Hi @vkudlay
You’re right, something wrong with the client code when invoking route /generator.
This time, I checked the sample code from LangServe Github repo and change it to the following method.
from langchain_core.prompts import ChatPromptTemplate
# Invoke generator route --> http://0.0.0.0:9012/generator
RemoteRunnable_generator = RemoteRunnable("http://0.0.0.0:9012/generator/")
RemoteRunnable_generator.invoke({"input": "Tell me something interesting"})
and the corresponding server code is using rag_chain which is taught in this course. The server can generate the response with pprint(rag_chain.invoke("Tell me something interesting!")) but is failed to take client’s request.
chat_prompt = ChatPromptTemplate.from_messages([("system",
"You are a document chatbot. Help the user as they ask questions about documents."
" User messaged just asked you a question: {input}\n\n"
" The following information may be useful for your response: "
" Document Retrieval:\n{context}\n\n"
" (Answer only from retrieval. Only cite sources that are used. Make your response conversational)"
), ('user', '{input}')])
long_reorder = RunnableLambda(LongContextReorder().transform_documents) ## GIVEN
context_getter = itemgetter('input') | docstore.as_retriever() | long_reorder | docs2str
retrieval_chain = {'input' : (lambda x: x)} | RunnableAssign({'context' : context_getter})
generator_chain = RunnableAssign({"output" : chat_prompt | llm_RAG })
generator_chain = generator_chain | output_puller
rag_chain = retrieval_chain | generator_chain
# Self Test
#pprint(rag_chain.invoke("Tell me something interesting!"))
add_routes(
app,
rag_chain,
path="/generator",
)
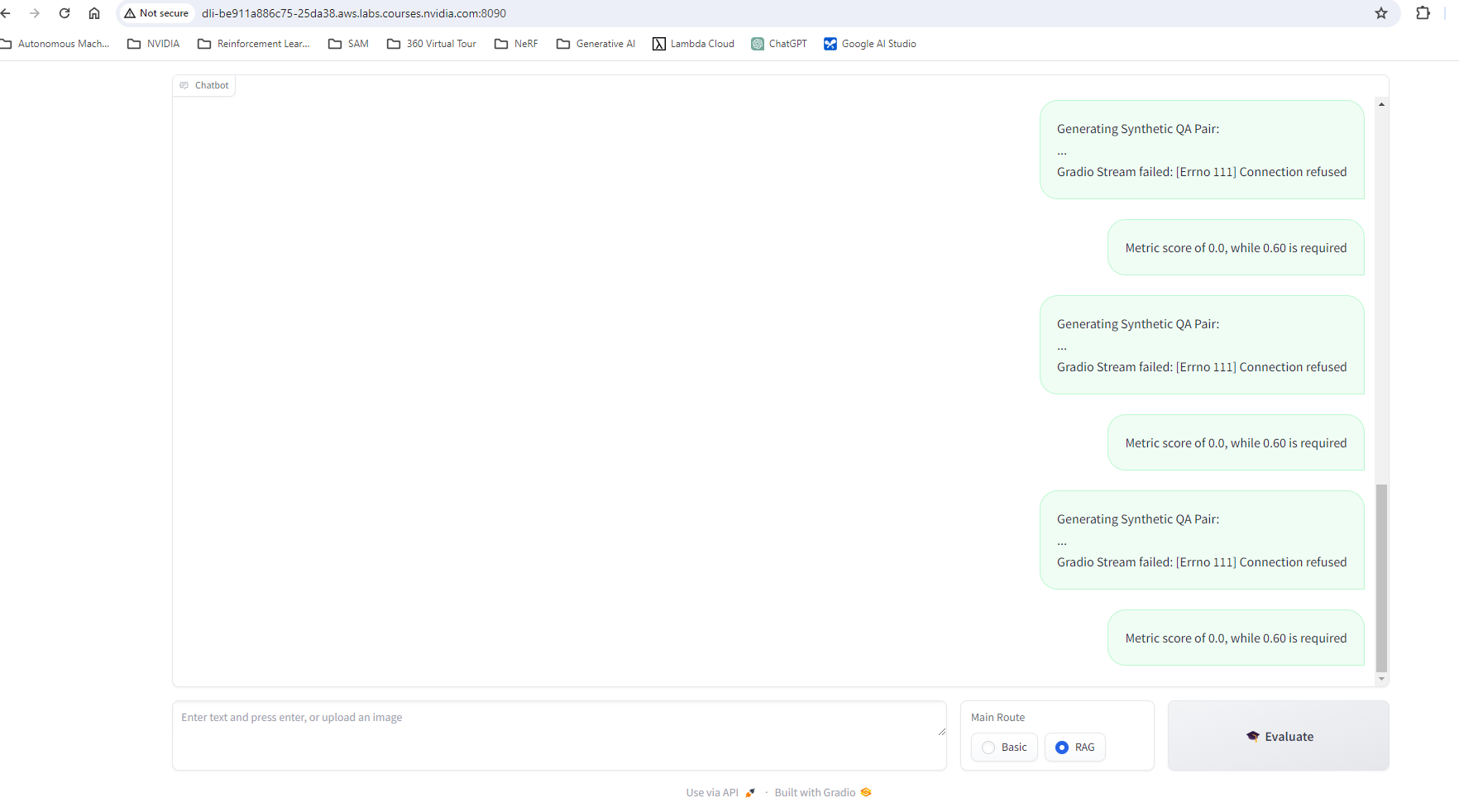
and here is the server log, does this mean the input sent from client is in the wrong format?
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:9012 (Press CTRL+C to quit)
INFO: 127.0.0.1:56106 - "POST /basic_chat/stream HTTP/1.1" 200 OK
INFO: 127.0.0.1:56118 - "POST /retriever/invoke HTTP/1.1" 200 OK
INFO: 127.0.0.1:39558 - "POST /generator/invoke HTTP/1.1" 500 Internal Server Error
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/langchain_nvidia_ai_endpoints/_common.py", line 203, in _try_raise
response.raise_for_status()
File "/usr/local/lib/python3.11/site-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 422 Client Error: Unprocessable Entity for url: https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/091a03bb-7364-4087-8090-bd71e9277520
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/uvicorn/protocols/http/httptools_impl.py", line 426, in run_asgi
result = await app( # type: ignore[func-returns-value]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/uvicorn/middleware/proxy_headers.py", line 84, in __call__
return await self.app(scope, receive, send)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/fastapi/applications.py", line 1054, in __call__
await super().__call__(scope, receive, send)
File "/usr/local/lib/python3.11/site-packages/starlette/applications.py", line 116, in __call__
await self.middleware_stack(scope, receive, send)
File "/usr/local/lib/python3.11/site-packages/starlette/middleware/errors.py", line 186, in __call__
raise exc
File "/usr/local/lib/python3.11/site-packages/starlette/middleware/errors.py", line 164, in __call__
await self.app(scope, receive, _send)
File "/usr/local/lib/python3.11/site-packages/starlette/middleware/exceptions.py", line 62, in __call__
await wrap_app_handling_exceptions(self.app, conn)(scope, receive, send)
File "/usr/local/lib/python3.11/site-packages/starlette/_exception_handler.py", line 55, in wrapped_app
raise exc
File "/usr/local/lib/python3.11/site-packages/starlette/_exception_handler.py", line 44, in wrapped_app
await app(scope, receive, sender)
File "/usr/local/lib/python3.11/site-packages/starlette/routing.py", line 746, in __call__
await route.handle(scope, receive, send)
File "/usr/local/lib/python3.11/site-packages/starlette/routing.py", line 288, in handle
await self.app(scope, receive, send)
File "/usr/local/lib/python3.11/site-packages/starlette/routing.py", line 75, in app
await wrap_app_handling_exceptions(app, request)(scope, receive, send)
File "/usr/local/lib/python3.11/site-packages/starlette/_exception_handler.py", line 55, in wrapped_app
raise exc
File "/usr/local/lib/python3.11/site-packages/starlette/_exception_handler.py", line 44, in wrapped_app
await app(scope, receive, sender)
File "/usr/local/lib/python3.11/site-packages/starlette/routing.py", line 70, in app
response = await func(request)
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/fastapi/routing.py", line 299, in app
raise e
File "/usr/local/lib/python3.11/site-packages/fastapi/routing.py", line 294, in app
raw_response = await run_endpoint_function(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/fastapi/routing.py", line 191, in run_endpoint_function
return await dependant.call(**values)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langserve/server.py", line 442, in invoke
return await api_handler.invoke(request)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langserve/api_handler.py", line 672, in invoke
output = await self._runnable.ainvoke(input_, config=config)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/runnables/base.py", line 2087, in ainvoke
input = await step.ainvoke(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/runnables/passthrough.py", line 443, in ainvoke
return await self._acall_with_config(self._ainvoke, input, config, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/runnables/base.py", line 1295, in _acall_with_config
output: Output = await asyncio.create_task(coro, context=context) # type: ignore
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/runnables/passthrough.py", line 430, in _ainvoke
**await self.mapper.ainvoke(
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/runnables/base.py", line 2645, in ainvoke
results = await asyncio.gather(
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/runnables/base.py", line 2087, in ainvoke
input = await step.ainvoke(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/retrievers.py", line 136, in ainvoke
return await self.aget_relevant_documents(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/retrievers.py", line 281, in aget_relevant_documents
raise e
File "/usr/local/lib/python3.11/site-packages/langchain_core/retrievers.py", line 274, in aget_relevant_documents
result = await self._aget_relevant_documents(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/vectorstores.py", line 674, in _aget_relevant_documents
docs = await self.vectorstore.asimilarity_search(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_community/vectorstores/faiss.py", line 536, in asimilarity_search
docs_and_scores = await self.asimilarity_search_with_score(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_community/vectorstores/faiss.py", line 423, in asimilarity_search_with_score
embedding = await self._aembed_query(query)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_community/vectorstores/faiss.py", line 161, in _aembed_query
return await self.embedding_function.aembed_query(text)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/embeddings.py", line 24, in aembed_query
return await run_in_executor(None, self.embed_query, text)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_core/runnables/config.py", line 493, in run_in_executor
return await asyncio.get_running_loop().run_in_executor(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/concurrent/futures/thread.py", line 58, in run
result = self.fn(*self.args, **self.kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_nvidia_ai_endpoints/embeddings.py", line 56, in embed_query
return self._embed([text], model_type=self.model_type or "query")[0]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_nvidia_ai_endpoints/embeddings.py", line 38, in _embed
response = self.client.get_req(
^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_nvidia_ai_endpoints/_common.py", line 288, in get_req
response, session = self._post(invoke_url, payload)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain_nvidia_ai_endpoints/_common.py", line 165, in _post
self._try_raise(response)
File "/usr/local/lib/python3.11/site-packages/langchain_nvidia_ai_endpoints/_common.py", line 218, in _try_raise
raise Exception(f"{title}\n{body}") from e
Exception: [422] Unprocessable Entity
body -> input -> str
Input should be a valid string (type=string_type)
body -> input -> list[str] -> 0
Input should be a valid string (type=string_type)