i < iterations; ++i) {
x = x * 1.0000001f + 0.0000001f;
x = sinf(x);
x = sqrtf(fabsf(x));
}
data[idx] = x;
}
#define CUDA_RT(call) \
do { \
cudaError_t _err = (call); \
if ( cudaSuccess != _err ) { \
fprintf(stderr, "CUDA error in file '%s' at line %i: %s\n", \
__FILE__, __LINE__, cudaGetErrorString(_err)); \
return _err; \
} else { \
printf("CUDA Runtime call at %s:%d succeeded.\n", __FILE__, __LINE__); \
} \
} while (0)
#define CUDA_DRV(call) \
do { \
CUresult _status = (call); \
if ( CUDA_SUCCESS != _status) { \
fprintf(stderr, "CUDA error in file '%s' at line %i: %i\n", \
__FILE__, __LINE__, _status); \
return _status; \
} else { \
printf("CUDA Driver call at %s:%d succeeded.\n", __FILE__, __LINE__); \
} \
} while (0)
int main() {
CUdevResource input;
CUdevResource resources[2];
CUdevResourceDesc desc[2];
CUgreenCtx gctx[2];
CUstream streamA, streamB;
unsigned int nbGroups = 1; // number of groups to create
unsigned int minCount = 1; // minimum SM count to assign to a green context
int deviceCount = 0;
cudaError_t err = cudaGetDeviceCount(&deviceCount); // error variable
const int n = 1 << 20; // 1 million elements
const int iterations = 100000;
const int total_runs = 10;
const int threadsPerBlock = 256;
const int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
float tiemposA[total_runs];
float tiemposB[total_runs];
cudaEvent_t startA, stopA, startB, stopB;
cudaEventCreate(&startA);
cudaEventCreate(&stopA);
cudaEventCreate(&startB);
cudaEventCreate(&stopB);
float *h_data = new float[n];
for (int i = 0; i < n; ++i) {
h_data[i] = static_cast<float>(i) / n;
}
float *d_data;
cudaMalloc(&d_data, n * sizeof(float));
cudaMemcpy(d_data, h_data, n * sizeof(float), cudaMemcpyHostToDevice);
float tiempos[total_runs];
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// Preheating
heavyKernel<<<blocksPerGrid, threadsPerBlock>>>(d_data, n, iterations);
for (int i = 0; i < total_runs; ++i) {
std::cout << "Launching kernel " << i << "...\n";
cudaEventRecord(start);
heavyKernel<<<blocksPerGrid, threadsPerBlock>>>(d_data, n, iterations);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
std::cerr << "CUDA error: " << cudaGetErrorString(err) << std::endl;
return 1;
}
float ms = 0;
cudaEventElapsedTime(&ms, start, stop);
tiempos[i] = ms;
}
cudaMemcpy(h_data, d_data, n * sizeof(float), cudaMemcpyDeviceToHost);
float sum = 0.0f;
for (int i = 0; i < total_runs; ++i) sum += tiempos[i];
std::cout << "Average kernel time: " << (sum / total_runs) << " ms\n";
// Cleanup
delete[] h_data;
cudaEventDestroy(start);
cudaEventDestroy(stop);
printf("Initializing device...\n");
CUDA_RT(cudaInitDevice(0, 0, 0));
printf("Getting SM resources from device...\n");
CUDA_DRV(cuDeviceGetDevResource((CUdevice)0, &input, CU_DEV_RESOURCE_TYPE_SM));
printf("Total number of SMs: %u\n", input.sm.smCount);
printf("Dividing resources: (%u SMs) for the first green context.\n", minCount);
CUDA_DRV(
cuDevSmResourceSplitByCount(
&resources[0], // Array where the groups are written (first group in this case)
&nbGroups, // Number of groups to create
&input, // Original resource (all SMs from the device)
&resources[1], // Remaining resource (SMs not assigned to the group)
0, // flags (usually 0)
minCount // Minimum number of SMs in the first group
)
);
printf("Resources divided.\n");
printf("Generating descriptors\n");
CUDA_DRV(cuDevResourceGenerateDesc(&desc[0], &resources[0], 1));
printf("Creating green contexts...\n");
CUDA_DRV(cuGreenCtxCreate(&gctx[0], desc[0], (CUdevice)0, CU_GREEN_CTX_DEFAULT_STREAM));
printf("Green context A created.\n");
CUDA_DRV(cuDevResourceGenerateDesc(&desc[1], &resources[1], 1));
CUDA_DRV(cuGreenCtxCreate(&gctx[1], desc[1], (CUdevice)0, CU_GREEN_CTX_DEFAULT_STREAM));
printf("Green context B created.\n");
printf("Creating and associating the streams to the GC\n");
CUDA_DRV(cuGreenCtxStreamCreate(&streamA, gctx[0], CU_STREAM_NON_BLOCKING, 0));
CUDA_DRV(cuGreenCtxStreamCreate(&streamB, gctx[1], CU_STREAM_NON_BLOCKING, 0));
printf("Successfully done\n");
for (int i = 0; i < total_runs; i++) {
printf("Launching kernel %d...\n", i);
// Kernel in streamA
cudaEventRecord(startA, (cudaStream_t)streamA);
heavyKernel<<<blocksPerGrid, threadsPerBlock, 0, (cudaStream_t)streamA>>>(d_data, n, iterations);
cudaEventRecord(stopA, (cudaStream_t)streamA);
// Kernel in streamB
cudaEventRecord(startB, (cudaStream_t)streamB);
heavyKernel<<<blocksPerGrid, threadsPerBlock, 0, (cudaStream_t)streamB>>>(d_data, n, iterations); // heavier
cudaEventRecord(stopB, (cudaStream_t)streamB);
// Synchronization
cudaEventSynchronize(stopA);
cudaEventSynchronize(stopB);
float msA = 0.0f, msB = 0.0f;
cudaEventElapsedTime(&msA, startA, stopA);
cudaEventElapsedTime(&msB, startB, stopB);
tiemposA[i] = msA;
tiemposB[i] = msB;
// Error check
err = cudaGetLastError();
if (err != cudaSuccess) {
std::cerr << "CUDA error: " << cudaGetErrorString(err) << std::endl;
return 1;
}
}
// Print averages
float sumA = 0.0f, sumB = 0.0f;
for (int i = 0; i < total_runs; ++i) {
sumA += tiemposA[i];
sumB += tiemposB[i];
}
std::cout << "Average time for kernel A: " << (sumA / total_runs) << " ms\n";
std::cout << "Average time for kernel B: " << (sumB / total_runs) << " ms\n";
// Destroy events
cudaEventDestroy(startA);
cudaEventDestroy(stopA);
cudaEventDestroy(startB);
cudaEventDestroy(stopB);
return 0;
}
Execution results
========= COMPUTE-SANITIZER
Launching kernel 0...
Launching kernel 1...
Launching kernel 2...
Launching kernel 3...
Launching kernel 4...
Launching kernel 5...
Launching kernel 6...
Launching kernel 7...
Launching kernel 8...
Launching kernel 9...
Average kernel time: 4485.83 ms
Initializing device...
CUDA Runtime call at expetimento.cu:121 succeeded.
Getting SM resources from device...
CUDA Driver call at expetimento.cu:124 succeeded.
Total number of SMs: 8
Dividing resources: (1 SMs) for the first green context.
CUDA Driver call at expetimento.cu:129 succeeded.
Resources divided.
Generating descriptors
CUDA Driver call at expetimento.cu:142 succeeded.
Creating green contexts...
CUDA Driver call at expetimento.cu:145 succeeded.
Green context A created.
CUDA Driver call at expetimento.cu:148 succeeded.
CUDA Driver call at expetimento.cu:149 succeeded.
Green context B created.
Creating and associating the streams to the GC
CUDA Driver call at expetimento.cu:153 succeeded.
CUDA Driver call at expetimento.cu:154 succeeded.
Successfully done
Launching kernel 0...
Launching kernel 1...
Launching kernel 2...
Launching kernel 3...
Launching kernel 4...
Launching kernel 5...
Launching kernel 6...
Launching kernel 7...
Launching kernel 8...
Launching kernel 9...
Average time for kernel A: 8965.25 ms
Average time for kernel B: 8965.11 ms
========= ERROR SUMMARY: 0 errors