I have a question regarding the accuracy of the CUBLAS single-precision multiplication, when we are working with large matrices. I’ve tried to compare the results generated by Sgemm and Dgemm in Cublas (v 2.3), with the CPU results obtained from MATLAB. (The error metric used is the sum of absolute difference of the two matrices).
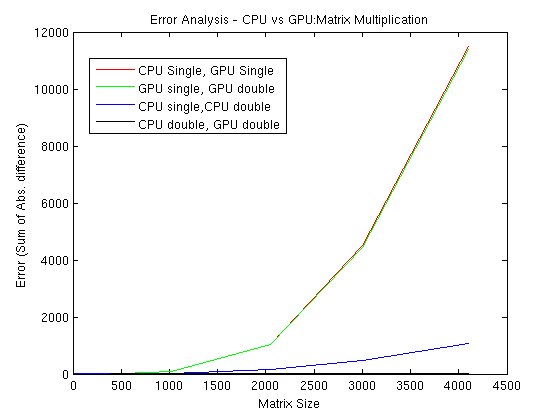
I find that the error between the GPU-single and GPU-double versions seems to be increasing at a much faster rate compared to the corresponding CPU versions(please see attached file: precision_results.png). For example, in the case of random 3000x3000 matrices, the error values are the following:
err(CPU-single, CPU-double) = 456.64
err(GPU-single, GPU-double) = 4443.8 // an order of magnitude higher than CPU-difference
err(GPU-single, CPU-single) = 4486.3
err(GPU-double,CPU-double) = 8.36e-6.
The fact that both cases having large errors involve GPU-single seems to point to a loss of accuracy in this version for matrices of this size. Also, in the single precision case, some results are off (relative to the cpu) by the third decimal at this matrix size. (the magnitude of the numbers is about a few hundred).
I tried out the same experiment with the all matrix elements initialized to 1, and the errors came out to be a perfect 0. Is this a case of the single-precision algorithm accumulating error when all bits of a floating point number are used up (which is more likely when matrices are randomly initialized)? Could you please let us know your opinion on this?
Thanks and Regards,
Sandeep.
p.s. Please find the code used to generate these results attached. The *.cu files are mex-wrappers around cublas calls, and the file trial.txt is the matlab script that runs it across various matrix sizes (Please rename this to trial.m to run it in MATLAB) trial.txt (1.17 KB) dgemm.cu (1.93 KB) sgemm.cu (1.92 KB)
Since your multiplication has N=M=K, you are doing approximately N^3 add and N^3 multiply operations; many of which will be merged into a single FMAD instruction. Now, the CUDA Programmer’s Guide has a nice section about deviations from the IEEE-754 float point standard. Specially regarding FMAD: “Addition and multiplication are often combined into a single multiply-add instruction (FMAD), which truncates the intermediate result of the multiplication.”
So you have an exponentially increasing count of operations that are well-known to deviate from the expected CPU results. This matches up nicely with your graph as you can see the deviation is increasing exponentially :)
A few suggestions to “solve” your problem:
Keep K constant while M=N is varied. I’d suggest testing at reasonable intervals like 16, 32, 64, 128, …, 1024, etc.
Reevaluate your testing metric. I don’t think that a simple sum of absolute error is enough to draw any conclusions. I’d imagine there are some good computer science text books and papers that go into great detail about expected floating point errors and what is considered an “acceptable answer”.
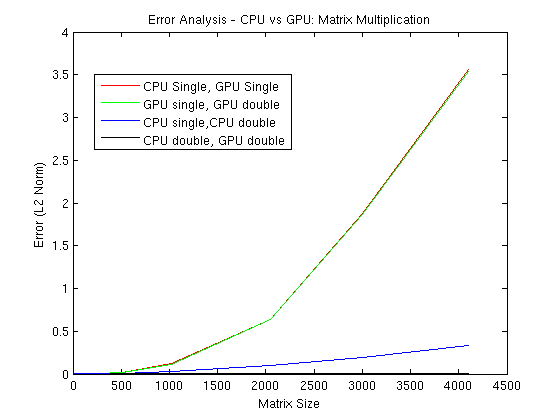
Yes, I did mean the sum of absolute difference of all elements. I’ve actually tried out other norms as error metrics - specifically mean-squared error (L2) and max of absolute difference (L-inf) - (results attached) The error pattern seemed to be very similar.
@ Kyle
That seems to explain the error to some extent at least. Is there any data available on what magnitudes of deviation from IEEE-754 this can cause?
Could you please elaborate on what you meant by “solve”? We do see that the error has a flat profile (the max. abs. error metric) and that can be attributed to the fact that there are constant number of multiplications and additions for every column, but this is still an order of magnitude higher compared to the CPU version.
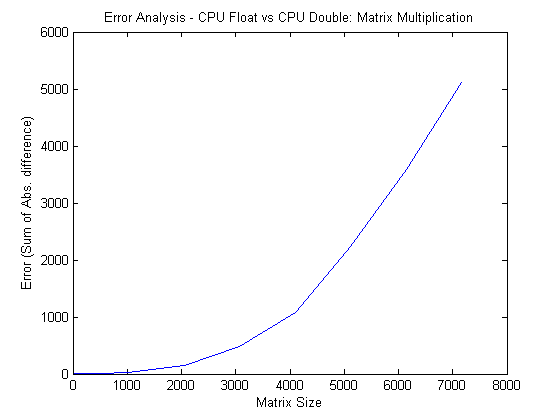
I just tested your code only looking at CPU single versus CPU double. The CPU “error” is increasing exponentially, as well. You just didn’t have enough data points to see the trend.
Agreed. But I am still concerned about the difference in errors seen between the CPU and GPU single-precision versions. The GPU-single error seems to be deviating from the CPU-single by an order of magnitude.
I am having a hard time understanding why you think there is a problem at all.
In your original data, a sum of absolute differences of 456 over a 3000x3000 matrix is an average deviation of about 5e-5. In the double precision case, the average deviation is about 9e-13. In both cases that compares very favourably to the significand resolution of the types (and keeping in mind each entry is the result of an inner product consisting of 9 million flops).
As others have suggested, your error metric is really meaningless. The maximum absolute difference of the product matrices seems like a much better error metric to me.
I tweaked your code to have a more meaningful error metric. Here I’m looking at average ULP difference per operation. As expected, this difference is linear (and very low!).
Thanks for your kind response. I’ve actually posted the results for max. absolute difference as well - http://forums.nvidia.com/index.php?showtop…p;#entry1011729 : the shape of the curve looks pretty similar . I’m sorry if I haven’t made it clear in my earlier posts: I am trying to understand why the deviation between [GPUsingle, GPUdouble] is much higher than the [CPUsingle, CPUdouble] case. Kyle’s response (quoted in the above link) offers a good explanation that its because of single-precision FMAD instructions deviating from IEEE-754. I want to know what magnitude of deviations from the CPU version (by any error metric) we can expect in matrix multiplication because of this.