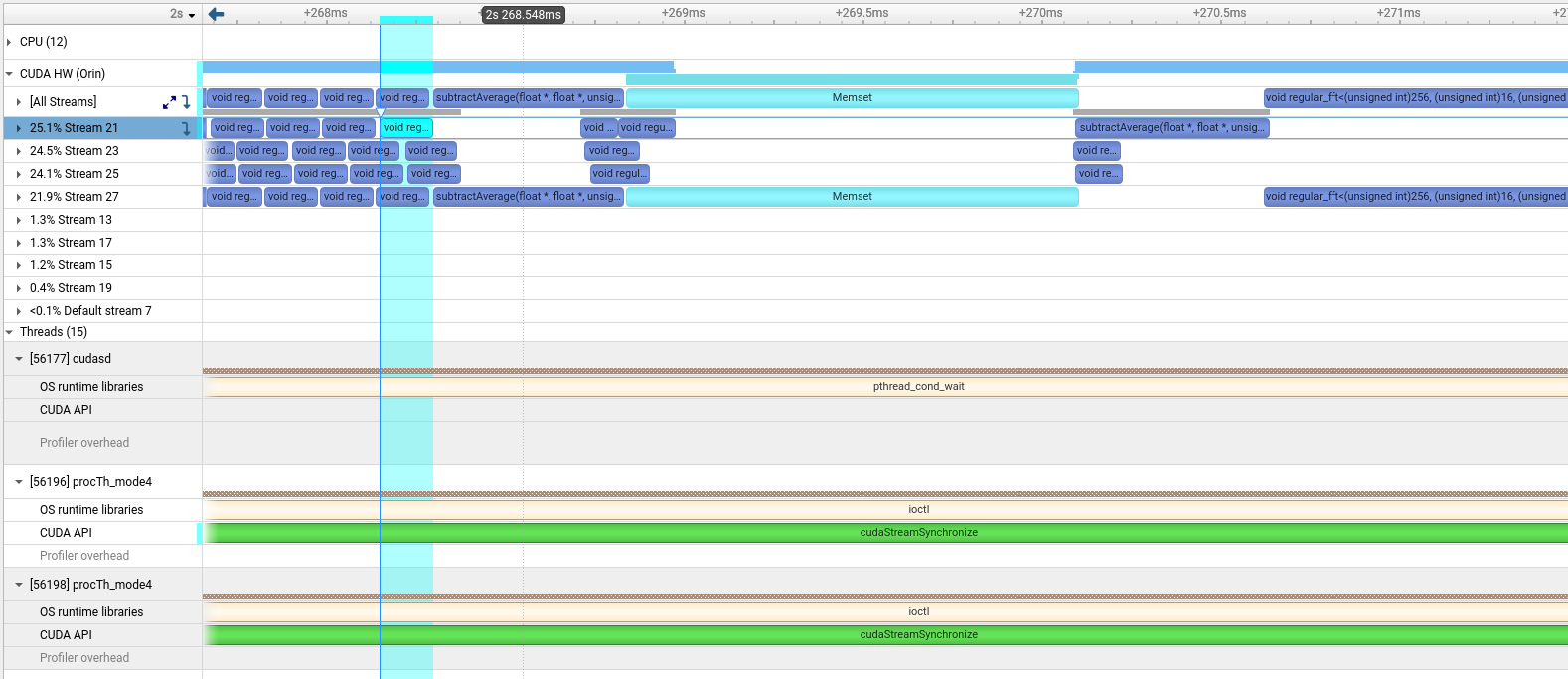
I have a certain CUDA application running on a NVIDIA Jetson Orin. My application splits the input data and processes it in 4 independent streams, but I noticed that sometimes, GPU utilization drops during memset calls:
In this example, why kernels from streams 21,23 and 25 wont start before the memset from 27 ends?(Bonus question, why the interval between the kernels in stream 21,23 and 25, after the highlighted kernel? I would appreciate links to resources to better understand how the GPU scheduling works).
I tried getting a minimal repeating this behavior on a RTX 2080 Ti GPU, and appear to have succeeded with this code:
#include <cuda.h>
#include <cuda_runtime.h>
__global__ void heavyKernel(double* dst, int n, int extra){
double ret = 0;
for (int i = 0; i < n * 32 + extra * n; i++){
ret += (i + 1.0) * (threadIdx.x + 1.0);
}
dst[threadIdx.x + blockIdx.x * blockDim.x] = ret;
}
// Main function
int main() {
int n = 256; // Size of the input
int blocks = 4096 * 32;
int numStreams = 5;
int numRuns = 32;
double *dst[numStreams];
// Create streams
cudaStream_t streams[numStreams];
for (int i = 0; i < numStreams; i++) {
// Allocate memory on the device
cudaMalloc((void**)&dst[i], n * blocks * sizeof(double));
cudaStreamCreate(&streams[i]);
}
// Run the kernel 20 times in each stream
for (int i = 0; i < numStreams; i++) {
for (int j = 0; j < numRuns; j++) {
heavyKernel<<<1, n, n * sizeof(double), streams[i]>>>(dst[i], n, i*32);
cudaMemsetAsync(dst[i], 0, n * blocks * sizeof(double), streams[i]);
}
}
// Synchronize all streams
for (int i = 0; i < numStreams; i++) {
cudaStreamSynchronize(streams[i]);
}
return 0;
}
Looking at the profile:
Why the delay to start the next kernel in Stream 17?
In summary, my questions:
- Why does sometimes memset calls wont overlap with kernel execution?
- How can I avoid this behavior? Would I get better performance if I made my own kernel to perform memset?
- Is there any reason why this would be more prone to happen in Tegra architecture?
- Are there resources to better understand GPU scheduling, and figure out the cause of delays between kernel execution?
I think it is possible that CUDA is already implementing the cudaMemsetAsync as a kernel call. in that case, unlike your heavyKernel launch, it would not necessarily be restricted to a single block, but could be “fully occupying” the GPU. In that case, other kernels would have no space to run until the cudaMemsetAsync finishes. That looks like what is happening to me.
Moving through the timeline:
- all 5 streams get kernels running right away
- when a kernel is the first to finish, it finds much empty space on the GPU, and so its memset kernel begins. This kernel fills all available space on the GPU. Other already running kernels are not interrupted, but no new kernels can start while a memset kernel is running, because it fills the GPU.
- a new
heavyKernel can start only at the point at which a previous memset kernel has just finished
Since the documentation doesn’t indicate how cudaMemsetAsync is implemented, my suggestion is merely speculation. But it seems to fit the data.
Therefore these responses are based on my speculation/claim:
It won’t overlap when the memset happens to be issued with an otherwise-empty GPU. In that case, it fills the GPU, and there is no room for anything else until it completes.
I’m not sure why you would want to avoid this behavior. It may very well be the best workload throughput scenario. Yes, you could write your own memset kernel. If it was well done (e.g. sized to the GPU occupancy, grid-stride loop,etc.) then I would expect essentially no difference in observation. You could force different behavior, eg. by causing your memset kernel to use only a single block. You will observe different behavior. It will be worse behavior.
Nothing really obvious jumps out at me. The number of SMs vs. the number of streams you use will certainly affect the observation. There is a separate forum for Jetson Orin that you can ask on, if you wish.
I think this case could be explained with the basic rules I am familiar with. I’m not sure there is anything exotic here. The GPU scheduling rules, to the extent that there are rules, can be derived from the concurrency section in the programming guide. There is also a unit on concurrency in this online training series.
I see!
The GPU utilization graph at the top threw me off, I always try to keep GPU utilization at 100% to get maximum performance, so that’s why I mentioned avoiding this behaviour, in my mind the GPU was idle while some memory operation occured, but if it is actually being used, there is nothing to be done. I guess I should not trust the GPU utilization graph while a memset is occuring.
Thank you very much for the clarification!