After decoding. The skip-frames will drop the frame before decoding.
Could you attach the fps and the loading information in this scenario?
After decoding. The skip-frames will drop the frame before decoding.
Could you attach the fps and the loading information in this scenario?
[application]
enable-perf-measurement=1
perf-measurement-interval-sec=5
#gie-kitti-output-dir=streamscl
[tiled-display]
enable=0
rows=2
columns=2
width=1280
height=720
gpu-id=0
#(0): nvbuf-mem-default - Default memory allocated, specific to particular platform
#(1): nvbuf-mem-cuda-pinned - Allocate Pinned/Host cuda memory, applicable for Tesla
#(2): nvbuf-mem-cuda-device - Allocate Device cuda memory, applicable for Tesla
#(3): nvbuf-mem-cuda-unified - Allocate Unified cuda memory, applicable for Tesla
#(4): nvbuf-mem-surface-array - Allocate Surface Array memory, applicable for Jetson
nvbuf-memory-type=0
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
type=3
uri=file://../../streams/sample_1080p_h264.mp4
#uri=file:///home/runone/program/folder/testvideo/shareddisk/ffmpeg_video/yace_yongdu.mp4
#uri=rtmp://127.0.0.1:10936/live/yace201
num-sources=60
drop-frame-interval=0
gpu-id=0
# (0): memtype_device - Memory type Device
# (1): memtype_pinned - Memory type Host Pinned
# (2): memtype_unified - Memory type Unified
cudadec-memtype=0
[sink0]
enable=1
#Type - 1=FakeSink 2=EglSink/nv3dsink (Jetson only) 3=File
type=1
sync=0
source-id=0
gpu-id=0
nvbuf-memory-type=0
[sink1]
enable=0
#Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming
type=1
#1=mp4 2=mkv
container=1
#1=h264 2=h265
codec=1
#encoder type 0=Hardware 1=Software
enc-type=0
sync=0
#iframeinterval=10
bitrate=2000000
#H264 Profile - 0=Baseline 2=Main 4=High
#H265 Profile - 0=Main 1=Main10
# set profile only for hw encoder, sw encoder selects profile based on sw-preset
profile=0
output-file=out.mp4
source-id=0
[sink2]
enable=0
#Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming
type=1
#1=h264 2=h265
codec=1
#encoder type 0=Hardware 1=Software
enc-type=0
#sw-preset=1 #for SW enc=(0)None (1)ultrafast (2)superfast (3)veryfast (4)faster
#(5)fast (6)medium (7)slow (8)slower (9)veryslow (10)placebo
sync=0
#iframeinterval=10
bitrate=400000
#H264 Profile - 0=Baseline 2=Main 4=High
#H265 Profile - 0=Main 1=Main10
# set profile only for hw encoder, sw encoder selects profile based on sw-preset
profile=0
# set below properties in case of RTSPStreaming
rtsp-port=8554
udp-port=5400
[osd]
enable=0
gpu-id=0
border-width=1
text-size=15
text-color=1;1;1;1;
text-bg-color=0.3;0.3;0.3;1
font=Serif
show-clock=0
clock-x-offset=800
clock-y-offset=820
clock-text-size=12
clock-color=1;0;0;0
nvbuf-memory-type=0
[streammux]
gpu-id=0
##Boolean property to inform muxer that sources are live
live-source=0
buffer-pool-size=4
batch-size=60
##time out in usec, to wait after the first buffer is available
##to push the batch even if the complete batch is not formed
batched-push-timeout=40000
## Set muxer output width and height
width=1920
height=1080
##Enable to maintain aspect ratio wrt source, and allow black borders, works
##along with width, height properties
enable-padding=0
nvbuf-memory-type=0
## If set to TRUE, system timestamp will be attached as ntp timestamp
## If set to FALSE, ntp timestamp from rtspsrc, if available, will be attached
# attach-sys-ts-as-ntp=1
# config-file property is mandatory for any gie section.
# Other properties are optional and if set will override the properties set in
# the infer config file.
[primary-gie]
enable=0
gpu-id=0
model-engine-file=../../models/Primary_Detector/resnet18_trafficcamnet.etlt_b60_gpu0_int8.engine
#model-engine-file=../../models/Primary_Detector/resnet18_trafficcamnet.etlt_b68_gpu0_int8.engine
#model-engine-file=/home/runone/program/folder/model/yolov8s_exp85_736_11.engine
batch-size=60
#Required by the app for OSD, not a plugin property
bbox-border-color0=1;0;0;1
bbox-border-color1=0;1;1;1
bbox-border-color2=0;0;1;1
bbox-border-color3=0;1;0;1
interval=0
gie-unique-id=1
nvbuf-memory-type=0
config-file=config_infer_primary.txt
#config-file=/home/runone/deepstream-implatform/deepstream-common/config_infer_primary_yoloV8.txt
[tracker]
enable=0
# For NvDCF and NvDeepSORT tracker, tracker-width and tracker-height must be a multiple of 32, respectively
tracker-width=960
tracker-height=544
ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.so
# ll-config-file required to set different tracker types
ll-config-file=config_tracker_IOU.yml
# ll-config-file=config_tracker_NvSORT.yml
#ll-config-file=config_tracker_NvDCF_perf.yml
# ll-config-file=config_tracker_NvDCF_accuracy.yml
# ll-config-file=config_tracker_NvDeepSORT.yml
gpu-id=0
display-tracking-id=1
[secondary-gie0]
enable=0
#model-engine-file=../../models/Secondary_VehicleTypes/resnet18_vehicletypenet.etlt_b16_gpu0_int8.engine
model-engine-file=../../models/Secondary_VehicleTypes/resnet18_vehicletypenet.etlt_b32_gpu0_int8.engine
gpu-id=0
batch-size=32
gie-unique-id=4
operate-on-gie-id=1
operate-on-class-ids=0;
config-file=config_infer_secondary_vehicletypes.txt
[secondary-gie1]
enable=0
#model-engine-file=../../models/Secondary_VehicleMake/resnet18_vehiclemakenet.etlt_b16_gpu0_int8.engine
model-engine-file=../../models/Secondary_VehicleTypes/resnet18_vehicletypenet.etlt_b32_gpu0_int8.engine
batch-size=32
gpu-id=0
gie-unique-id=5
operate-on-gie-id=1
operate-on-class-ids=0;
config-file=config_infer_secondary_vehiclemake.txt
[tests]
file-loop=1
When using the above configuration, the number of frames decoded is obviously much higher than before
**PERF: 48.64 (48.11) 48.64 (48.57) 48.64 (48.80) 48.64 (48.70) 48.64 (48.00) 48.64 (48.17) 48.64 (48.33) 48.64 (48.53) 48.64 (47.80) 48.64 (47.91) 48.64 (47.90) 48.64 (47.95) 48.64 (47.77) 48.64 (48.63) 48.64 (47.71) 48.64 (48.25) 48.64 (47.94) 48.64 (48.67) 48.64 (48.44) 48.64 (47.76) 48.64 (48.34) 48.64 (47.81) 48.64 (48.81) 48.64 (48.39) 48.64 (48.45) 48.64 (48.30) 48.64 (48.81) 48.64 (48.24) 48.64 (47.67) 48.64 (48.65) 48.64 (48.33) 48.64 (47.66) 48.64 (48.83) 48.64 (48.15) 48.64 (48.79) 48.64 (48.02) 48.64 (47.97) 48.64 (48.20) 48.64 (48.68) 48.64 (48.25) 48.64 (48.74) 48.64 (48.12) 48.64 (47.68) 48.64 (48.50) 48.64 (47.84) 48.64 (48.60) 48.64 (48.21) 48.64 (48.08) 48.64 (47.67) 48.64 (48.31) 48.64 (48.72) 48.64 (48.47) 48.64 (47.76) 48.64 (48.73) 48.64 (48.30) 48.64 (48.01) 48.64 (48.57) 48.64 (48.80) 48.64 (47.82) 48.64 (48.35)
**PERF: 48.37 (48.12) 48.37 (48.56) 48.37 (48.78) 48.37 (48.68) 48.37 (48.02) 48.37 (48.18) 48.37 (48.33) 48.37 (48.53) 48.37 (47.83) 48.37 (47.94) 48.37 (47.93) 48.37 (47.97) 48.37 (47.80) 48.37 (48.62) 48.37 (47.75) 48.37 (48.26) 48.37 (47.96) 48.37 (48.66) 48.37 (48.43) 48.37 (47.79) 48.37 (48.34) 48.37 (47.84) 48.37 (48.79) 48.37 (48.39) 48.37 (48.44) 48.37 (48.30) 48.37 (48.79) 48.37 (48.25) 48.37 (47.71) 48.37 (48.64) 48.37 (48.33) 48.37 (47.70) 48.37 (48.80) 48.37 (48.16) 48.37 (48.77) 48.37 (48.04) 48.37 (47.99) 48.37 (48.21) 48.37 (48.67) 48.37 (48.26) 48.37 (48.72) 48.37 (48.13) 48.37 (47.72) 48.37 (48.50) 48.37 (47.87) 48.37 (48.59) 48.37 (48.22) 48.37 (48.10) 48.37 (47.71) 48.37 (48.31) 48.37 (48.70) 48.37 (48.46) 48.37 (47.79) 48.37 (48.71) 48.37 (48.30) 48.37 (48.03) 48.37 (48.56) 48.37 (48.78) 48.37 (47.85) 48.37 (48.35)
**PERF: FPS 0 (Avg) FPS 1 (Avg) FPS 2 (Avg) FPS 3 (Avg) FPS 4 (Avg) FPS 5 (Avg) FPS 6 (Avg) FPS 7 (Avg) FPS 8 (Avg) FPS 9 (Avg) FPS 10 (Avg) FPS 11 (Avg) FPS 12 (Avg) FPS 13 (Avg) FPS 14 (Avg) FPS 15 (Avg) FPS 16 (Avg) FPS 17 (Avg) FPS 18 (Avg) FPS 19 (Avg) FPS 20 (Avg) FPS 21 (Avg) FPS 22 (Avg) FPS 23 (Avg) FPS 24 (Avg) FPS 25 (Avg) FPS 26 (Avg) FPS 27 (Avg) FPS 28 (Avg) FPS 29 (Avg) FPS 30 (Avg) FPS 31 (Avg) FPS 32 (Avg) FPS 33 (Avg) FPS 34 (Avg) FPS 35 (Avg) FPS 36 (Avg) FPS 37 (Avg) FPS 38 (Avg) FPS 39 (Avg) FPS 40 (Avg) FPS 41 (Avg) FPS 42 (Avg) FPS 43 (Avg) FPS 44 (Avg) FPS 45 (Avg) FPS 46 (Avg) FPS 47 (Avg) FPS 48 (Avg) FPS 49 (Avg) FPS 50 (Avg) FPS 51 (Avg) FPS 52 (Avg) FPS 53 (Avg) FPS 54 (Avg) FPS 55 (Avg) FPS 56 (Avg) FPS 57 (Avg) FPS 58 (Avg) FPS 59 (Avg)
**PERF: 48.91 (48.15) 48.91 (48.57) 48.91 (48.78) 48.91 (48.69) 48.91 (48.06) 48.91 (48.21) 48.91 (48.35) 48.91 (48.54) 48.91 (47.88) 48.91 (47.98) 48.91 (47.97) 48.91 (48.01) 48.91 (47.85) 48.91 (48.63) 48.91 (47.80) 48.91 (48.29) 48.91 (48.00) 48.91 (48.67) 48.91 (48.45) 48.91 (47.84) 48.91 (48.36) 48.91 (47.88) 48.91 (48.79) 48.91 (48.41) 48.91 (48.46) 48.91 (48.33) 48.91 (48.79) 48.91 (48.28) 48.91 (47.76) 48.91 (48.65) 48.91 (48.35) 48.91 (47.75) 48.91 (48.80) 48.91 (48.19) 48.91 (48.77) 48.91 (48.08) 48.91 (48.03) 48.91 (48.24) 48.91 (48.68) 48.91 (48.29) 48.91 (48.72) 48.91 (48.16) 48.91 (47.77) 48.91 (48.51) 48.91 (47.91) 48.91 (48.60) 48.91 (48.25) 48.91 (48.13) 48.91 (47.76) 48.91 (48.34) 48.91 (48.70) 48.91 (48.48) 48.91 (47.84) 48.91 (48.71) 48.91 (48.33) 48.91 (48.07) 48.91 (48.57) 48.91 (48.78) 48.91 (47.89) 48.91 (48.37)
**PERF: 48.37 (48.17) 48.37 (48.57) 48.37 (48.77) 48.37 (48.68) 48.37 (48.08) 48.37 (48.23) 48.37 (48.37) 48.37 (48.54) 48.37 (47.91) 48.37 (48.01) 48.37 (48.00) 48.37 (48.04) 48.37 (47.88) 48.37 (48.63) 48.37 (47.84) 48.37 (48.30) 48.37 (48.03) 48.37 (48.66) 48.37 (48.46) 48.37 (47.87) 48.37 (48.37) 48.37 (47.92) 48.37 (48.78) 48.37 (48.42) 48.37 (48.47) 48.37 (48.34) 48.37 (48.78) 48.37 (48.29) 48.37 (47.80) 48.37 (48.64) 48.37 (48.37) 48.37 (47.79) 48.37 (48.79) 48.37 (48.21) 48.37 (48.76) 48.37 (48.10) 48.37 (48.05) 48.37 (48.26) 48.37 (48.67) 48.37 (48.30) 48.37 (48.72) 48.37 (48.18) 48.37 (47.81) 48.37 (48.51) 48.37 (47.94) 48.37 (48.60) 48.37 (48.27) 48.37 (48.15) 48.37 (47.80) 48.37 (48.35) 48.37 (48.70) 48.37 (48.49) 48.37 (47.87) 48.37 (48.71) 48.37 (48.34) 48.37 (48.09) 48.37 (48.57) 48.37 (48.77) 48.37 (47.93) 48.37 (48.38)
After removing inference and other steps, the frame rate of this decoding appears to be close to the data of the file we obtained before
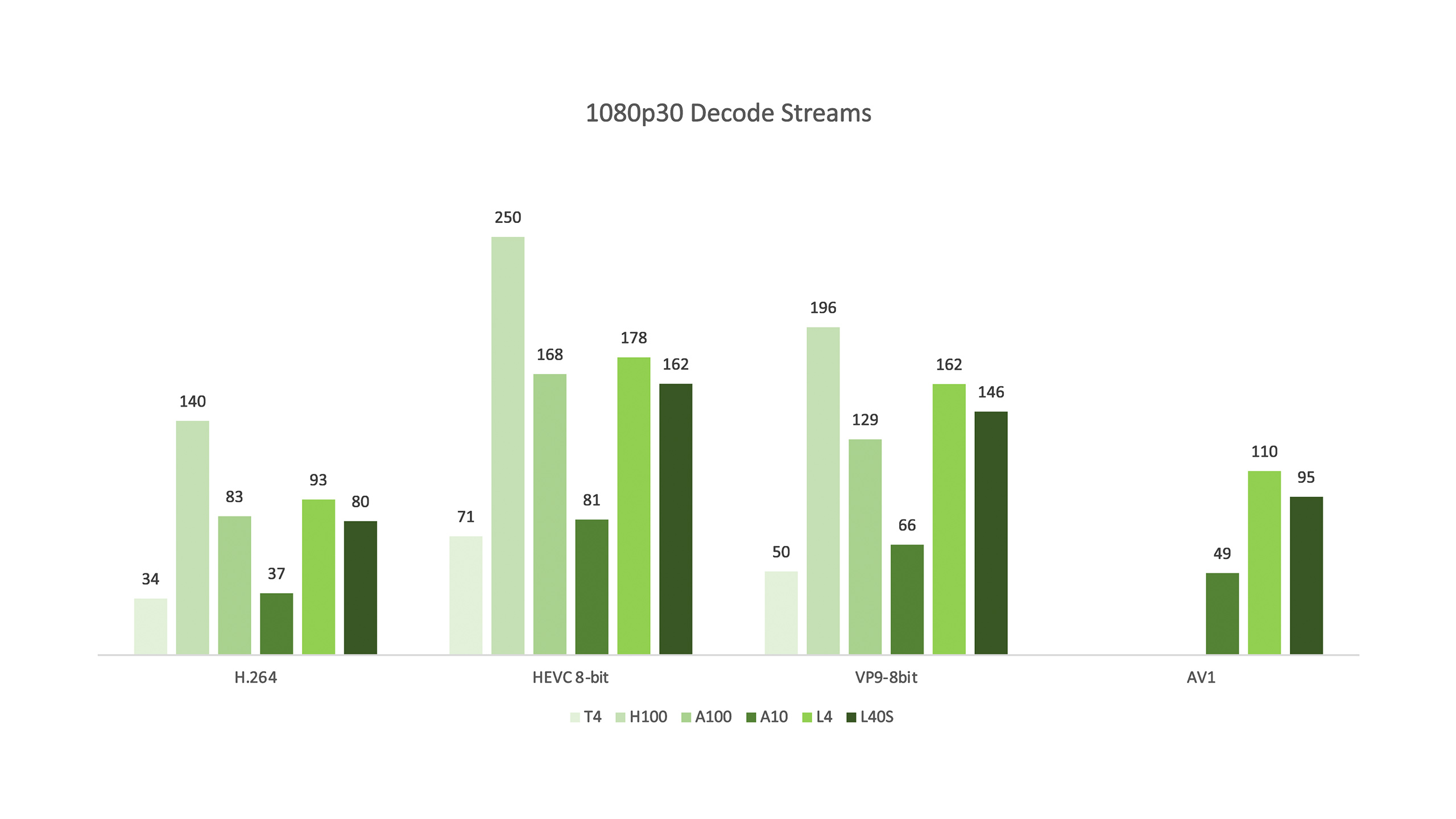
This is normal. You can compare that with the official data we attached on the L4 card.
Decoder Only: 93 1080P30fps h264
DeepStream Inference: 68 1080P30fps h264
The performance of simple decoding is better than that of decoding and inference.
Both the decoding and the inference will use the graphics memory, which will have a certain resource competition.
if use 2K or 4K stream video, Do you have some data? in RTX 3090 or T4
The performance of T4 here includes: Performance — DeepStream documentation
Sorry, I don’t have a 3090 graphics card
only has 1080p stream performance dafa,
It’s still this pipeline
I found that this problem only occurs when the input source is 1080p, while when the input source is 720P, the decoder is load balanced.
Okay, I found that only by setting these to:
nvstreammux.set_property('width', 1920)
nvstreammux.set_property('height', 1080)
, decoding will be uniform and analysis will be normal
Is this normal? I don’t quite understand why this parameter causes uneven decoding of 1080p streams
If you set the width and height to nvstreammux, we will scale the video to the dimension you set. We recommend that you set these to the dimension of your source. This will reduce the time consumed by the scale process, but also improve the accuracy.
You can refer to our Gst-nvstreammux gst-properties.
Okay, even though it may improve accuracy, I don’t understand why setting it to:
nvstreammux.set_property(‘width’, 1280)
nvstreammux.set_property(‘height’,720 )
would result in abnormal decoding,especially for 1080p RTMP
Could you explain what the abnormal decoding means?
As I attached before, if the source is 1080p, you set 720p to the nvstreammux. We’ll scale the video from 1080p to 720p in the nvstreammux first. This will take extra time consumption and gpu memory. And if you are using rtmp source, you’d better set the live-source=1 to the nvstreammux.
What I mean is, when the parameter is set to :
nvstreammux.set_property(‘width’, 1280)
nvstreammux.set_property(‘height’,720 )
60 1080p inputs, the decoding looks very unbalanced and the inference does not meet my expectations. The UTL of the graphics card is not high:
I don’t understand what the bottleneck here is
In this case, I set the parameters to:
live-source=1
It doesn’t seem to have much effect
Only by setting the parameter to:
nvstreammux.set_property(‘width’, 1920)
nvstreammux.set_property(‘height’, 1080)
everything looks normal, but setting it here means I still need to do resizing myself
There is extra video scaling(done with GPU) when the “width” and “height” of nvstreammux are not the same as the input video’s resolution. To set the the “width” and “height” of nvstreammux as the same to the input video resolution will help to avoid the scaling which will help to save the time before inferencing.
Why do you need to do resizing? Where and for what?
The resize here is a requirement for my own business, and I hope to receive a final output of 720p images and boxes.
According to your suggestion, when the input source is 1080p, nvstreammux should also be set to 1080p for better performance
So is the uneven decoding caused by the parameter settings here?
If it is a mixed stream, such as 1080p and 720p, should it also be set to 1080p?
Can you elaborate on what this means? It is best to attach the data to explain in detail, like how uneven. You can attach the 720p data and 1080p data respectively. How exactly does this affect your pipeline?
No. If it is a mixed stream, you can set that according to your needs. If all the videos are the same resolution, we recommend that you set nvstreammux to this resolution.
I determined the uneven decoding from nvidia-smi dmon -i 0
At the same time, checking the UTL utilization rate of the graphics card is not high, and the inference frame rate is around 3fps instead of the set 6fps, because I set drop_frame_interval=4
The above anomalies do not occur when the input source is 720p, only when the input source is 1080p.
With the increase of the number of inputs, the fps of inference has decreased to 3fps by about 30
What more information do you need me to provide?
There are too many variables in your debugging process at once, so the description may not be very clear. Let me summarize this for a moment, so you can see if there are any questions.
deepstream-app and our models to get the maximum number of 1080p30fps h264 local sources that your device can handle.First of all, the comparison between the two scenarios is not meaningful. Because the two scenarios are very different. So let’s analyze your scenario separately.
We still recommend controlling a single variable to debug.
So could you describe in detail these same variables and the only variable that is different, and the result from that 2 scenarios?
Also since your pipeline is simple, could you attach your whole source code, config file and models? We can write a C version for comparison.
This topic was automatically closed 14 days after the last reply. New replies are no longer allowed.






{kind=link}