Not necessarly a CUDA specific issue, but maybe I can find a better way of achieving this using the CUDA math API.
Doing this already using a loop starting at the least significant bit in a bitmask, and keep track of all the unset bits already seen until I get to the nth unset bit then break.
Googled all the typical bit hacks, and did not find a solution this particular problem.
For example assume the bitmask with the following state:
…1001101101
going from right to left (least significant to most) with n=2, the answer would be index 7 in the bitmask.
This method uses 0 based indexing so that the first unset bit would correspond to n=0, which in the above example bitmask would be index 1.
The use of signed/unsigned of the bitmask does not really matter in my case since I will at most be examining the 20 bit locations from right to left.
The CUDA math API integer intrinsics has this:
__device__ int __ffs ( int x )
Find the position of the least significant bit set to 1 in a 32 bit integer.
and maybe there is a clever way to use this(by flipping bits of the mask and looking for unset bits from a certain start point) and avoid the loop method which I am currently using to get the index of the nth unset bit from right to left.
Been testing different loop based approaches and on the CPU (Visual Studio complier) this one is faster, but need to see if I see the same difference in a device kernel:
int get_nth_unset(const int bit_mask,int n){//will assume n is always>=0
if(bit_mask==0)return n;
int ans;
int temp_mask=bit_mask;
for(ans=-1;n>=0;temp_mask>>=1,ans++){
n-=int(!(temp_mask&1));
}
return ans;
}
There may still be some bugs but I did some basic testing and it seems to be valid for my purposes, but I still think there is a better solution.
Switching to the above method in my CUDA kernels resulted in a a 31% speedup.
That on top of some other optimizations had allowed me to break the 4 second barrier for generating all permutations of a 13 element array (6227020800 different arrangements in memory) using CUDA on a GTX 980.
Still would be interested in a non-loop method of the same, if anybody has ideas.
I cannot think of a fast non-iterative solution right now, but the following iterative code may be a tad faster than your current solution. I omitted the special case handling for a mask of all zeroes, is that expected to be a common case?
int find_nth_clear_bit (unsigned int a, int n)
{
int i;
a = ~a; // search for 1-bit instead of 0-bit
for (i = 0; i < n; i++) {
a = a & (a-1); // clear least significant 1-bit
}
return __ffs (a) - 1;
}
The following should be equivalent:
int find_nth_clear_bit (unsigned int a, int n)
{
int i;
for (i = 0; i < n; i++) {
a = a | (a+1); // set least significant 0-bit
}
return __ffs (~a) - 1;
}
Does it need to be done in a single thread, or can you use a warp to help you out?
A possible parallel approach:
Each thread does a bitwise-or of the value with a bitmask equal to the lowest bits unset up to the warp lane ID, and other bits set.
The lowest order thread with the desired n value is the bit position.
Here’s a proof of concept code:
#include <stdio.h>
#define TEST_VAL 0b01001101101
#define BIT_SEL 2
__global__ void kernel(unsigned bit_mask, unsigned n){
__shared__ unsigned my_zeroes[32];
bool im_it = false;
unsigned my_lane_id = threadIdx.x;
unsigned my_lane_mask = 0xFFFFFFFEU << my_lane_id;
unsigned my_mask_val = my_lane_mask | bit_mask;
my_zeroes[my_lane_id] = 32 - __popc(my_mask_val);
__syncthreads();
if (my_zeroes[my_lane_id] == n+1){
if (my_lane_id > 0) {
if (my_zeroes[my_lane_id - 1] != n+1) im_it = true;
}
else im_it = true;
}
if (im_it) printf("the unset bit with index %d is in position %d\n", n, my_lane_id);
}
int main(){
kernel<<<1,32>>>(TEST_VAL, BIT_SEL);
cudaDeviceSynchronize();
return 0;
}
The usage of shared memory (and the __syncthreads() ) could be eliminated on a cc3.0+ device with a __shfl_up() operation. Probably it could be improved in other ways as well. It’s far from fully tested and only works for a single warp.
Since that function is called trillions of times in the course of a larger kernel run, even a slight speedup will make a large difference.
As far as the zero case for the mask, that should will not be a common case, because I know when the mask starts off as zero and handle that situation separately.
That is neat, as I would not have thought to approach it that way.
May not be useful in my particular case, but I can think of other situations where such an approach would be useful.
It is a good exercise in my advanced use of __shfl().Thanks.
For your CPU version, if your processor supports AVX2 (I think this means Haswell and later), consider using the PDEP instruction, which is available via the intrinsic _pdep_u32(src, mask) with the Visual Studio 2013 compiler (http://msdn.microsoft.com/en-us/library/hh977023.aspx).
The PDEP instruction will deposit the n-th bit of the source at the n-th 1-bit of the mask. So your desired functionality should be realizable as (untested, as I do not have a CPU with AVX2 support):
int find_nth_clear_bit (unsigned int a, int n)
{
unsigned long r;
_BitScanForward (&r, (unsigned long)(_pdep_u32 (1U << n, ~a)));
return (int)r;
}
I have not had sufficient time yet to ponder whether a fast emulation of the deposit/scatter functionality is possible. [Later:] As a quick sanity check I consulted Hank Warren’s “Hacker’s Delight 2nd ed.” and in section 7-5 “Expand, or Generalized Insert” he presents a 32-bit emulation amenable to a non-branching implementation that would compile to about 150 instructions or so on a GPU. So this does not look like a fruitful approach for a CUDA implementation.
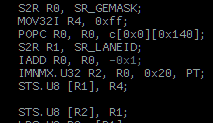
You can easily transform the ‘nth unset bit from lsb’ problem with BREV and NOT ops into the more PTX friendly ‘nth set bit’ and, depending on the compute architecture, identify the bit indices starting from either the lsb or msb.
You can then obtain all of the bit indices at once and in order by exploiting a neat low-level CUDA hack feature.
The solution only requires a tiny number of SASS instructions:
Explanation:
When there are shared memory write conflicts within a warp the "high lane wins" on Fermi and Kepler.
Cursory experimentation indicates that Maxwell reverses this behavior and the low lane wins.
Relying on this feature, write the current lane id to the shared mem index: "popc(bits) & %lanemask_ge"
Only the highest lane will successfully write to shared.*
Fermi and Kepler. Maxwell is reversed so use %lanemask_le. See code.
allanmac, that is one heck of a cool hack, but I would be worried about the robustness of the code since it relies on unspecified hardware artifacts. While any hardware implementation would likely fall into either the “low lane wins” or “high lane wins” categories there can be no guarantee that such a priority encoder based solution will be used across all GPUs. One would also have to determine individually for each new architecture into which of these two classes it falls, so the code is not future-proof.
A basic approach to a branch-less find_nth_set_bit() would be to start with the classic population count algorithm, which in consecutive steps determines the count of set bits in 1-bit, 2-bit, 4-bit, 8-bit, and 16-bit groups. Once we have these counts, we can perform a binary search on the generated count data to find the nth set bit from the least significant end. For example, if is n is greater or equal to the count for the lower 16-bit group, then the n-th set bit must be in the upper 16 bits.
int find_nth_clear_bit (unsigned int a, int n)
{
int t, i = n, r = 0;
unsigned int c1 = ~a; // search for 1-bits instead of 0-bits
unsigned int c2 = c1 - ((c1 >> 1) & 0x55555555);
unsigned int c4 = ((c2 >> 2) & 0x33333333) + (c2 & 0x33333333);
unsigned int c8 = ((c4 >> 4) + c4) & 0x0f0f0f0f;
unsigned int c16 = ((c8 >> 8) + c8);
int c32 = ((c16 >> 16) + c16) & 0x3f;
t = (c16 ) & 0x1f; if (i >= t) { r += 16; i -= t; }
t = (c8 >> r) & 0x0f; if (i >= t) { r += 8; i -= t; }
t = (c4 >> r) & 0x07; if (i >= t) { r += 4; i -= t; }
t = (c2 >> r) & 0x03; if (i >= t) { r += 2; i -= t; }
t = (c1 >> r) & 0x01; if (i >= t) { r += 1; }
if (n >= c32) r = -1;
return r;
}
I have serious doubts that the branch-less version provides an actual performance advantage for CudaaduC’s use case, unless ‘n’ is normally quite large. For small ‘n’ my earlier version with the simple iteration should win. It would be very interesting to hear from CudaaduC which version worked best for his application.
Starting GPU testing:
num_blx= 23754, adj_size= 1
Testing full version.
GPU timing: 2.768 seconds.
GPU answer is: 1610
The evaluation had ( n!*(4+2*n+n^2)) steps, which is apx. 1239177139200 iterations.
Here is a permutation associated with the best result. If there is a bracket followed by a 0 that means the dependencies which were necessary to include that value were not met.
[3]= 277,[1]= 438,[7]= 5,[9]= 127,[5]= 129,[2]= 19,[0]= 33,[4]= 449,[6]= 40,[8]= 22,[10]= 61,[11]= 7,[12]= 3,
GPU total=1610
That 2.768 second result is for both the generation of all 13! arrangements of the array, the evaluation against the test function for each arrangement, reduction and scan of the optimal value and the a permutation associated with that optimal value.
After two kernel calls the results are copied back to the host and that corresponding output is derived from the 64 bit permutation number.
That is the full running time in Windows 7 using a single GTX 980. I had made some other optimizations as well, but this one really paid off because of the frequency of that call.
Using my previous loop method the time was about 4.7 seconds for the same problem with the same answer. I used the first of your two loop based approaches.
I am going to test up to 17! next, and try splitting amongst 2 GTX 980s.
Truly unbelievable!! Thanks so much for your input njuffa!!
I am glad I could be of some help. I assume the speedup you are reporting is with the simple loop-based version? It is hard to predict how much speedup can be achieved when one has close to zero knowledge of the code context, so I figured it would be best to supply a conservative estimate.
I know you have been working on this permutation generation issue for a while, since you are a regular poster here. Could you refresh my memory regarding the bigger context, please? Is this part of a larger bioinformatics application? I am always interested to learn what interesting and exiting problems people are tackling with GPUs in general and CUDA in particular.
While my current job involves CUDA programming, this is a side project. Always been interested in brute force problems, and wanted to create a GPU version of the C++ STL next_permutation() function.
The STL next_permutation() implementation does not use factorial decomposition, as I do in the CUDA version.
While I am not directly using this code in any work related projects as of yet, I have used some other CUDA implementations of brute force algorithms in work projects. Have used a CUDA implementation of the ‘Traveling Salesman Problem’ (which is O(n^2*2^n) rather than O(n!)). In general I think there are still lots of interesting work to be done with CUDA in the area of hybrid CPU/GPU dynamic programming (DAG) problems.
Actually these type of problems do come up quite a bit, but most people just assume that once you get beyond a certain n threshold the problem is not possible to complete in a reasonable time. Usually there are right, but often n can a bit larger than they thought.
That same evaluation code on a laptop GTX 980m takes about 4.5 seconds vs 2.7 seconds on the GTX 980 desktop. Less cores and worse 64 bit performance added up…
I am not sure I understand the comment about 64-bit performance. In the discussion in this thread so far the concern was about 32-bit integer operations. The GTX 980 and GTX 980M are the same architecture (GM 204), so performance differences should boil down to core counts and clock frequencies. I would expect the mobile part to come in around 2/3 of the performance the desktop part (using NVIDIA stock clocks without clock boosting).