Hi,all.
Now I take an experiment about share memory bank conflict.I launched four kernels,each for 100 times,the kernel code is as follows:
[codebox]
////////////////////////////////////////////////////
//* kernel 1: each thread deal with one 4-bytes word
//* without bank-conflict
///////////////////////////////////////////////////
global void
BankFlict_Test_kernel_1(unsigned int *d_out,unsigned int *d_in)
{
const unsigned int tid = threadIdx.x;
const unsigned int bid = blockIdx.x;
const unsigned int baseIndex = bid * blockDim.x;
__shared__ unsigned int share[16];
share[tid] = d_in[baseIndex + tid];
share[tid] += 2;
d_out[baseIndex + tid] = share[tid];
}
///////////////////////////////////////////////////
//* kernel 2: each thread deal with one 1-bytes char
//* causes 4-way bank-conflicts
//////////////////////////////////////////////////
global void
BankFlict_Test_kernel_2(char *d_out, char *d_in)
{
const unsigned int tid = threadIdx.x;
const unsigned int bid = blockIdx.x;
const unsigned int baseIndex = bid * blockDim.x;
__shared__ char share[16];
share[tid] = d_in[baseIndex + tid];
share[tid] += 2;
d_out[baseIndex + tid] = share[tid];
}
//////////////////////////////////////////////////
//* kernel 3: every thread in one block access the
//* the same address,ie. broadcast without
//* bank-conflict
//////////////////////////////////////////////////
global void
BankFlict_Test_kernel_3(unsigned int *d_out,unsigned int *d_in)
{
const unsigned int tid = threadIdx.x;
const unsigned int bid = blockIdx.x;
const unsigned int baseIndex = bid*blockDim.x;
__shared__ unsigned int share[16];
share[tid] = d_in[bid];
d_out[baseIndex + tid] = share[0]+2;
}
//////////////////////////////////////////////////
//* kernel 4: every thread in one block access the
//* same address,but access many times
//* and the address is different
//////////////////////////////////////////////////
global void
BankFlict_Test_kernel_4(unsigned int *d_out,unsigned int *d_in)
{
const unsigned int tid = threadIdx.x;
const unsigned int bid = blockIdx.x;
const unsigned int baseIndex = bid*blockDim.x;
__shared__ unsigned int share[16];
share[tid] = d_in[baseIndex + tid];
for(int i = 0;i < blockDim.x; i++)
{
d_out[baseIndex + tid] = share[i]+2;
__syncthreads();
}
}
[/codebox]
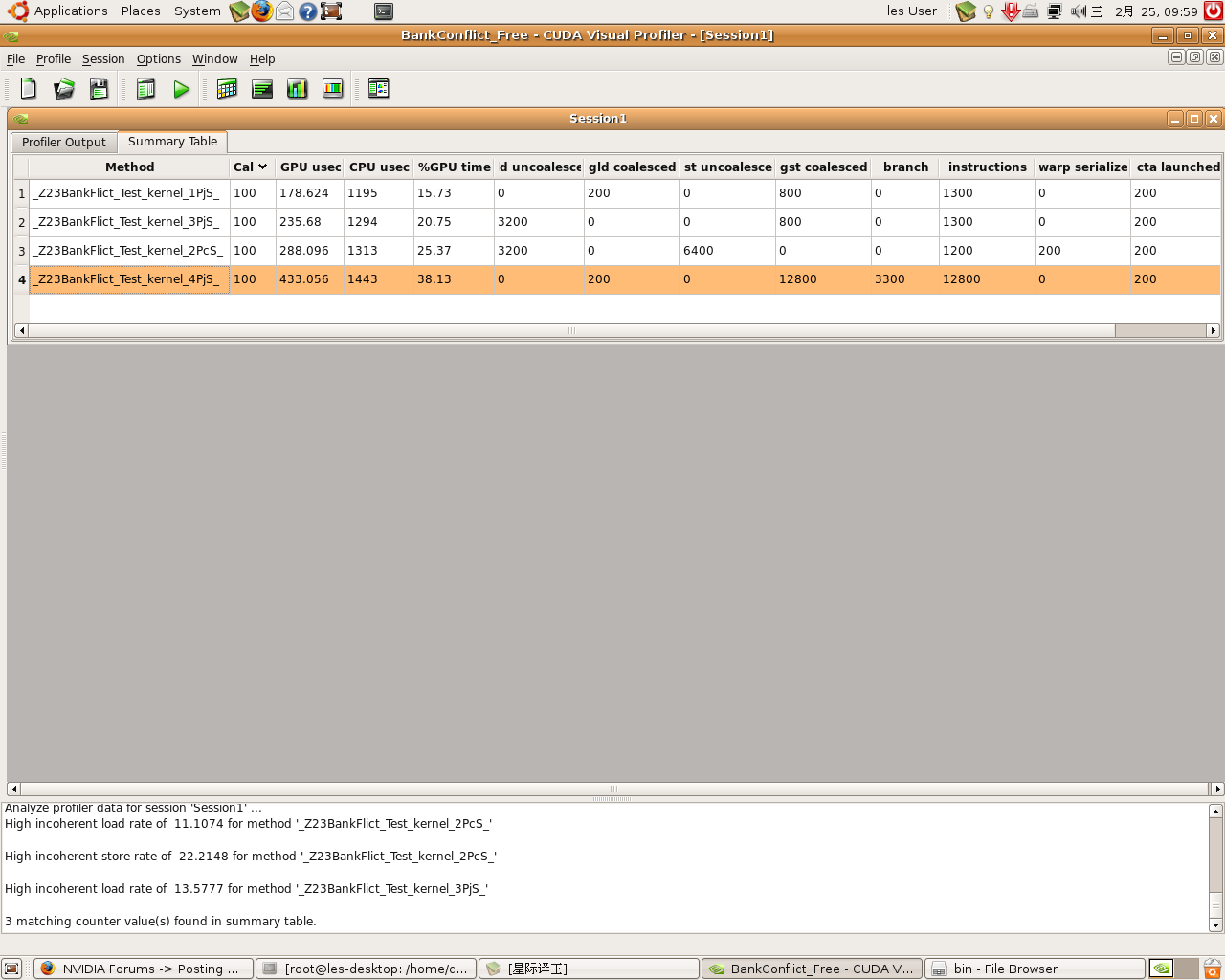
The comment line shows what i think the kernel should be.The kernel was launched with <blockNUM,threadsForEachBlock>is<16,16>
But the result is very almost the same.
Kernel 1: processing time is: 0.409000
Kernel 2: processing time is: 0.493000
Kernel 3: processing time is: 0.476000
Kernel 4: processing time is: 0.615000
why does this happen?Normally,The kernel 1 should be ~4x faster than kernel 2. Am i right?What about the kernel 4?It’s bank conflict-free?
I also run the kernel on the Visual Profiler, attched is the result.Any guys can make an explanation?THX.