Hello,
I’m trying to deploy ONNX model using TensorRT, but errors occours.
Used command:
./trtexec --onnx=/home/nvidia/trt_conversion/build-yolo-tensorrt/model/tfmodel_lin_19_batchsize.onnx --saveEngine=test.trt --verbose
The model was converted to ONNX from ‘SavedModel’ format on target Device and check with onnx.checker.check_model(model). do not return any error.
I tried conversion with and without set an explicit batch size in the ONNX file.
The attempt was made also with onnx==1.4.1.
The attempts were also made when convert model on host machine with different opset (9, 11, 12).
Link to ONNX model (without set an explicit batch size- the error is the same for both cases) - Sign in to your account
JP Version: 4.6.0
TensorRT Version: 8.0.1.6
Device Type: Jetson Xavier
Nvidia Driver Version:
CUDA Version: 10.2.460-1
Python Version (if applicable): 3.6.9
Tensorflow Version (if applicable):tensorflow==2.6.2+nv21.12
Thanks,
Pawel
Hi,
Could you update your environment into JetPack 4.6.2 which includes TensorRT 8.2.1?
We can successfully run your model with TensorRT 8.2 as follow:
- Update on 14 July -
We can reproduce the same error with TensorRT 8.2 and check the details internally
Please stay tuned
$ /usr/src/tensorrt/bin/trtexec --onnx=tfmodel_lin_19.onnx
&&&& RUNNING TensorRT.trtexec [TensorRT v8201] # /usr/src/tensorrt/bin/trtexec --onnx=tfmodel_lin_19.onnx
[07/13/2022-10:42:42] [I] === Model Options ===
[07/13/2022-10:42:42] [I] Format: ONNX
[07/13/2022-10:42:42] [I] Model: tfmodel_lin_19.onnx
[07/13/2022-10:42:42] [I] Output:
[07/13/2022-10:42:42] [I] === Build Options ===
[07/13/2022-10:42:42] [I] Max batch: explicit batch
[07/13/2022-10:42:42] [I] Workspace: 16 MiB
[07/13/2022-10:42:42] [I] minTiming: 1
[07/13/2022-10:42:42] [I] avgTiming: 8
[07/13/2022-10:42:42] [I] Precision: FP32
[07/13/2022-10:42:42] [I] Calibration:
[07/13/2022-10:42:42] [I] Refit: Disabled
[07/13/2022-10:42:42] [I] Sparsity: Disabled
[07/13/2022-10:42:42] [I] Safe mode: Disabled
[07/13/2022-10:42:42] [I] DirectIO mode: Disabled
[07/13/2022-10:42:42] [I] Restricted mode: Disabled
[07/13/2022-10:42:42] [I] Save engine:
[07/13/2022-10:42:42] [I] Load engine:
[07/13/2022-10:42:42] [I] Profiling verbosity: 0
[07/13/2022-10:42:42] [I] Tactic sources: Using default tactic sources
[07/13/2022-10:42:42] [I] timingCacheMode: local
[07/13/2022-10:42:42] [I] timingCacheFile:
[07/13/2022-10:42:42] [I] Input(s)s format: fp32:CHW
[07/13/2022-10:42:42] [I] Output(s)s format: fp32:CHW
[07/13/2022-10:42:42] [I] Input build shapes: model
[07/13/2022-10:42:42] [I] Input calibration shapes: model
[07/13/2022-10:42:42] [I] === System Options ===
[07/13/2022-10:42:42] [I] Device: 0
[07/13/2022-10:42:42] [I] DLACore:
[07/13/2022-10:42:42] [I] Plugins:
[07/13/2022-10:42:42] [I] === Inference Options ===
[07/13/2022-10:42:42] [I] Batch: Explicit
[07/13/2022-10:42:42] [I] Input inference shapes: model
[07/13/2022-10:42:42] [I] Iterations: 10
[07/13/2022-10:42:42] [I] Duration: 3s (+ 200ms warm up)
[07/13/2022-10:42:42] [I] Sleep time: 0ms
[07/13/2022-10:42:42] [I] Idle time: 0ms
[07/13/2022-10:42:42] [I] Streams: 1
[07/13/2022-10:42:42] [I] ExposeDMA: Disabled
[07/13/2022-10:42:42] [I] Data transfers: Enabled
[07/13/2022-10:42:42] [I] Spin-wait: Disabled
[07/13/2022-10:42:42] [I] Multithreading: Disabled
[07/13/2022-10:42:42] [I] CUDA Graph: Disabled
[07/13/2022-10:42:42] [I] Separate profiling: Disabled
[07/13/2022-10:42:42] [I] Time Deserialize: Disabled
[07/13/2022-10:42:42] [I] Time Refit: Disabled
[07/13/2022-10:42:42] [I] Skip inference: Disabled
[07/13/2022-10:42:42] [I] Inputs:
[07/13/2022-10:42:42] [I] === Reporting Options ===
[07/13/2022-10:42:42] [I] Verbose: Disabled
[07/13/2022-10:42:42] [I] Averages: 10 inferences
[07/13/2022-10:42:42] [I] Percentile: 99
[07/13/2022-10:42:42] [I] Dump refittable layers:Disabled
[07/13/2022-10:42:42] [I] Dump output: Disabled
[07/13/2022-10:42:42] [I] Profile: Disabled
[07/13/2022-10:42:42] [I] Export timing to JSON file:
[07/13/2022-10:42:42] [I] Export output to JSON file:
[07/13/2022-10:42:42] [I] Export profile to JSON file:
[07/13/2022-10:42:42] [I]
[07/13/2022-10:42:42] [I] === Device Information ===
[07/13/2022-10:42:42] [I] Selected Device: Xavier
[07/13/2022-10:42:42] [I] Compute Capability: 7.2
[07/13/2022-10:42:42] [I] SMs: 8
[07/13/2022-10:42:42] [I] Compute Clock Rate: 1.377 GHz
[07/13/2022-10:42:42] [I] Device Global Memory: 31920 MiB
[07/13/2022-10:42:42] [I] Shared Memory per SM: 96 KiB
[07/13/2022-10:42:42] [I] Memory Bus Width: 256 bits (ECC disabled)
[07/13/2022-10:42:42] [I] Memory Clock Rate: 1.377 GHz
[07/13/2022-10:42:42] [I]
[07/13/2022-10:42:42] [I] TensorRT version: 8.2.1
[07/13/2022-10:42:43] [I] [TRT] [MemUsageChange] Init CUDA: CPU +363, GPU +0, now: CPU 381, GPU 7593 (MiB)
[07/13/2022-10:42:43] [I] [TRT] [MemUsageSnapshot] Begin constructing builder kernel library: CPU 381 MiB, GPU 7593 MiB
[07/13/2022-10:42:44] [I] [TRT] [MemUsageSnapshot] End constructing builder kernel library: CPU 486 MiB, GPU 7692 MiB
[07/13/2022-10:42:44] [I] Start parsing network model
[07/13/2022-10:42:44] [I] [TRT] ----------------------------------------------------------------
[07/13/2022-10:42:44] [I] [TRT] Input filename: tfmodel_lin_19.onnx
[07/13/2022-10:42:44] [I] [TRT] ONNX IR version: 0.0.7
[07/13/2022-10:42:44] [I] [TRT] Opset version: 13
[07/13/2022-10:42:44] [I] [TRT] Producer name: tf2onnx
[07/13/2022-10:42:44] [I] [TRT] Producer version: 1.11.1 1915fb
[07/13/2022-10:42:44] [I] [TRT] Domain:
[07/13/2022-10:42:44] [I] [TRT] Model version: 0
[07/13/2022-10:42:44] [I] [TRT] Doc string:
[07/13/2022-10:42:44] [I] [TRT] ----------------------------------------------------------------
[07/13/2022-10:42:44] [W] [TRT] onnx2trt_utils.cpp:366: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
[07/13/2022-10:42:44] [I] Finish parsing network model
[07/13/2022-10:42:44] [W] Dynamic dimensions required for input: input_1, but no shapes were provided. Automatically overriding shape to: 1x1x1x3
[07/13/2022-10:42:45] [I] [TRT] ---------- Layers Running on DLA ----------
[07/13/2022-10:42:45] [I] [TRT] ---------- Layers Running on GPU ----------
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d/Conv2D__50
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_1/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_1/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_2/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_2/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_3/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_3/LeakyRelu), StatefulPartitionedCall/model_1/add/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_4/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_4/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_5/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_5/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_6/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_6/LeakyRelu), StatefulPartitionedCall/model_1/add_1/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_7/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_7/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_8/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_8/LeakyRelu), StatefulPartitionedCall/model_1/add_2/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_9/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_9/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_10/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_10/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_11/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_11/LeakyRelu), StatefulPartitionedCall/model_1/add_3/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_12/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_12/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_13/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_13/LeakyRelu), StatefulPartitionedCall/model_1/add_4/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_14/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_14/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_15/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_15/LeakyRelu), StatefulPartitionedCall/model_1/add_5/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_16/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_16/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_17/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_17/LeakyRelu), StatefulPartitionedCall/model_1/add_6/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_18/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_18/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_19/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_19/LeakyRelu), StatefulPartitionedCall/model_1/add_7/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_20/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_20/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_21/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_21/LeakyRelu), StatefulPartitionedCall/model_1/add_8/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_22/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_22/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_23/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_23/LeakyRelu), StatefulPartitionedCall/model_1/add_9/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_24/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_24/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_25/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_25/LeakyRelu), StatefulPartitionedCall/model_1/add_10/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_26/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_26/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_27/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_27/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_28/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_28/LeakyRelu), StatefulPartitionedCall/model_1/add_11/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_29/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_29/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_30/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_30/LeakyRelu), StatefulPartitionedCall/model_1/add_12/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_31/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_31/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_32/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_32/LeakyRelu), StatefulPartitionedCall/model_1/add_13/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_33/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_33/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_34/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_34/LeakyRelu), StatefulPartitionedCall/model_1/add_14/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_35/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_35/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_36/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_36/LeakyRelu), StatefulPartitionedCall/model_1/add_15/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_37/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_37/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_38/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_38/LeakyRelu), StatefulPartitionedCall/model_1/add_16/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_39/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_39/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_40/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_40/LeakyRelu), StatefulPartitionedCall/model_1/add_17/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_41/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_41/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_42/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_42/LeakyRelu), StatefulPartitionedCall/model_1/add_18/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_43/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_43/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_44/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_44/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_45/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_45/LeakyRelu), StatefulPartitionedCall/model_1/add_19/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_46/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_46/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_47/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_47/LeakyRelu), StatefulPartitionedCall/model_1/add_20/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_48/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_48/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_49/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_49/LeakyRelu), StatefulPartitionedCall/model_1/add_21/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_50/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_50/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_51/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(PWN(StatefulPartitionedCall/model_1/leaky_re_lu_51/LeakyRelu), StatefulPartitionedCall/model_1/add_22/add)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_52/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_52/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_53/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_53/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_54/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_54/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_55/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_55/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_56/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_56/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_59/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_57/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_58/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_57/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_58/BiasAdd
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_58/BiasAdd__981
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] Resize__957
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] Resize__957:0 copy
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_60/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_59/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_61/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_60/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_62/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_61/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_63/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_62/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_64/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_63/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_67/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_65/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_65/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_64/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_66/BiasAdd
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_66/BiasAdd__1124
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] Resize__1100
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] Resize__1100:0 copy
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_68/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_66/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_69/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_67/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_70/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_68/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_71/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_69/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_72/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_70/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_73/Conv2D
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] PWN(StatefulPartitionedCall/model_1/leaky_re_lu_71/LeakyRelu)
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_74/BiasAdd
[07/13/2022-10:42:45] [I] [TRT] [GpuLayer] StatefulPartitionedCall/model_1/conv2d_74/BiasAdd__1228
[07/13/2022-10:42:45] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +227, GPU +0, now: CPU 949, GPU 8165 (MiB)
[07/13/2022-10:42:46] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +307, GPU +302, now: CPU 1256, GPU 8467 (MiB)
[07/13/2022-10:42:46] [I] [TRT] Local timing cache in use. Profiling results in this builder pass will not be stored.
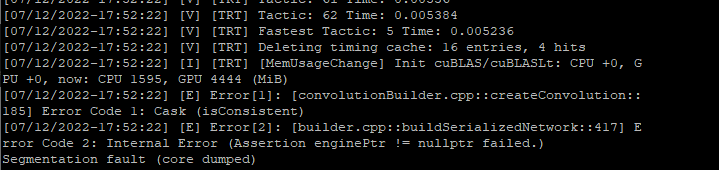
[07/13/2022-10:43:16] [E] Error[1]: [convolutionBuilder.cpp::createConvolution::178] Error Code 1: Cask (isConsistent)
[07/13/2022-10:43:16] [E] Error[2]: [builder.cpp::buildSerializedNetwork::609] Error Code 2: Internal Error (Assertion enginePtr != nullptr failed. )
[07/13/2022-10:43:16] [E] Engine could not be created from network
[07/13/2022-10:43:16] [E] Building engine failed
[07/13/2022-10:43:16] [E] Failed to create engine from model.
[07/13/2022-10:43:16] [E] Engine set up failed
&&&& FAILED TensorRT.trtexec [TensorRT v8201] # /usr/src/tensorrt/bin/trtexec --onnx=tfmodel_lin_19.onnx
Thanks.
Hi AastaLLL,
Thanks for quick reply.
I tried to run it with TensorRT 8.2 and the results are the same as yours (FAILED in the end). The errors are still the same as mentioned in description.
I’m not sure what you mean that you successfully run the model when the status is FAILED?
Thanks.
Hi,
Sorry for the missing.
Please ignore my previous comment.
We are checking this issue internally.
Will share more information with you later.
Hi,
Have you run the model with ONNXRuntime?
We test your model with ONNXRuntime v1.11.0 and a similar error occurs:
test_onnx.py (294 Bytes)
$ python3 test_onnx.py
2022-07-14 14:08:54.276331074 [E:onnxruntime:, sequential_executor.cc:364 Execute] Non-zero status code returned while running Concat node. Name:'StatefulPartitionedCall/model_1/concatenate_1/concat' Status Message: concat.cc:159 PrepareForCompute Non concat axis dimensions must match: Axis 2 has mismatched dimensions of 37 and 36
Traceback (most recent call last):
File "test_onnx.py", line 9, in <module>
output = ort_session.run(None, {"input_1": x})
File "/home/nvidia/.local/lib/python3.6/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 192, in run
return self._sess.run(output_names, input_feed, run_options)
onnxruntime.capi.onnxruntime_pybind11_state.Fail: [ONNXRuntimeError] : 1 : FAIL : Non-zero status code returned while running Concat node. Name:'StatefulPartitionedCall/model_1/concatenate_1/concat' Status Message: concat.cc:159 PrepareForCompute Non concat axis dimensions must match: Axis 2 has mismatched dimensions of 37 and 36
It seems that some issues when converting the TensorFlow model into the ONNX.
If so, would you mind double-checking this with the tf2onnx parser owner?
Thanks.
Solved by adding input shape flag and explicit batch --shapes=input_1:1x416x416x3 --explicitBatch