Hi,
we have upgraded some of our Jetsons to JetPack 5.1 from JetPack 4.6 and noticed substantial latency spikes when running our pytorch-based object detector.
Since we are unable to share our detector, we used Yolov7 for this post. detector.zip (204.9 KB)
Base docker image on JetPack 4.6 was: nvcr.io/nvidia/l4t-pytorch:r32.6.1-pth1.9-py3
and on Jetpack 5.1 we tried: nvcr.io/nvidia/l4t-ml:r35.2.1-py3, nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3, as well as building pytorch for 5.1.
We also tried Yolov5 and converting Yolov7 model to TensorRT .engine file, but all of these methods resulted in latency spikes. Please note that we would like to use pytorch for the time being, and not migrate to DeepStream.
Hi,
Thank you for the answer. We actually use nvpmodel 8 as it has 20W 6 core setup. Your suggestion turned off 4/6 CPU cores, but that did not influence the performance. We also have jetson_clocks inactive on Jetpack 4.6, and we don’t observe latency spikes there.
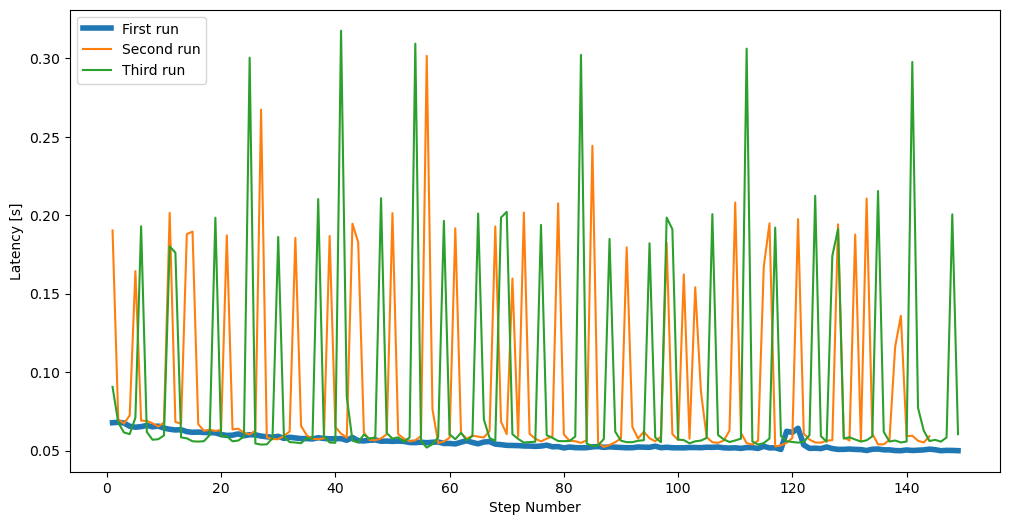
In the meantime, we have noticed that the detection spikes on JetPack 5.1 happen if the device has been idle for some time. In the attached image you can see the performance for the first run after the reboot, and for the second and third runs. As you can see, the first run converges to close to 40ms latency, while all the other consecutive runs have latency spikes.
We could not find how much time the device needs to be idle before the spikes happen, but if the first run after a reboot is done after more than one hour, we always observe latency spikes. Sometimes we will get N consecutive runs without spikes, but once they start happening, they never go away, even if we let the detector run for more than one hour. On the other hand, if the first run did not have spikes, and we let it run for an hour, spikes don’t show up. Note that sometimes we observe latency spikes on the first run after the reboot, but that happens less than 20% of the time and when it happens spikes are less frequent and less prominent (max 160 ms).
We tried to keep the docker container running, and restart the container, but it did not help. This proves that the detector is not the issue and that the device is capable of performing with acceptable latency, but for some reason spikes always manifest after some idle time.
You can test this with:
Comment line 15 import seaborn as sns in utils/plots.py
Yes, that is true. It would throw error when trying to run the code otherwise as we found out that r32 and r35 images can’t be run on Jetpack they aren’t designed for.
Thats great that you ran the example without observing major spikes. The spikes can be induced by external processes. When running the same external process alongside the detect script, we are observing that JP51 is more suspectable to spikes than JP46, this can make the difference between acceptable spikes and unacceptable spikes.
For example, before you run the detect.py script again, run jtop on another terminal.
The plots below show the spikes without jtop running (left side) and the spikes with jtop running (right side). The JP51 spikes with jtop running (bottom right) reach >200ms above average latency. The JP46 spikes with jtop running (top right) reach ~50ms above average latency.
So my question is, why is JP51 more susceptible to major spikes when running an external process? We have experimented with isolating the cpu which improved the spikes but we suspect processes can still interfere in the hardware side especially if they are using the GPU.
We are also facing the simillar issue at our end. We were using Deepstream 6.0 and Jetpack 4.6 to to do inference using yolov8m, and able to get good performance for 2 cameras with negligible latency.
When we migrated to Jetpack 5.1 and Deepstream 6.2, we observed significant latency on the exact same pipeline with yolov8.