When I run your program it hangs when “nowait” is there. Not sure the discrepancy, but possibly since a target region is itself a task, there may be a problem when trying to join. Though, I didn’t look into this since that not the core issue.
“nowait” just launches the kernel asynchronously with the host. It does not specify use of different CUDA streams so all kernels will use the same stream. While we don’t support the ‘depends’, we’re looking at how this could be adapted to use multiple streams. Though unlike OpenACC which uses async queues, ‘depends’ creates dependencies on the data making it more challenging for the compiler to implicitly generate CUDA streams.
Though I find it very rare for a program to benefit from running multiple concurrent kernels. It more beneficial at overlapping data movement and compute, or hiding launch latency. Only for kernels with few blocks, would you possibly see benefit and I would rather see if I can modify the code or use a bigger dataset so the full GPU was utilized with each kernel.
Note when I ran your program, the grid size is 36,480. Far larger that the 108 and 1024 you posted above. So not much opportunity to overlap.
I’m not really understanding why you’re using TASK here since it doesn’t seem like it would help. I’d simplify to something like the following.
% cat add2s2_omp.f
module foo
contains
subroutine add2s2_omp_async(a,b,c1,n)
real a(n),b(n)
real,value:: c1
integer,value:: n
!$OMP TARGET TEAMS DISTRIBUTE PARALLEL DO MAP(tofrom:a,b) nowait
do i=1,n
a(i)=a(i)+c1*b(i)
enddo
return
end
end module foo
program add2s2_omp
use foo
implicit none
integer k, m, n
real, dimension(:), allocatable :: xbar, bbar, b
real, dimension(:,:), allocatable :: xx, bb
real alpha_k
m = 3
n = 4669440
allocate(xbar(n))
allocate(bbar(n))
allocate(b(n))
allocate(xx(n,m))
allocate(bb(n,m))
xbar = 1.1
bbar = 2.2
b = 3.3
alpha_k = 0.4
xx = 3.5
bb = 2.1
!$OMP TARGET DATA MAP(TOFROM:xbar,bbar,b) MAP(TO:xx,bb)
do k = 2,m
call add2s2_omp_async(xbar,xx(:,k),alpha_k,n)
call add2s2_omp_async(bbar,bb(:,k),alpha_k,n)
call add2s2_omp_async(b,bb(:,k),-alpha_k,n)
enddo
!$OMP TASKWAIT
!$OMP END TARGET DATA
print *, xbar(1),bbar(1),b(1)
deallocate(xbar)
deallocate(bbar)
deallocate(b)
deallocate(xx)
deallocate(bb)
end program
% nvfortran add2s2_omp.f -Minfo=mp -mp=gpu -V21.7 ; a.out
add2s2_omp_async:
8, !$omp target teams distribute parallel do
8, Generating Tesla and Multicore code
Generating "nvkernel_foo_add2s2_omp_async__F1L8_1" GPU kernel
add2s2_omp:
40, Generating map(tofrom:bbar(:))
Generating map(to:bb(:,:))
Generating map(tofrom:xbar(:))
Generating map(to:xx(:,:))
Generating map(tofrom:b(:))
46, Taskwait
3.900000 3.880000 1.620000
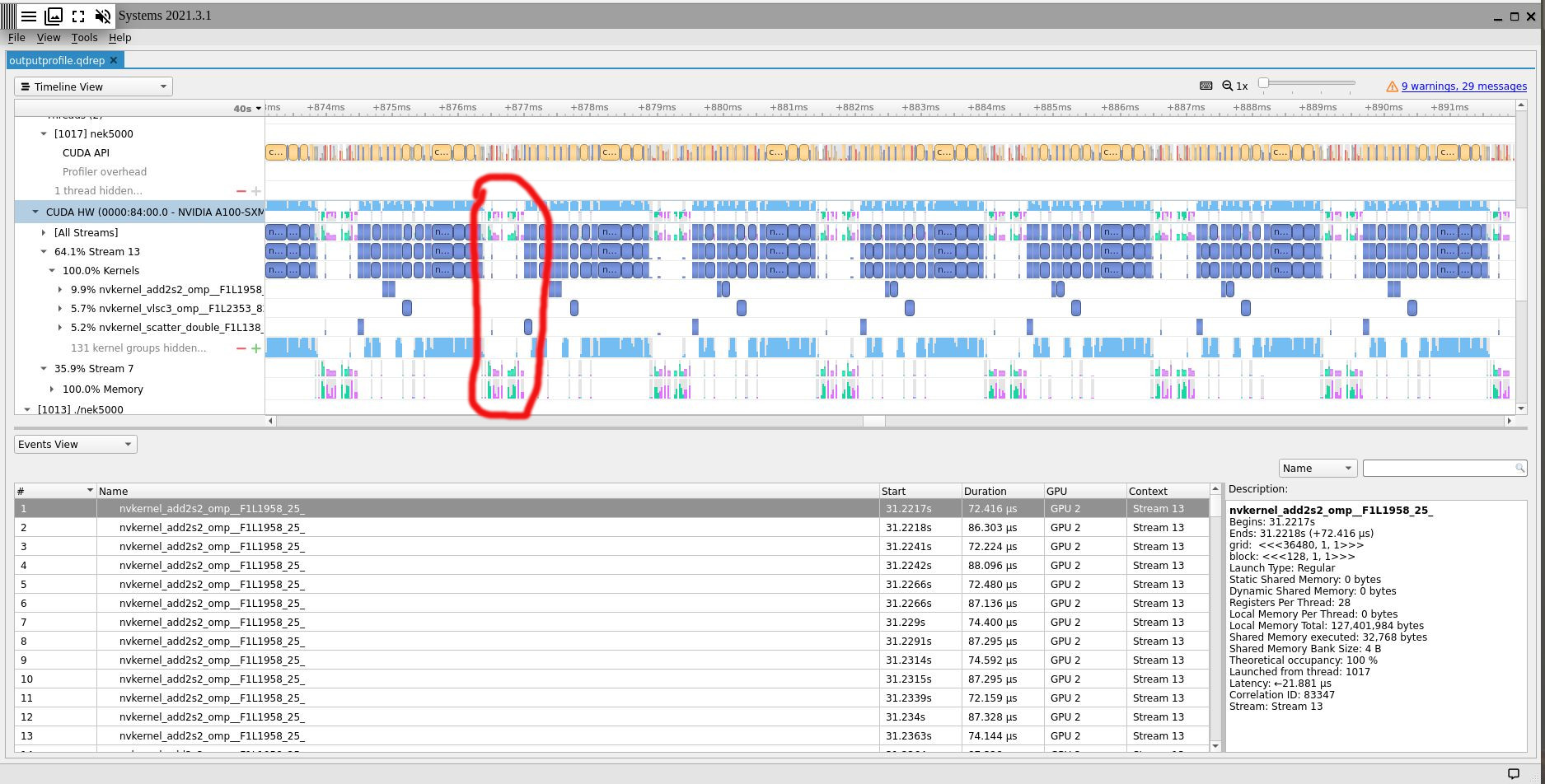
Once we support depends, we can go back and see about using multiple streams. However again, I doubt it will make much impact. To illustrate, here’s the equivalent OpenACC version of this code using multiple async queues. If you run this through Nsight, you’ll see a slight bit of overlap with the kernels, but not enough to offset the cost of creating the streams.
% cat add2s2_acc.f
subroutine add2s2_acc_async(a,b,c1,n,qid)
real a(n),b(n)
real:: c1
integer:: n,qid
!$ACC PARALLEL LOOP present(a,b) async(qid)
do i=1,n
a(i)=a(i)+c1*b(i)
enddo
return
end
program add2s2_omp
implicit none
integer k, m, n
real, dimension(:), allocatable :: xbar, bbar, b
real, dimension(:,:), allocatable :: xx, bb
real alpha_k
m = 3
n = 4669440
allocate(xbar(n))
allocate(bbar(n))
allocate(b(n))
allocate(xx(n,m))
allocate(bb(n,m))
xbar = 1.1
bbar = 2.2
b = 3.3
alpha_k = 0.4
xx = 3.5
bb = 2.1
!$ACC DATA copy(xbar,bbar,b) copyin(xx,bb)
do k = 2,m
call add2s2_acc_async(xbar,xx(1,k),alpha_k,n,1)
call add2s2_acc_async(bbar,bb(1,k),alpha_k,n,2)
call add2s2_acc_async(b,bb(1,k),-alpha_k,n,3)
enddo
!$ACC WAIT
!$acc END DATA
print *, xbar(1),bbar(1),b(1)
deallocate(xbar)
deallocate(bbar)
deallocate(b)
deallocate(xx)
deallocate(bb)
end program
% nvfortran add2s2_acc.f -Minfo=accel -acc -V21.7 ; a.out
add2s2_acc_async:
6, Generating present(a(:),b(:))
Generating Tesla code
7, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
add2s2_omp:
36, Generating copy(bbar(:)) [if not already present]
Generating copyin(bb(:,:),xx(:,:)) [if not already present]
Generating copy(xbar(:),b(:)) [if not already present]
3.900000 3.880000 1.620000


{kind=link}