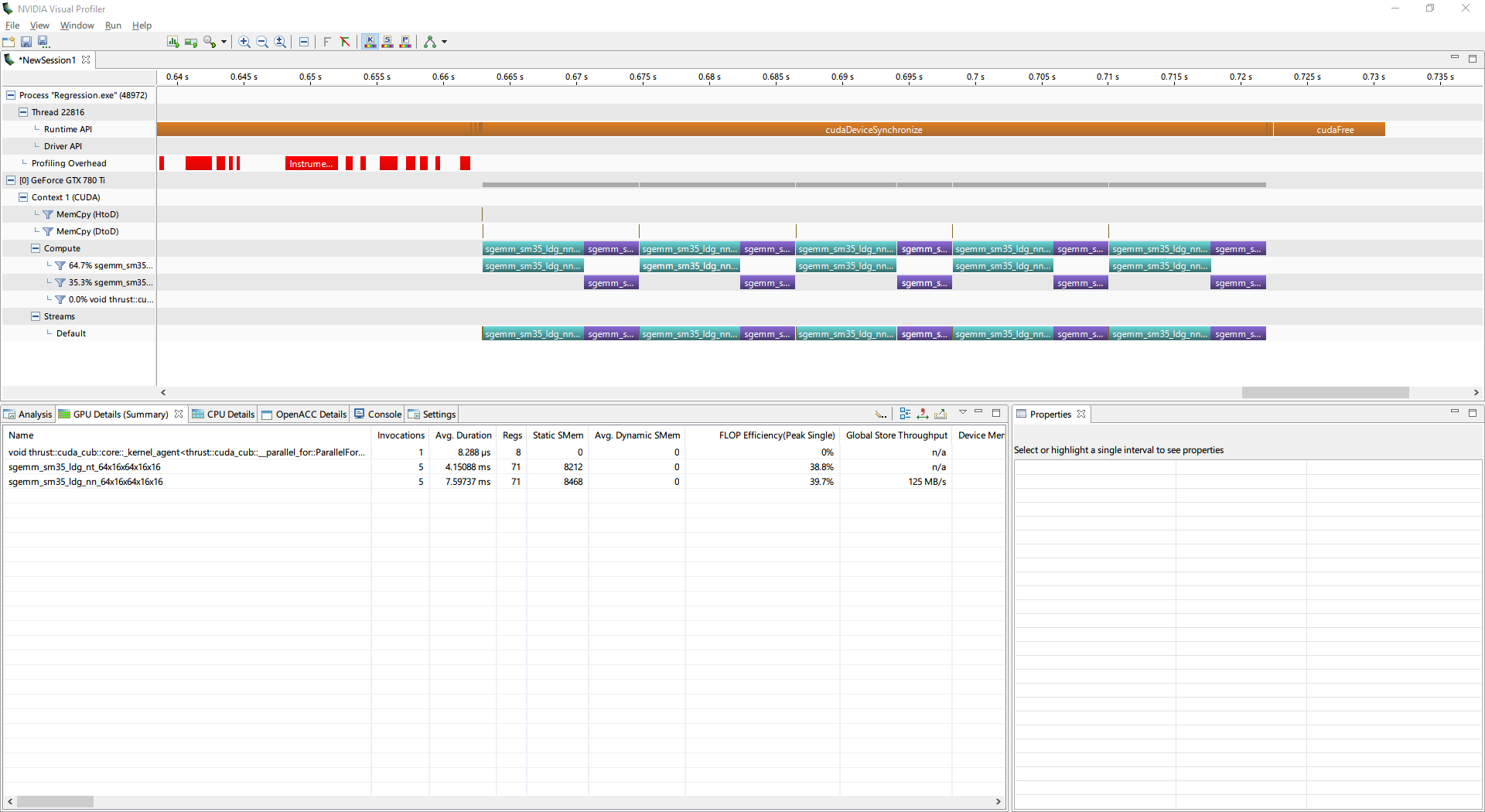
I was trying to build a simple linear regression application. It uses only 2 sGEMM from cuBLAS.
I noticed that, from nvvp, the performance is not so good: around 40% peak FLOPS achieved. When I was testing cuBLAS (using some other data), the results were much better.
I wonder what can I do to improve the performance?
FWIW, I wrote wrappers to keep the data is row-major layout, i.e., if I copy the data from the device after calculation, the data will be in row major. (done by exchanging the order of matrices when calling gemm).
I also saw that, when I change matrix size, the function name changed from magma_lds128_… to sgemm_sm35_ldg_nn_64x16x64x16x16. Should this concern me?
Very likely not. Linear algebra libraries often contain multiple versions of a particular operation. At run time, a heuristic then picks the most appropriate one. Variants may be differentiated by (1) matrix or vector size, (2) matrix transpose mode, (3) matrix shape (aspect ratio), (4) processor architecture. It should be clear that this can lead to a huge variety of possible variants in the case of critically important operations such as GEMM.
It is possible that the heuristic makes a sub-optimal choice when it picks the “optimal” variant, but it is unlikely that you would be able to prove that. It is also possible that none of the available variants handle a particular use case optimally. In practical terms, the high cost of software engineering limits the number of variants that can be included in a library.
Generally speaking, since GPUs are designed for massive parallelism (on the order of tens of thousands of threads), linear algebra libraries perform best when matrices are large (say, dimensions > 512) and square-ish in shape. For very small matrices (say, dimensions < 32) one can often achieve very good performance by batching operations for multiple matrices. Most challenging are therefore medium-sized matrices: the GPU may not be used optimally for those. But even in those cases the performance will generally still be much better than if the work were performed on a CPU.
I’m using a 780Ti card, I’m not sure if it limits the performance. But when I used to run tests with matrices of size 4096x4096, it delivered some very good performance, like 75% of the peak (almost twice what I got here).
My questions will be,
what sizes will likely to be considered to form a big matrix?
should I ensure the all sizes are multiples of 32?
should I try to keep everything a square matrix (or at least close to square)?
I already gave some very approximate criteria for matrix size in #2. Making the dimensions a multiple of 32 would likely eliminate edge-case handling in the GEMM implementations. Depending on how thread blocks in GEMM kernels are organized, keeping all dimensions a multiple of 16 might be sufficient for that. Matrices that are close to square in shape will generally result in better performance compared to matrices with extreme aspect ratios. There are usually some small performance differences (+/-5%) based on transpose modes as well.
With 4K x 4K matrices you should already be approaching the speed of light for GEMM. This is easy to see if you plot the FLOPS for square matrices whose dimensions are increasing powers of two (e.g. 256, 512, 1024, …). The graph should asymptotically approach an upper limit.