Unfortunately on current hardware the grid is only 2D, which makes it tricky to calculate 3D indicies. To makes things worse, integer divide and modulo (which you would normally use to calculate your own 3d indicies) are very expensive on current GPUs.
The best solution I’ve seen is this code (credit to Jonathan Cohen, hopefully he doesn’t mind me posting it here).
The setup code is:
[codebox]host void launchThreads(int nx, int ny, int nz) {
int threadsInX = 16;
int threadsInY = 4;
int threadsInZ = 4;
int blocksInX = (nx+threadsInX-1)/threadsInX;
int blocksInY = (ny+threadsInY-1)/threadsInY;
int blocksInZ = (nz+threadsInZ-1)/threadsInZ;
dim3 Dg = dim3(blocksInX, blocksInY*blocksInZ);
dim3 Db = dim3(threadsInX, threadsInY, threadsInZ);
then in the kernel I know what each index means in terms of x y and z, or am I getting something wrong? The disadvantage is that it will use some memory but no further calculations than the normal idx calculation is needed in the kernel.
I am currently having a very similar problem. However, I found another way to calculate the coordinates, which is only possible because i know that my x-dimension never exeeds 512 (which is the maximum number of threads in a block). Simply create an 1D block of threads, and use the grid for the other 2 dimensions:
dim3 Db(DIMX, 1, 1);
dim3 Dg(DIMZ, DIMY);
Then in the kernel, the x, y, and z coordinates are just:
int x = threadIdx.x;
int y = blockIdx.y;
int z = blockIdx.x;
Which is great, because it requires no calculations. But then I get into trouble as you mentioned, because how does I correctly calculate the array index? If the dimensions are a power of 2, it works when I do this:
int idx = x + y*blockDim.x + z*blockDim.x*gridDim.y;
When I use any other dimensions than powers of 2, the indexing becomes wrong. I expect that it is because I need to use the pitch, or the xsize and ysize from the cudaPitchedPtr.
I relied on the sample given in the CUDA 2.1 manual to access elements in a malloc3D allocated structure :
// host code
cudaPitchedPtr devPitchedPtr;
cudaExtent extent = make_cudaExtent(64, 64, 64);
cudaMalloc3D(&devPitchedPtr, extent);
myKernel<<<100, 512>>>(devPitchedPtr, extent);
// device code
__global__ void myKernel(cudaPitchedPtr devPitchedPtr,
cudaExtent extent)
{
char* devPtr = devPitchedPtr.ptr;
size_t pitch = devPitchedPtr.pitch;
size_t slicePitch = pitch * extent.height;
for (int z = 0; z < extent.depth; ++z) {
char* slice = devPtr + z * slicePitch;
for (int y = 0; y < extent.height; ++y) {
float* row = (float*)(slice + y * pitch);
for (int x = 0; x < extent.width; ++x) {
float element = row[x];
}
}
}
}
but I have troubles when data dimensions differ from a power of 2, as mentioned in previous posts (approach similar to Glimberg). does this mean this sample code is wrong ? I am actually using 2.0, can this make a difference ?
Using Cohen’s approach for workload assign, what would be the best way reserve and copy memory to the device? I’m using a 3D indexed (data[z][y]) data volume. I guess cudaMemcpy3D could be the best, but… should I use a cudaArray (copyParams.dstArray) or a regular array pointer (copyParams.dstPtr)?
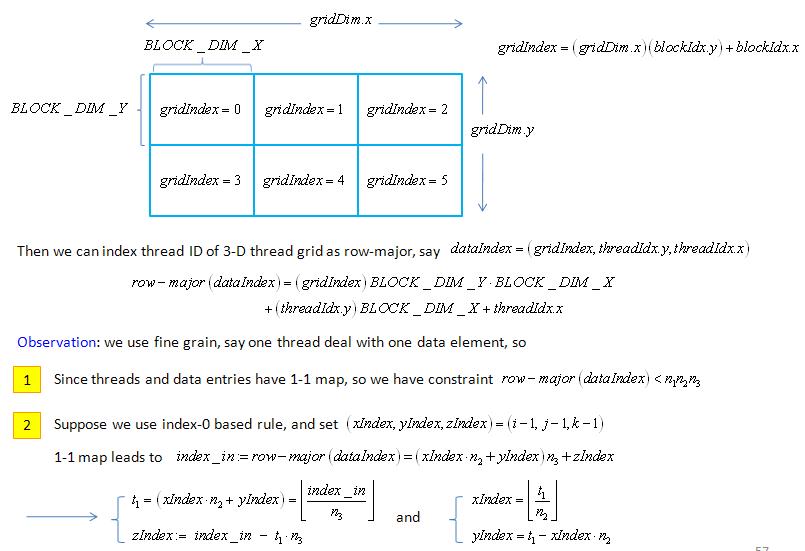
static __global__ void naive_3D( doublereal *dst, doublereal *src,
unsigned int n1, unsigned int n2, unsigned int n3,
double one_over_n2, double one_over_n3, unsigned int sizeOfData )
{
double tmp1;
unsigned int t1, xIndex, yIndex, zIndex, index_in, index_out, gridIndex;
// step 1: compute gridIndex in 1-D and 1-D data index "index_in"
gridIndex = blockIdx.y * gridDim.x + blockIdx.x;
index_in = ( gridIndex * BLOCK_DIM_Y + threadIdx.y )*BLOCK_DIM_X + threadIdx.x;
// step 2: extract 3-D data index via
// index_in = row-map(i,j,k) = (i-1)*n2*n3 + (j-1)*n3 + (k-1)
// where xIndex = i-1, yIndex = j-1, zIndex = k-1
if ( index_in < sizeOfData ){
tmp1 = __uint2double_rn( index_in );
tmp1 = tmp1 * one_over_n3;
t1 = __double2uint_rz( tmp1 );
zIndex = index_in - n3*t1;
tmp1 = __uint2double_rn( t1 );
tmp1 = tmp1 * one_over_n2;
xIndex = __double2uint_rz( tmp1 );
yIndex = t1 - n2 * xIndex;
... your code
}// for each valid address
}
I don’t understand why are you extracting the index? if you have index_in you can access the data right?
and in the code, if i have an i,j,k index that i wish to access its corresponding data element, then i is blockIdx.xblockDim.x + threadIdx.x , j is blockIdx.yblockDim.y + threadIdx.y, and k is gridIndex right? and you use index_in to access the element in linear memory
or
i is threadIdx.x , j is threadIdx.y, and k is gridIndex ?
… do you think this is right, or have I misunderstoood the indexing structure?
In addition (forgive me, I’m still very new to this game!), I’ll be using input data of type cufftComplex - which is an interleaved float type (two floats for one element). I don’t think I actually need to change the indexing to compensate for this, but I’m concerned about block size - should I change the block dimensions to 8 instead of 16, to ensure that a block occupies the same amount of memory?
Lastly, thankyou so much for the effort you’ve put into the diagrams above - they’ve really helped me learn a lot about how all of this works!




{kind=link}