Hello everyone!
I am learning to profile pytorch workload follow this blog
I use the code:
import torch
import torch.nn as nn
import torchvision.models as models
# setup
device = 'cuda:0'
model = models.resnet18().to(device)
data = torch.randn(64, 3, 224, 224, device=device)
target = torch.randint(0, 1000, (64,), device=device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
nb_iters = 20
warmup_iters = 10
for i in range(nb_iters):
optimizer.zero_grad()
# start profiling after 10 warmup iterations
if i == warmup_iters: torch.cuda.cudart().cudaProfilerStart()
# push range for current iteration
if i >= warmup_iters: torch.cuda.nvtx.range_push("iteration{}".format(i))
# push range for forward
if i >= warmup_iters: torch.cuda.nvtx.range_push("forward")
output = model(data)
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
loss = criterion(output, target)
if i >= warmup_iters: torch.cuda.nvtx.range_push("backward")
loss.backward()
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
if i >= warmup_iters: torch.cuda.nvtx.range_push("opt.step()")
optimizer.step()
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
# pop iteration range
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
torch.cuda.cudart().cudaProfilerStop()
I can control profiling start time in cli like: nsys profile -w true -t cuda,nvtx,osrt,cudnn,cublas -s cpu --capture-range=cudaProfilerApi --capture-range-end=stop-shutdown --cudabacktrace=true -x true -o my_profile python main.py
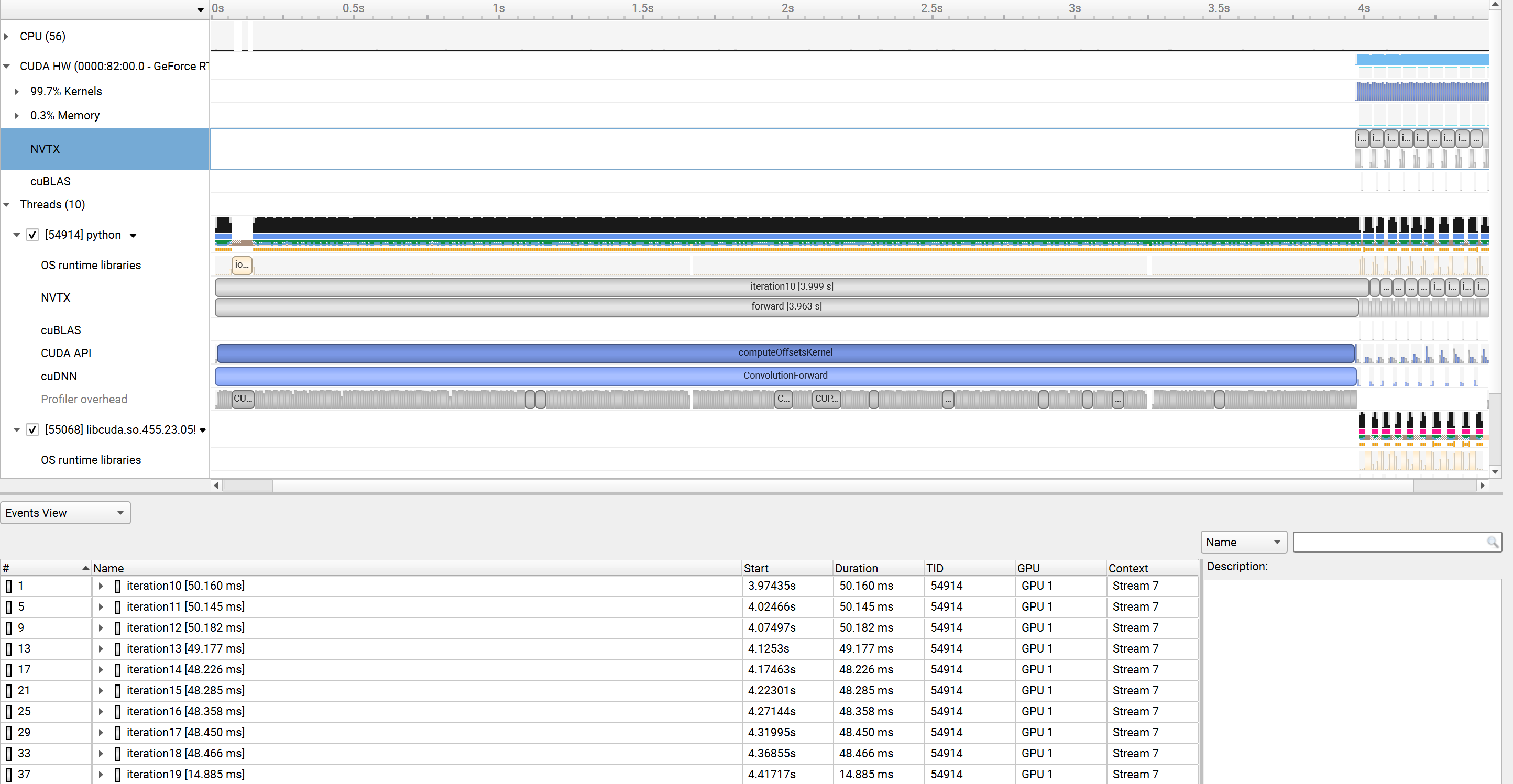
I got result like this:
Question1: Why there are two NVTX items (one under CUDA HW and another under certain python thread)?
And why NVTX under python thread shows iteration 10 taking much longer time? I think with warm up(or dry run), time of iteration 10-19 should be almost same, just like NVTX under CUDA HW shows?
Question2: Is there a way that I can control profiling start time using Nsight System gui just like --capture-range=cudaProfilerApi in cli? Because I always use remote profile, so it is a little inconvenient for me to use remote cli and transfer result back to my PC, which Nsight System gui can do automatically in remote mode. Now using gui I got result like:
Everything is fine, and NVTX result is clear(only one and every iteration takes the same time), but the profiling start since the beginning of the program.
Thanks in advance!
For your first question, the NVTX API is running on the CPU side, so we show where it was run on the CPU, but then we also “project” it onto the GPU, so you can see when on the GPU the kernels launched in that NVTX range actually ran. Basically we draw the NVTX range in the GPU row to cover the kernels launched by it.
For your second question, you can delay the start time of runs launched by the GUI, see the right hand side of the screenshot below:
Thanks for your reply!
So for question 2,there is no way to start profiling at certain function/iteration using gui, right?
And for question 1, now I know the reason why there are two nvtx rows. But I am still very confused about the result:
①:With --capture-range=cudaProfilerApi --capture-range-end=stop-shutdown in cli , the profiling start at certain iteration, but why iteration 10 takes much longer time only when using cli? And I found that if I change the warmup_iters to 9, then the iteration 9 takes much longer time. Maybe because of profiler overhead or something like this?
Using cli:
And if I do not use --capture-range=cudaProfilerApi --capture-range-end=stop-shutdown in cli, the profiling start at the beginning and the result is same as using gui. So if the profiler overhead is the reason, is it a better way that I start profiling at (iteration-1) when using cli?
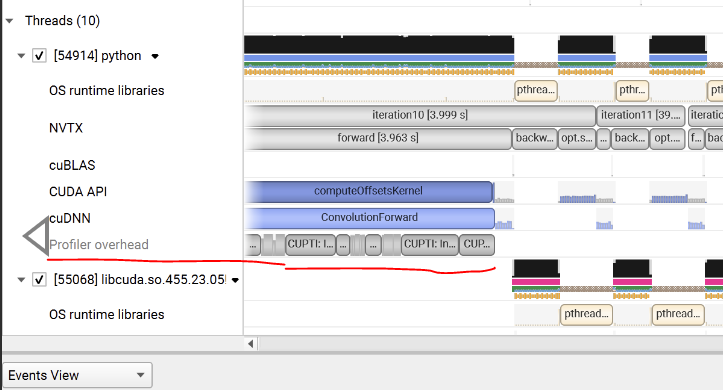
②:You said NVTX row on GPU shows"when the kernels launched in that NVTX range actually ran", why some kernels do not belong to any nvtx range on GPU? I have wrapped every line using nvtx.range_push/pop now.
Yes, we don’t have the support for it in the GUI yet.
Blockquote With --capture-range=cudaProfilerApi --capture-range-end=stop-shutdown in cli , the profiling start at certain iteration, but why iteration 10 takes much longer time only when using cli ? And I found that if I change the warmup_iters to 9, then the iteration 9 takes much longer time. Maybe because of profiler overhead or something like this?
Yes, the first iteration that is profiled incurs the profiling overhead. If you look in the “Profiler overhead” timeline row, you will see the ranges indicating what the profiler was doing during the first iteration that was profiled.
This overhead unfortunately cannot be avoided. You will just have to ignore the timings info of the iteration that incurs the profiling overhead.
Blockquote You said NVTX row on GPU shows"when the kernels launched in that NVTX range actually ran", why some kernels do not belong to any nvtx range on GPU? I have wrapped every line using nvtx.range_push/pop now.
In the screenshot you shared, the kernels you have highlighted with the red box are shown under the NVTX range “iteration 10”, so they do belong to this NVTX range. May be you are misunderstanding what’s being shown?
In the screenshot you shared, the kernels you have highlighted with the red box are shown under the NVTX range “iteration 10”
They do belong to iteration 10, yes. In fact, I mean they do not belong to range “forward” or “loss” or “backward” or “opt.step()”, which is confusing because I have wrapped every line using nvtx.range_push/pop now:
nb_iters = 20
warmup_iters = 9
for i in range(nb_iters):
optimizer.zero_grad()
# # start profiling after 10 warmup iterations
if i == warmup_iters: torch.cuda.cudart().cudaProfilerStart()
#
# push range for current iteration
if i >= warmup_iters: torch.cuda.nvtx.range_push("iteration{}".format(i))
# push range for forward
if i >= warmup_iters: torch.cuda.nvtx.range_push("forward")
output = model(data)
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
if i >= warmup_iters: torch.cuda.nvtx.range_push("loss")
loss = criterion(output, target)
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
if i >= warmup_iters: torch.cuda.nvtx.range_push("backward")
loss.backward()
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
if i >= warmup_iters: torch.cuda.nvtx.range_push("opt.step()")
optimizer.step()
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
#
# pop iteration range
if i >= warmup_iters:torch.cuda.nvtx.range_pop()
#
torch.cuda.cudart().cudaProfilerStop()
I see. Could you try adding a NVTX range around the optimizer.zero_grad() line as well? Could you share the report file so that I can check if there is a bug in the NVTX projections onto GPU timeline?
Could you try adding a NVTX range around the optimizer.zero_grad() line as well?
As your suggestion, now the code is:
import torch
import torch.nn as nn
import torchvision.models as models
# setup
device = 'cuda:1'
model = models.resnet18().to(device)
data = torch.randn(64, 3, 224, 224, device=device)
target = torch.randint(0, 1000, (64,), device=device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
nb_iters = 20
warmup_iters = 9
for i in range(nb_iters):
# # start profiling after 10 warmup iterations
if i == warmup_iters: torch.cuda.cudart().cudaProfilerStart()
#
# push range for current iteration
if i >= warmup_iters: torch.cuda.nvtx.range_push("iteration{}".format(i))
if i >= warmup_iters: torch.cuda.nvtx.range_push("opt_zero")
optimizer.zero_grad()
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
# push range for forward
if i >= warmup_iters: torch.cuda.nvtx.range_push("forward")
output = model(data)
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
if i >= warmup_iters: torch.cuda.nvtx.range_push("loss")
loss = criterion(output, target)
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
if i >= warmup_iters: torch.cuda.nvtx.range_push("backward")
loss.backward()
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
if i >= warmup_iters: torch.cuda.nvtx.range_push("opt.step()")
optimizer.step()
if i >= warmup_iters: torch.cuda.nvtx.range_pop()
#
# pop iteration range
if i >= warmup_iters:torch.cuda.nvtx.range_pop()
#
torch.cuda.cudart().cudaProfilerStop()
Some kernels still do not belong to any range inside “iteration” range. I have upload the latest report. Many thanks! report12.nsys-rep (5.6 MB)
Thanks for sharing the report. Attaching a screenshot where I selected a kernel that doesn’t belong to any other range inside the iteration range. The cyan highlight gives you the corresponding CUDA API call issued from the OS thread on the CPU.
From the timeline view I can tell that the kernels being launched as part of the backward step are actually being issued from a different thread (thread 38977). The NVTX push-pop ranges are only associated with the thread where they are added i.e. thread 38802. This is expected and not a bug in nsys.
Thanks a lot! I think I may have figured everything out.
Some kernel do not belong to any range inside the iteration range, that is because they are launched on a different thread 38977, while nvtx is added on thread 38802.
The length of nvtx ranges on GPU and thread 38802 are different, both inside “iteration” range and “iteration” range itself, like:
I think that is because nvtx on GPU is about kernel execution while nvtx on thread 38802(CPU) is about kernel launch(nsys: “call to xxx”), and kernel launch is always asynchronized. So the nvtx ranges on thread 38802(CPU) show the time spent on kernel launch, while the nvtx ranges on GPU show the time spent on kernel execution.