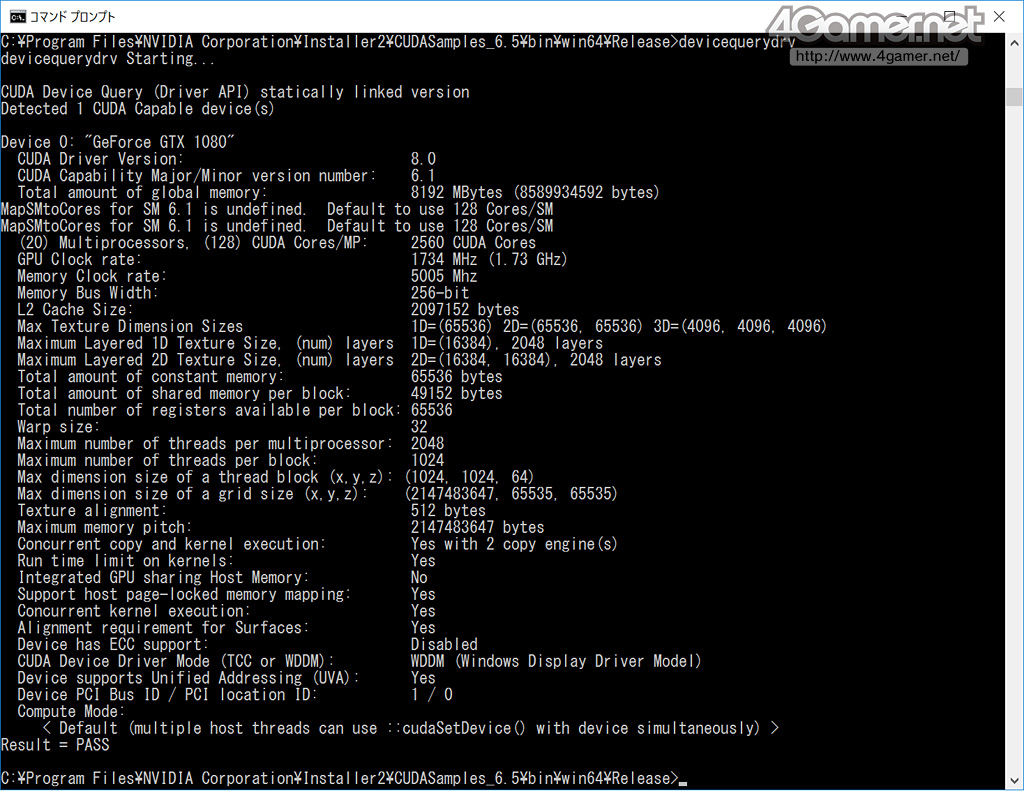
Can Nvidia release a white paper or post the output of ./DeviceQuery on the 1080/1070 when they get a chance?
I’m dying to get more details as to what in the world is going on inside that card as I would like to consider it for cuda development.
It’s a no go until I understand how exactly its different architecturally w.r.t to the cuda execution pipeline.
I’m surprised at how scant the details have been with relation to specs on the card.
Does it at least have dual copy engines like the previous 980?
If not, how can there be a claim of asynchronous compute?
What about runtime limits on kernel execution… etc etc.
What new features are being added to the card?
Are you guys removing any features that were already present on the 980/980ti/titanX ?
Lets get some details for the tech minded portion of your consumer base.
Excellent. Thank you for your reply.
This has calmed me a bit ^_^.
I look forward to getting more juicy details when this NDA is finally lifted.
I’m hoping that Nvidia has people doing more CUDA centric reviews and detailing beyond the gaming centric review channels.
Generally I have found that for CUDA (32-bit) the performance difference between cards for compute generally match those for gaming, so this appears to be very good news. Cant wait to get my hands on a couple of these guys.
It will be interesting to see how code optimized for Maxwell runs on Pascal. In one of my projects I push on the max shared memory limit per SM (a large shared memory scratch pad per thread block) and that code will probably have to be adjusted to reduce the shared memory requirements.
GP104 is Compute Capability 6.1, but the devicequery is from CUDA Toolkit 6.5 so it might not properly support Pascal, might need to wait for CUDA Toolkit 8.0’s devicequery.
Is the run-time limit on kernels found on the 1080 a product of the hardware or windows drivers (WDDM)?
The 980ti and the titanX don’t have run-time limits on kernels (linux) :
However, the 980 has run-time limits on kernels.
Why is this the case? When is cuda 8 supposed to be released?
Net result is: except for GP100, Pascal devices has the same 5.2 architecture inside SM. There are changes outside, such as virtual memory, 2 MB pages and fast thread switching.
It’s possible that GP100 is essentially Volta, or at least half-way to Volta. Overall, it seems that NVidia took the well-known tick-tock approach: Maxwell was a tick (new architecture on old techprocess), and Pascal is a tock. And only GP100 is an exception with its own agenda, as well as testing lab for future architecture updates.
The important detail is that only GP100 need to work with high-speed HBM memory, and it may be the main reason of its halved SM (that still runs 2048 threads simultaneously, so there are 2x more threads per entire GPU). If that idea is correct, we will see 64-alu SMs in all Volta products.