Please provide complete information as applicable to your setup.
• Hardware Platform (Jetson / GPU)
GPU Tesla T4
• DeepStream Version
5.1
• JetPack Version (valid for Jetson only)
• TensorRT Version
7.2.2-1
• NVIDIA GPU Driver Version (valid for GPU only)
470.82.01
• Issue Type( questions, new requirements, bugs)
Probably a Bug
So I tried to run inferece on a clients RTSP stream (3 RTSP sources) using the python deepstream-test3. The only change i did was replacing nveglglessink with fakesink. Everything worked fine but then I checked for memory usage using the following command
docker stats <Deepstream-container-name>
I observed that the memory utilzation kept on increasing.
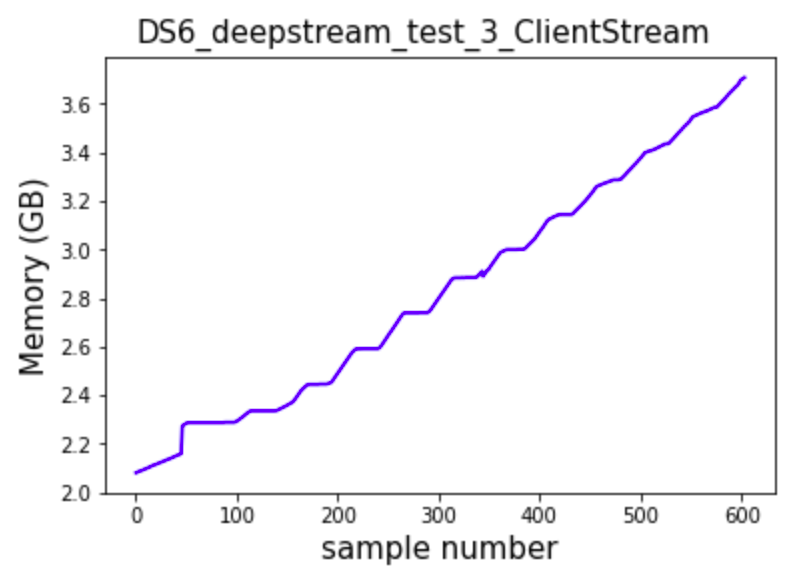
Upon taking logs of the memory utilization i was able to plot the below graph
Here every sample was taken every 5 seconds.
• How to reproduce the issue ? (This is for bugs. Including which sample app is using, the configuration files content, the command line used and other details for reproducing)
This can be reproduced with deepstream-test3 python app
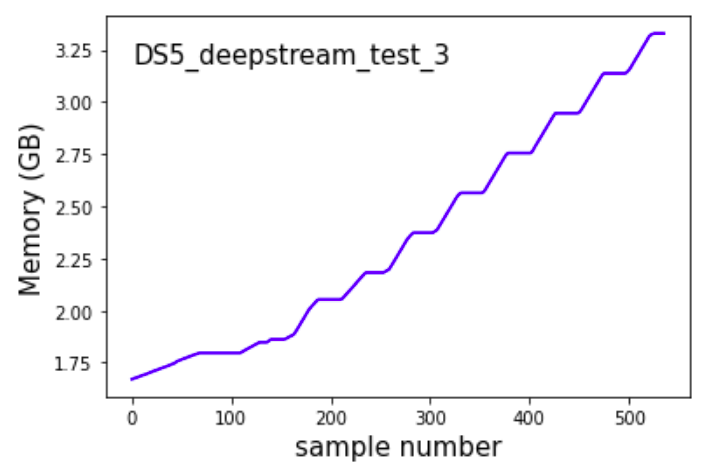
To ensure that this was not an issue related to the model taking up space over time or something to do with python failing in its garbage collection i tried implementing a simple pipeline using the gst-launch-1.0
gst-launch-1.0 \
uridecodebin uri=<RTSP_source1>! nvvideoconvert nvbuf-memory-type=3 ! "video/x-raw(memory:NVMM),format=RGBA" ! m.sink_0 \
uridecodebin uri=<RTSP_source2> ! nvvideoconvert nvbuf-memory-type=3 ! "video/x-raw(memory:NVMM),format=RGBA" ! m.sink_1 \
uridecodebin uri=<RTSP_source3> ! nvvideoconvert nvbuf-memory-type=3 ! "video/x-raw(memory:NVMM),format=RGBA" ! m.sink_2 \
nvstreammux name=m nvbuf-memory-type=3 width=1280 height=720 batch-size=3 sync-inputs=1 live-source=1 batched-push-timeout=100000 ! queue ! fakesink sync=0
Here was the observation

so clearly there is no issue with the model or python mismanaging the memory.
Further Observation :
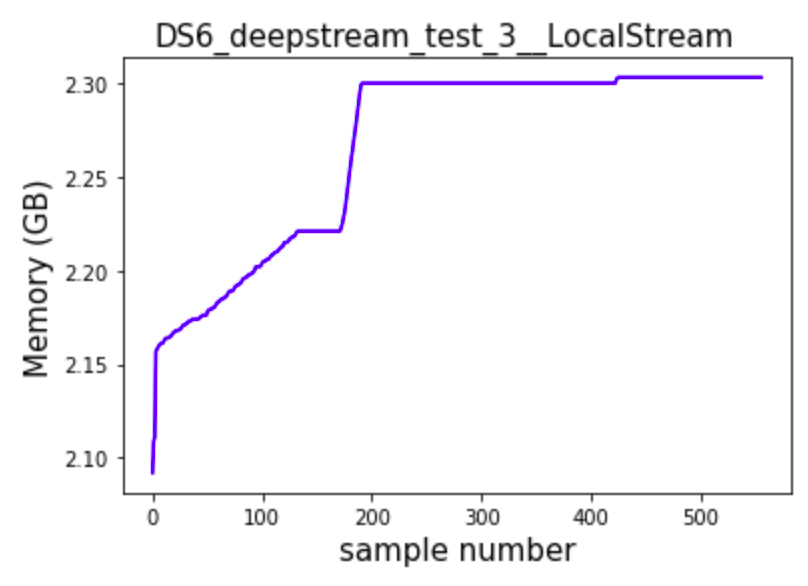
I later even tried seeing how the memory increases when running inference on an RTSP source from the local system using ffmpeg (called it synthetic test) . these were the observations


as can bee seen here there is signicficantly less memory leak compared to how it performed from the clients RTSP source.
Although there still is a small amount of memory leak.
The Question is how do i tackle this issue?
P.S.:- similar observations were made in Deepstream-6.0
• Requirement details( This is for new requirement. Including the module name-for which plugin or for which sample application, the function description)