Hey guys, just wondering about CUDA architecture… I was reading the larrabee paper and I saw somethings from it that made me realize a few things about CUDA, It’s kinda speculation, maybe it’s a known fact, but makes perfect sense…
Well first (I’ve been known to be quite naive) I thought something like “WOW! my 9800 GTX has 16 OCTACORES?? THAT’S WHY I CAN RUN 128 THREADS!?” then I started to mature the idea with several variations like “Maybe it’s something like Intel’s Hyperthreading? 16cores with 8 ALUs?” and so on, I didn’t get how the I could run 128 independent threads =p notice I’m very noob at CUDA programming but still I was more fascinated about the architecture than what it could do with it =p
After reading the larrabee’s paper I started to notice somethigns, they state that with their 16-wide (bytes) VPU (vector processing unit) they could run 4 threads per processor, I was like “No you can’t…unless you have aditional ALUs/Cores you can’t…AH! OF COURSE” well… I realized that they were talking about SIMD with the name THREAD… I learned x86 ASM by playing with the SSE instructions, for those who don’t know SSE is an instruction set to work with 128 bits (16bytes…) registers by operating on 4byte (32bits) parts of the registers so it’s like:
If you have
Register1 = 10,20,30,40
Register2 = 40,30,20,10
You can (in one instruction) add all 4 elements independently
Register = (10+40),(20+30),(30+20),(40+10)
So you can work with those registers in parallel doing whatever you want, if you have 4 pieces of data that you’ll have to do the exact same thing with (like 4 RGBA pixels of an image) you can do it in parallel
ADD register1,register2
SUB register1,register2
CMP register1,register2
MUL register1,register2
And so on…probably taking advantage of the previous architecture, AMD’s 3DNow! and Intel’s MMX use FPU’s registers (instead of creating new ones) so I’m pretty sure you won’t be able to run 4 threads using SSE registers on Larrabee =p
Well, in some parts of the cuda documentation you have somethings that don’t make much sense (if you had 128 processors) like why I can’t put 1 thread of a wrap in hold and wait for the others to complete? why the only way to sync threads is with a barrier? if a thread branches it’ll start to execute in serial, then when they all come back to the same place they’ll again work in parallel right? well, why’s that?
Then it came to me, well… what I have here is a 4 core multiprocessor working with LARGE SIMD registers… it makes sense doesn’t it? shaders/CUDAcode usually run the exact same thing, so it would be easy to just put a BIG SIMD register and process that in parallel
So you have a register that has a size = warpsize and you have a set of instructions to loop/test/add/sub/etc on each of the individual elements of this big SIMD register in parallel, it’s no big deal but look this classic image from cuda documentation:
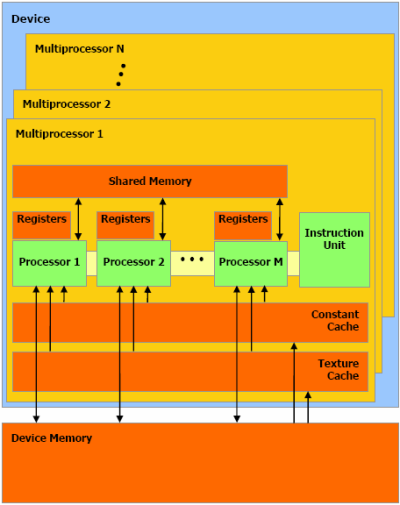
It says that you have MULTIPROCESSORS with PROCESSORS inside when actually I think you have (probably) a quad core (depending on the model) with big SIMD registers in place of the cores… that’s why you can only sync with barrier, that’s why you can’t branch keeping the parallelism and stuff like that, Larrabee will do the exact same thing (except that with more cores and smaller SIMD registers) so the idea of SIMT is actually an abstraction for SIMD. It’s a great architecture for sure, abstracting SIMD registers in threads is a BIG DEAL for us programmers, working with a (I dunno, 32warpsize*32bits registers/8bytes) 128bytes registers would be complicated without CUDA’s abstraction, I just think that it’s not what they state in the documentation
Well…that’s it! is this news? has anyone came up with a “theory” like that? It’s quite obvious I know but, I was quite “scared” when I came up with that =p
Thanks